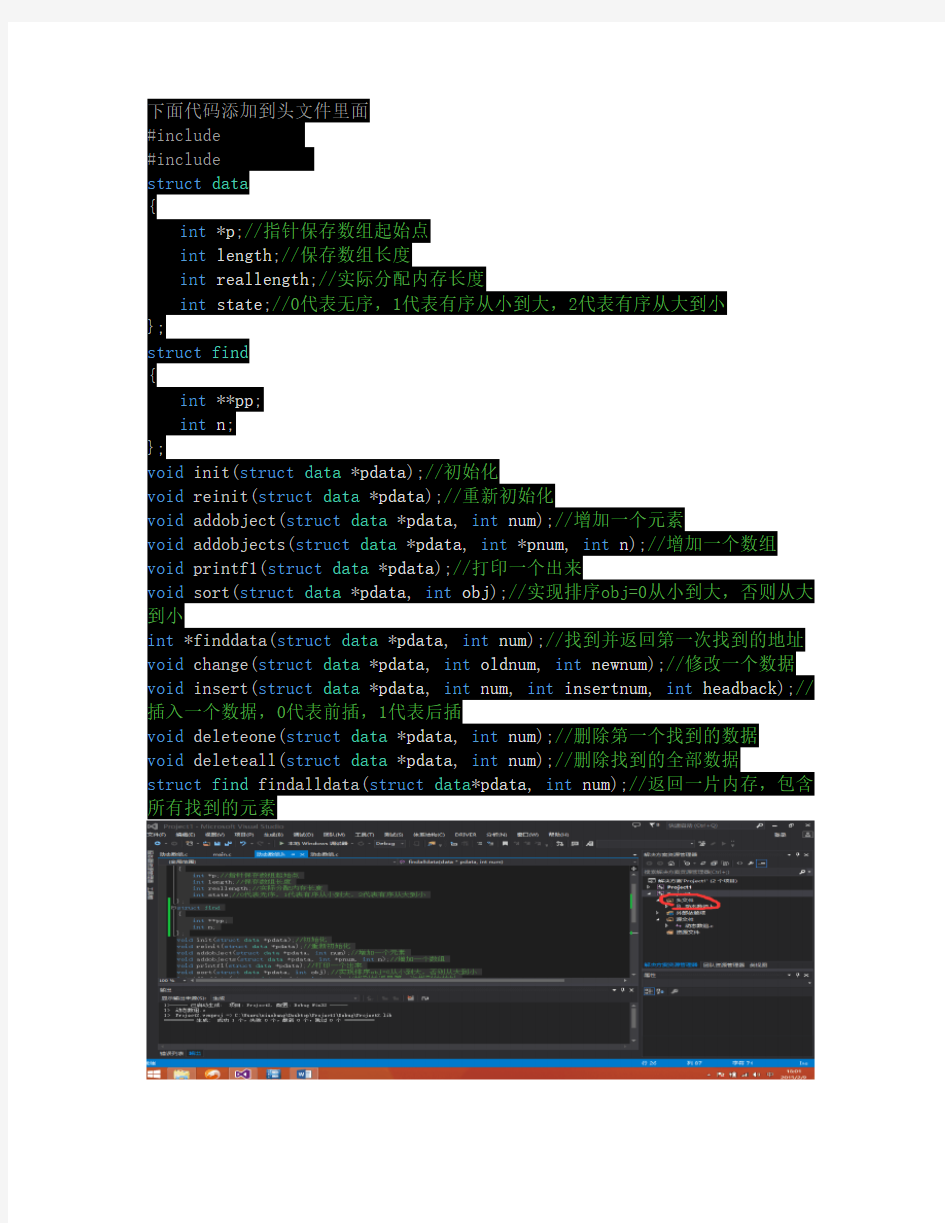

下面代码添加到头文件里面
#include
#include
struct data
{
int*p;//指针保存数组起始点
int length;//保存数组长度
int reallength;//实际分配内存长度
int state;//0代表无序,1代表有序从小到大,2代表有序从大到小
};
struct find
{
int**pp;
int n;
};
void init(struct data*pdata);//初始化
void reinit(struct data*pdata);//重新初始化
void addobject(struct data*pdata,int num);//增加一个元素
void addobjects(struct data*pdata,int*pnum,int n);//增加一个数组void printf1(struct data*pdata);//打印一个出来
void sort(struct data*pdata,int obj);//实现排序obj=0从小到大,否则从大到小
int*finddata(struct data*pdata,int num);//找到并返回第一次找到的地址void change(struct data*pdata,int oldnum,int newnum);//修改一个数据void insert(struct data*pdata,int num,int insertnum,int headback);//插入一个数据,0代表前插,1代表后插
void deleteone(struct data*pdata,int num);//删除第一个找到的数据
void deleteall(struct data*pdata,int num);//删除找到的全部数据
struct find findalldata(struct data*pdata,int num);//返回一片内存,包含所有找到的元素
添加到源文件中
#include
#include
#include"动态数组.h"
void init(struct data*pdata)
{
pdata->p=NULL;
pdata->length=0;
pdata->reallength=0;
pdata->state=0;
}
void reinit(struct data*pdata)
{
if(pdata->p==NULL)
{
return;
}
else
{
free(pdata->p);
pdata->p=NULL;
pdata->length=0;
pdata->reallength=0;
pdata->state=0;
}
}
void addobject(struct data*pdata,int num)
{
if(pdata->p==NULL)
{
pdata->p=(int*)malloc(sizeof(int));
*(pdata->p)=num;
pdata->length++;
pdata->reallength++;
}
else
{
if(pdata->length==pdata->reallength)
{
(pdata->length)++;
(pdata->reallength)++;
pdata->p=(int*)realloc(pdata->p,
(pdata->length)*sizeof(int));
pdata->p[pdata->length-1]=num;
}
else
{
(pdata->length)++;
pdata->p[pdata->length-1]=num;
}
}
}
void addobjects(struct data*pdata,int*pnum,int n)
{
if(pdata->p==NULL)
{
pdata->p=(int*)malloc(sizeof(int)*n);
for(int i=pdata->length;i
{
pdata->p[i]=pnum[i];
}
pdata->length+=n;
pdata->reallength+=n;
}
else
{
if(pdata->length+n<=pdata->reallength)
{
for(int i=pdata->length;i
{
pdata->p[i]=pnum[i-pdata->length];
}
(pdata->length)+=n;
}
else
{
pdata->p=(int*)realloc(pdata->p,(pdata->length+ n)*sizeof(int));
for(int i=pdata->length;i
{
pdata->p[i]=pnum[i-pdata->length];
}
(pdata->length)+=n;
(pdata->reallength)+=n;
}
}
}
void printf1(struct data*pdata)
{
if(pdata->p==NULL)
