
实验2 离散数据拟合模型
一、实验名称:离散数据拟合模型.
二、实验目的:掌握离散数据拟合模型的建模方法,并会利用Matlab 作数据拟合、数值计算与误差分析.
三、实验题目:已知美国人口统计数据如表,完成下列数据的拟合问题: (单位:百万)
年份 1790 1800 1810 1820 1830 1840 1850 1860 1870 1880 1890 人口/ 1900 1910 1920 1930 1940 1950 1960 1970 1980 1990 2000 人口/
76.0 92.0 106.5 123.2
131.7
150.7 179.3 204.0 226.5 251.4 281.4
四、实验要求:
1、如果用指数增长模型0()0()e r t t x t x -=模拟美国人口1790年至2000年的变化过程,请用Matlab 统计工具箱的函数nlinfit 计算指数增长模型的以下三