{
printf("打印失败\n");
}
else
{
for(int i=0;i
{
printf("%d\n",pdata->p[i]);
}
printf("动态数组长度为%d\n",pdata->length);
}
}
void sort(struct data*pdata,int obj)
{
if(obj==0)//从小到大
{
for(int i=0;i
{
for(int j=0;j
{
if(pdata->p[j]>pdata->p[j+1])
{
pdata->p[j]=pdata->p[j]^pdata->p[j+1];
pdata->p[j+1]=pdata->p[j]^pdata->p[j+1];
pdata->p[j]=pdata->p[j]^pdata->p[j+1];
}
}
}
pdata->state=1;
}
else//从小到大
{
for(int i=0;i
{
for(int j=0;j
{
if(pdata->p[j]
{
pdata->p[j]=pdata->p[j]^pdata->p[j+1];
pdata->p[j+1]=pdata->p[j]^pdata->p[j+1];
pdata->p[j]=pdata->p[j]^pdata->p[j+1];
}
}
}
pdata->state=2;
}
}
int*finddata(struct data*pdata,int num)
{
if(pdata->state==0)
{
for(int i=0;i
{
if(pdata->p[i]==num)
{
return&pdata->p[i];
break;
}
}
//printf("此数据不存在\n");
return NULL;
}
else if(pdata->state==1)
{
int low=0;
int high=pdata->length-1;
int mid=(low+high)/2;
while(low<=high)
{
if(pdata->p[mid]==num)
{
return&pdata->p[mid];
}
else if(pdata->p[mid]>num)
{
high=mid-1;
mid=(low+high)/2;
}
else
{
low=mid+1;
mid=(low+high)/2;
}
}
// printf("此数据不存在\n");
return NULL;
}
else
{
int low=0;
int high=pdata->length-1;
int mid=(low+high)/2;
while(low<=high)
{
if(pdata->p[mid]==num)
{
return&pdata->p[mid];
}
else if(pdata->p[mid]>num)
{
low=mid+1;
mid=(low+high)/2;
}
else
{
high=mid-1;
mid=(low+high)/2;
}
}
// printf("此数据不存在\n");
return NULL;
}
}
void change(struct data*pdata,int oldnum,int newnum)
{
int*p=finddata(pdata,oldnum);
if(p==NULL)
{
printf("查找失败,没有修改的这个数");
return;
}
else
{
*p=newnum;
}
}
void insert(struct data*pdata,int num,int insertnum,int headback) {
int*curposition=finddata(pdata,num);
if(curposition==NULL)
{
printf("查找失败,没有像插入的这个数");
return;
}
else
{
if(headback==0)
{
if(pdata->length==pdata->reallength)
{
int cur=curposition-pdata->p;
pdata->p=(int*)realloc(pdata->p,(pdata->length+ 1)*sizeof(int));
for(int i=pdata->length-1;i>=cur;i--)
{
pdata->p[i+1]=pdata->p[i];
}
pdata->p[cur]=insertnum;
pdata->length++;
pdata->reallength++;
}
else
{
int cur=curposition-pdata->p;
for(int i=pdata->length-1;i>=cur;i--)
{
pdata->p[i+1]=pdata->p[i];
}
pdata->p[cur]=insertnum;
pdata->length++;
}
}
else//后面插入
{
if(pdata->length==pdata->reallength)
{
int cur=curposition-pdata->p;
pdata->p=(int*)realloc(pdata->p,(pdata->length+ 1)*sizeof(int));
for(int i=pdata->length-1;i>cur;i--)
{
pdata->p[i+1]=pdata->p[i];
}
pdata->p[cur+1]=insertnum;
pdata->length++;
pdata->reallength++;
}
else
{
int cur=curposition-pdata->p;
for(int i=pdata->length-1;i>cur;i--)
{
pdata->p[i+1]=pdata->p[i];
}
pdata->p[cur+1]=insertnum;
pdata->length++;
}
}
}
}
void deleteone(struct data*pdata,int num)
{
if(pdata->p==NULL)
{
printf("删除失败\n");
return;
}
else
{
int*curposition=finddata(pdata,num);
int cur=curposition-pdata->p;
for(int i=cur;i
{
pdata->p[i]=pdata->p[i+1];
}
pdata->length-=1;
}
}
void deleteall(struct data*pdata,int num)
{
if(pdata->p==NULL)
{
printf("删除失败\n");
return;
}
else
{
while(finddata(pdata,num))
{
deleteone(pdata,num);
}
}
}
int*find(int*p,int num,int n)
{
for(int i=0;i { if(p[i]==num) { return p+i; break; } } return NULL; } struct find findalldata(struct data*pdata,int num) { struct find resn; if(pdata->p==NULL) { printf("查找失败\n"); resn.n=0; resn.pp=NULL; return resn; } else { int tem=0; for(int*pp=find(pdata->p,num,pdata->length);pp!=NULL;pp= find(pp+1,num,pdata->length-(pp-pdata->p))) { tem++; } resn.n=tem; int**p1=(int*)malloc(sizeof(int*)*tem); resn.pp=p1; for(int*pp=find(pdata->p,num,pdata->length),j=0;pp!=NULL; j++,pp=find(pp+1,num,pdata->length-(pp-pdata->p))) { p1[j]=pp; //printf("%p,%d\n", p1[j], *p1[j]); } return resn; } } 一个程序本质上都是由BSS 段、data段、text段三个组成的。这种概念在当前的计算机程序设计中是非常重要的一个基本概念,并且在嵌入式系统的设计中也非常重要,牵涉到嵌入式系统执行时的内存大小分配,存储单元占用空间大小的问题。 ●BSS段:在採用段式内存管理的架构中。BSS段(bss segment)一般是指用 来存放程序中未初始化的全局变量的一块内存区域。 BSS是英文Block Started by Symbol的简称。 BSS段属于静态内存分配。 ●数据段:在採用段式内存管理的架构中,数据段(data segment)一般是指 用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。 ●代码段:在採用段式内存管理的架构中,代码段(text segment)一般是指 用来存放程序执行代码的一块内存区域。这部分区域的大小在程序执行前就已经确定,而且内存区域属于仅仅读。 在代码段中。也有可能包括一些仅仅读的常数变量,比如字符串常量等。 程序编译后生成的目标文件至少含有这三个段。这三个段的大致结构图例如以下所看到的: 当中.text即为代码段,为仅仅读。.bss段包括程序中未初始化的全局变量和static变量。 data段包括三个部分:heap(堆)、stack(栈)和静态数据区。 ●堆(heap):堆是用于存放进程执行中被动态分配的内存段。它的大小并不 固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时。新分配的内存就被动态加入到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减) 栈(stack):栈又称堆栈,是用户存放程序暂时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包含static声明的变量。static意味着在数据段中存放变量)。 除此以外,在函数被调用时。其參数也会被压入发起调用的进程栈中。而且待到调用结束后。函数的返回值也会被存放回栈中。 因为栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们能够把堆栈看成一个寄存、交换暂时数据的内存区。 当程序在运行时动态分配空间(C中的malloc函数),所分配的空间就属于heap。其概念与数据结构中“堆”的概念不同。 stack段存放函数内部的变量、參数和返回地址,其在函数被调用时自己主动分配。訪问方式就是标准栈中的LIFO方式。 (由于函数的局部变量存放在此,因此其訪问方式应该是栈指针加偏移的方式,否则若通过push、pop操作来訪问相当麻烦) data段中的静态数据区存放的是程序中已初始化的全局变量、静态变量和常量。 在採用段式内存管理的架构中(比方intel的80x86系统),BSS 段(Block Started by Symbol segment)一般是指用来存放程序中未初始化的全局变量的一块内存区域,一般在初始化时BSS 段部分将会清零。BSS 段属于静态内存分配。即程序一開始就将其清零了。 比方,在C语言之类的程序编译完毕之后,已初始化的全局变量保存在.data 段中,未初始化的全局变量保存在.bss 段中。 text和data段都在可运行文件里(在嵌入式系统里通常是固化在镜像文件里)。由系统从可运行文件里载入;而BSS段不在可运行文件里,由系统初始化。 c语言中动态内存申请与释放的简单理解 在C里,内存管理是通过专门的函数来实现的。与c++不同,在c++中是通过new、delete函数动态申请、释放内存的。 1、分配内存 malloc 函数 需要包含头文件: #include 实验报告 实验课程名称:动态内存分配算法 年12月1日 实验报告 一、实验内容与要求 动态分区分配又称为可变分区分配,它是根据进程的实际需要,动态地为之分配内存空间。在实验中运用了三种基于顺序搜索的动态分区分配算法,分别是1.首次适应算法2.循环首次适应算法3.最佳适应法3.最坏适应法分配主存空间。 二、需求分析 本次实验通过C语言进行编程并调试、运行,显示出动态分区的分配方式,直观的展示了首次适应算法循环首次适应算法、最佳适应算法和最坏适应算法对内存的释放和回收方式之间的区别。 首次适应算法 要求空闲分区链以地址递增的次序链接,在分配内存时,从链首开始顺序查找,直至找到一个大小能满足要求的空闲分区为止,然后在按照作业的大小,从该分区中划出一块内存空间,分配给请求者,余下的空余分区仍留在空链中。 优点:优先利用内存中低址部分的空闲分区,从而保留了高址部分的大空闲区,为以后到达的大作业分配大的内存空间创造了条件。 缺点:低址部分不断被划分,会留下许多难以利用的、很小的空闲分区即碎片。而每次查找又都是从低址部分开始的,这无疑又会增加查找可用空闲分区时的开销。 循环首次适应算法 在为进程分配内存空间时,不是每次都从链首开始查找,而是从上次找到的空闲分区的下一个空闲分区开始查找,直到找到一个能满足要求的空闲分区。 优点:该算法能使内存中的空闲分区分布得更均匀,从而减少了查找空闲分区时的开销。 最佳适应算法 该算法总是把能满足要求、又是最小的空闲分区分配给作业,避免大材小用,该算法要求将所有的空闲分区按其容量以从小到大的顺序形成一空闲分区链。 缺点:每次分配后所切割下来的剩余部分总是最小的,这样,在存储器中会留下许多难以利用的碎片。 最坏适应算法 最坏适应算法选择空闲分区的策略正好与最佳适应算法相反:它在扫描整个空闲分区或链表时,总会挑选一个最大的空闲区,从中切割一部分存储空间给作业使用。该算法要求,将所有的空闲分区,按其容量以大到小的顺序形成一空闲分区链。查找时,只要看第一个分区能否满足作业要求即可。 优点:可使剩下的空闲区不至于太小,产生碎片的可能性最小,对中小作业有利,同时,最坏适应算法查找效率很高。 缺点:导致存储器中缺乏大的空闲分区 三、数据结构 为了实现动态分区分配算法,系统中配置了相应的数据结构,用以描述空闲分区和已分配分区的情况,常用的数据结构有空闲分区表和空闲分区链 流程图 1.内存分配方式 内存分配方式有三种: [1]从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。 [2]在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。 [3]从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由程序员决定,使用非常灵活,但如果在堆上分配了空间,就有责任回收它,否则运行的程序会出现内存泄漏,频繁地分配和释放不同大小的堆空间将会产生堆内碎块。 2.程序的内存空间 一个程序将操作系统分配给其运行的内存块分为4个区域,如下图所示。 一个由C/C++编译的程序占用的内存分为以下几个部分, 1、栈区(stack)— 由编译器自动分配释放,存放为运行函数而分配的局部变量、函数参数、返回数据、返回地址等。其操作方式类似于数据结构中的栈。 2、堆区(heap) — 一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。分配方式类似于链表。 3、全局区(静态区)(static)—存放全局变量、静态数据、常量。程序结束后由系统释放。 4、文字常量区—常量字符串就是放在这里的。程序结束后由系统释放。 5、程序代码区—存放函数体(类成员函数和全局函数)的二进制代码。 下面给出例子程序, int a = 0; //全局初始化区 char *p1; //全局未初始化区 int main() { int b; //栈 char s[] = "abc"; //栈 char *p2; //栈 char *p3 = "123456"; //123456在常量区,p3在栈上。 static int c =0;//全局(静态)初始化区 C语言编程要点---指针和内存分配上-Read C语言编程要点---第7章指针和内存分配(上) 指针和内存分配 指针为C语言编程提供了强大的支持——如果你能正确而灵活地利用指针,你就可以直接切入问题的核心,或者将程序分割成一个个片断。一个很好地利用了指针的程序会非常高效、简洁和精致。 利用指针你可以将数据写入内存中的任意位置,但是,一旦你的程序中有一个野指针("wild”pointer),即指向一个错误位置的指针,你的数据就危险了——存放在堆中的数据可能会被破坏,用来管理堆的数据结构也可能会被破坏,甚至操作系统的数据也可能会被修改,有时,上述三种破坏情况会同时发生。 此后可能发生的事情取决于这样两点:第一,内存中的数据被破坏的程度有多大;第二,内存中的被破坏的部分还要被使用多少次。在有些情况下,一些函数(可能是内存分配函数、自定义函数或标准库函数)将立即(也可能稍晚一点)无法正常工作。在另外一些情况下,程序可能会终止运行并报告一条出错消息;或者程序可能会挂起;或者程序可能会陷入死循环;或者程序可能会产生错误的结果;或者程序看上去仍在正常运行,因为程序没有遭到本质的破坏。 值得注意的是,即使程序中已经发生了根本性的错误,程序有可能还会运行很长一段时间,然后才有明显的失常表现;或者,在调试时,程序的运行完全正常,只有在用户使用时,它才会失常。 在C语言程序中,任何野指针或越界的数组下标(out-of-bounds array subscript)都可能使系统崩溃。两次释放内存的操作也会导致这种结果。你可能见过一些C程序员编写的程序中有严重的错误,现在你能知道其中的部分原因了。 有些内存分配工具能帮助你发现内存分配中存在的问题,例如漏洞(leak,见7.21),两次释放一个指针,野指针,越界下标,等等。但这些工具都是不通用的,它们只能在特定的操作系统中使用,甚至只能在特定版本的编译程序中使用。如果你找到了这样一种工具,最好试试看能不能用,因为它能为你节省许多时间,并能提高你的软件的质量。 指针的算术运算是C语言(以及它的衍生体,例如C++)独有的功能。汇编语言允许你对地址进行运算,但这种运算不涉及数据类型。大多数高级语言根本就不允许你对指针进行任何操作,你只能看一看指针指向哪里。 C指针的算术运算类似于街道地址的运算。假设你生活在一个城市中,那里的每一个街区的所有街道都有地址。街道的一侧用连续的偶数作为地址,另一侧用连续的奇数作为地址。如果你想知道River Rd.街道158号北边第5家的地址,你不会把158和5相加,去找163号;你会先将5(你要往前数5家)乘以2(每家之间的地址间距),再和158相加,去找River Rd.街道的168号。同样,如果一个指针指向地址158(十进制数)中的一个两字节短整型值,将该指针加3=5,结 果将是一个指向地址168(十进制数)中的短整型值的指针(见7.7和7.8中对指针加减运算的详细描述)。街道地址的运算只能在一个特定的街区中进行,同样,指针的算术运算也只能在一个特定的数组中进行。实际上,这并不是一种限制,因为指针的算术运算只有在一个特定的数组中进行才有意义。对指针的算术运算来说,一个数组并不必须是一个数组变量,例如函数malloc()或calloc()的返回值是一个指针,它指向一个在堆中申请到的数组。 指针的说明看起来有些使人感到费解,请看下例: char *p; 上例中的说明表示,p是一个字符。符号“*”是指针运算符,也称间接引用运算符。当程序间接引用一个指针时,实际上是引用指针所指向的数据。 在大多数计算机中,指针只有一种,但在有些计算机中,指向数据和指向函数的指针可以是不同的,或者指向字节(如char。指针和void *指针)和指向字的指针可以是不同的。这一点对sizeof运算符没有什么影响。但是,有些C程序或程序员认为任何指针都会被存为一个int型的值,或者至少会被存为一个long 型的值,这就无法保证了,尤其是在IBM PC兼容机上。 我讲解一下c语言中动态分配内存的函数,可能有些初学c语言的 人不免要问了:我们为什么要通过函数来实现动态分配内存呢?系统难道不是会自动分配内存吗?? 既然有人会问这样的问题,那么我在这里好好的讲解一下吧! 首先让我们熟悉一下计算机的内存吧!在计算机的系统中有四个内存区域:1)栈:在栈里面储存一些我们定义的局部变量以及形参(形式参数);2)字符常量区:主要是储存一些字符常量,比如:char *p_str=”cgat”;其中”cgat”就储存在字符常量区里面;3)全局区:在全局区里储存一些全局变量和静态变量;4)堆:堆主要是通过动态分配的储存空间,也就是我们接下需要讲的动态分配内存空间。 什么时候我们需要动态分配内存空间呢?举一个例子吧。int *p;我们定义了一个指向int类型的指针p;p是用来储存一个地址的值的,我们之所以要为p 这个变量分配空间是让它有一个明确的指向,打个比方吧!你现在做好了一个指向方向的路标,但是你并没有让这个路标指向一个确切的方位,也就是说现在的这个路标是瞎指向的,这样我们就不能够通过它来明确到底哪里是东,哪里是西,何为北,何为南了。虽然我们在计算机的内存里定义了一个指针变量,但是我们并没有让这个变量指示一个确切int类型变量的地址,所以我们就必须要让它有一个明确的指示方向。这样我们就要通过动态分配内存的方式来认为的规定它的方向! 我们在刚刚接触指针的时候遇到过这样的情况,int *p;p=&a;这种方法不是指针的动态分配内存,这个叫做指针变量的初始化!初始化同样也可以让指针变量有方向可指。 int *p;p=malloc(n*sizeof(类型名称));我们通过malloc()函数为一个指针变量p分配了地址,这样我们从键盘上键入的值就这样存储在p里面了,接下来我们就可以对这个p进行具体的操作了,比如scanf(“%s”,p)等等。当我们对p结束操作的时候还要释放p的内存空间。为什么要释放内存空间呢?在上面我已经讲过动态分配的变量时储存在堆里面,但是这个堆的空间并不是无限大的,也许当我们编一个小的程序的时候可能我们并不能够发现什么,但是对于那些大的程序,如果我们比及时释放堆的空间的时候会放生内存泄露。所谓内存泄露是因为堆的空间北我们动态分配用完了,这样当我们再去使用动态分配堆的空间的时候就没有足够的空间让我们使用了,这样就需要占有原来的空间,也就是会把其他的空间来储存我们键入的值,这样会导致原来储存的数据被破坏掉,导致了内存的泄露了。 同时当我们使用malloc()函数的时候还应该注意当我们释放完空间的时候还要将原先的指针变量赋予一个NULL,也就是赋予一个空指针,留着下次的时候使用它!如果我们不赋予|NULL行不行呢??答案是:不行的!如果我们不赋予一个空指针这样会导致原先的指针变量成为了一个野指针!何谓野指针?野指针就是一个没有明确指向的指针,系统不知道它会指向什么地方,野指针是很危险的,因此当我们每次使用完malloc()函数的时候都必须将指针赋予一个空指针!相对于malloc()函数,calloc()函数就不需要我们赋予NULL了,这是因为在每次调用完calloc()函数的时候系统会自动将原先的指针赋予一个空指 在C中动态分配内存的,对于单个变量,字符串,一维数组等,都是很容易的。C中动态分配二维数组的方法,很少有C语言书中描述,我查找了有的C语言书中提到了一个方法: 假定二维数组的维数为[M][N] 分配是可以这样: int **ptr=new int*[M]; //////这是先动态分配一个包含有M个指针的数组,即指先分配一个针数组 ///////////指针数组的首地址保存在ptr中 for(int i=0;i { pMatrix[i] = new int[column]; for(int j = 0; j < column; j++) { pMatrix[i][j] = (i+j); ///////简单的初始化 } } 这样创建一个数组有个严重的问题,就是它的内存不连续,行与行之间的内存不连续,虽然可以用[i][j]下标访问,无法满足用指向二维数组元素型别的指针变量来访问整个数组的要求. 例如不能如下访问每个二维数组元素: int * p = NULL; for(p = pMatrix[0]; p < pMatrix[0]+column * row; p++) { int fff = *(pme); } 而这种访问方式对于真正的二维数组是完全可以的。出现这种原因就是因为行与行之间的内存不连续造成的。 所以,这中方式创建的动态二维数组,不是真正意义上的二维数组。 那么什么是真正的二维数组呢?C语言中的二维数组在内存组织形式是按行存储的连续的内存区域。所以,必须保证数组元素是按行存储的,而且也是最重要的是内存要连续。 所以,我写出了如下的一个方法: 假定二维数组的元素变量类型是MyType;可以是C语言接受的除void之外的任何类型,因为编译器不晓得void类型的大小;例如int,float,double等等类型; int row = 2; /////暂假定行数是2,这个可以在运行时刻决定; int column = 3;/////暂假定列数是2,这个可以在运行时刻决定; void **ptdhead = NULL; //////////在后面说明为什么要用void**类型 C语言变量声明及内存分配 一个由c/C++编译的程序占用的内存分为以下几个部分 1、栈区(stack)—程序运行时由编译器自动分配,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。程序结束时由编译器自动释放。 2、堆区(heap)—在内存开辟另一块存储区域。一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。 3、全局区(静态区)(static)—编译器编译时即分配内存。全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域(BSS)。- 程序结束后由系统释放 4、文字常量区—常量字符串就是放在这里的,程序结束后由系统释放。 5、程序代码区—存放函数体的二进制代码。 例子程序 这是一个前辈写的,非常详细 #include //main.cpp int a = 0; //全局初始化区 char *p1; //全局未初始化区 void main() { int b=1; // 栈 char s[] = "abc"; //栈 char *p2; //栈 char *p3 = "123456"; //"123456\0"在常量区,p3在栈上。static int c =0; //全局(静态)初始化区 p1 = (char *)malloc(10); p2 = (char *)malloc(20); //分配得来得10和20字节的区域就在堆区。 strcpy(p1, "123456"); //123456\0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方 system("pause"); C语言变量声明内存分配(转) 一个由c/C++编译的程序占用的内存分为以下几个部分 1、栈区(stack)—程序运行时由编译器自动分配,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。程序结束时由编译器自动释放。 2、堆区(heap)—在内存开辟另一块存储区域。一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。 3、全局区(静态区)(static)—编译器编译时即分配内存。全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。- 程序结束后由系统释放 4、文字常量区—常量字符串就是放在这里的。程序结束后由系统释放 5、程序代码区—存放函数体的二进制代码。 例子程序 这是一个前辈写的,非常详细 //main.cpp int a = 0; 全局初始化区 char *p1; 全局未初始化区 main() { int b;// 栈 char s[] = "abc"; //栈 char *p2; //栈 char *p3 = "123456"; //"123456\0"在常量区,p3在栈上。 static int c =0;//全局(静态)初始化区 p1 = (char *)malloc(10); p2 = (char *)malloc(20); //分配得来得10和20字节的区域就在堆区。 strcpy(p1, "123456"); //123456\0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。 } =============== C语言程序的内存分配方式 1.内存分配方式 内存分配方式有三种: [1]从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。 [2]在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。 [3]从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由程序员决定,使用非常灵活,但如果在堆上分配了空间,就有责任回收它,否则运行的程序会出现内存泄漏,频繁地分配和释放不同大小的堆空间将会产生堆内碎块。 2.程序的内存空间 一个程序将操作系统分配给其运行的内存块分为4个区域,如下图所示。 一个由C/C++编译的程序占用的内存分为以下几个部分, 1、栈区(stack)—由编译器自动分配释放,存放为运行函数而分配的局部变量、函数参数、返回数据、返回地址等。其操作方式类似于数据结构中的栈。 2、堆区(heap)—一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。分配方式类似于链表。 3、全局区(静态区)(static)—存放全局变量、静态数据、常量。程序结束后由系统释放。 4、文字常量区—常量字符串就是放在这里的。程序结束后由系统释放。 5、程序代码区—存放函数体(类成员函数和全局函数)的二进制代码。 下面给出例子程序, int a = 0; //全局初始化区 char *p1; //全局未初始化区 int main() { int b; //栈 char s[] = "abc"; //栈 char *p2; //栈 char *p3 = "123456"; //123456在常量区,p3在栈上。 static int c =0;//全局(静态)初始化区 p1 = new char[10]; p2 = new char[20]; //分配得来得和字节的区域就在堆区。 strcpy(p1, "123456"); //123456放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。 C语言程序编译的内存分配: 1.栈区(stack) --编译器自动分配释放,主要存放函数的参数值,局部变量值等; 2.堆区(heap) --由程序员分配释放; 3.全局区或静态区 --存放全局变量和静态变量;程序结束时由系统释放,分为全局初始化区和全局未初始化区; 4.字符常量区 --常量字符串放与此,程序结束时由系统释放; 5.程序代码区--存放函数体的二进制代码 例: //main.c int a=0; //全局初始化区 char *p1; //全局未初始化区 void main() { int b; //栈 char s[]="bb"; //栈 char *p2; //栈 char *p3="123"; //其中,“123\0”常量区,p3在栈区 static int c=0; //全局区 p1=(char*)malloc(10); //10个字节区域在堆区 strcpy(p1,"123"); //"123\0"在常量区,编译器可能会优化为和p3的指向同一块区域 } 一个C程序占用的内存可分为以下几类: (一) 栈 这是由编译器自动分配和释放的区域。主要存储函数的参数,函数的局部变量等。当一个函数开始执行时,该函数所需的实参,局部变量就推入栈中,该函数执行完毕后,之前进入栈中的参数和变量等也都出栈被释放掉。它的运行方式类似于数据结构中的栈。 (二) 堆 这是由程序员控制分配和释放的区域,在C里,用malloc()函数分配的空间就存在于堆上。在堆上分配的空间不像栈一样在某个函数执行完毕就自动释放,而是一直存在于整个程序的运行期间。当然,如果你不手动释放(free()函数)这些空间,在程序运行结束后系统也会将之自动释放。对于小程序来说可能感觉不到影响的存在,但对于大程序,例如一个大型游戏,就会遇到内存不够用的问题了(三) 全局区 C里的全局变量和静态变量存储在全局区。它们有点像堆上的空间,也是持续存在于程序的整个运行期间,但不同的是,他们是由编译器自己控制分配和释放的。 (四) 文字常量区 例如char *c = “123456”;则”123456”为文字常量,存放于文字常量区。也由编译器控制分配和释放。 C语言的内存分配机制 说到C语言的内存分配机制我们就不得不说到C语言的变量和函数定义时必须具有的两个属性:类型和存储类别。类型很简单就是int、float等,存储类别就是指的数据在内存中的存储方式,包括静态存储和动态存储两大类。其中动态存储包括auto、register两种类型,而静态存储就是我们熟悉的static和ertern两种。具体这四种类型的介绍呢我会在下一篇博文中写到。 如上图,一个C语言程序在内存中表示为这四块空间区域,为什么代码区和数据区会分开呢,这是因为我们现代计算机采用的是哈佛体系,哈佛体系的优点有一条就是将程序和数据分开存储,程序存储器和数据存储器是两个独立的存储器,每个存储器独立编址、独立访问。与两个存储器相对应的是系统的4条总线:程序的数据总线与地址总线,数据的数据总线与地址总线。这种分离的程序总线和数据总线允许在一个机器周期内同时获得指令字(来自程序存储器)和操作数(来自数据存储器),从而提高了执行速度。 我们再说这四个存储区域: 代码区存放的是程序的执行代码,就是一块一块的函数块代码,它是由函数的定义块编译得到的。 全局数据区呢,存放的是函数中定义的全局变量、常量、静态全局量和动态全局量,程序结束后由系统释放。 堆中存放的是程序的动态数据,它存放动态内存,供程序堆积申请使用。如new/delete、malloc/free,在堆上申请的内存程序员要自己回收,若程序员不释放该内存,可能在程序结束时OS回收,由于动态内存的生命期由程序员自己决定,所以它的灵活性较高。 栈中存放的是函数数据区,就是局部变量区,存放为函数运行所分配的局部变量、函数参数、返回值、返回地址。函数结束时这些内存空间将被自动释放。它的运行机制类似于数据结构中的栈。C/C++的函数调用过程就是栈空间的操作过程,过程如下: 1.建立栈空间 2.保护返回地址和函数运行状态 3.传递参数 4.将控制权交给被调函数 5.恢复调用调用函数运行状态 6.释放栈空间 7.根据返回地址,回到调用函数C语言的代码内存布局具体解释
c语言中动态内存申请与释放的简单理解
动态内存分配(C语言)
C语言程序的内存分配方式
C语言编程要点---指针和内存分配上-Read
我讲解一下c语言中动态分配内存的函数 (2)
C语言中动态分配二维数组
C语言内存分配
C语言变量声明内存分配
C语言内存管理
C语言的内存分配机制
相关主题
文本预览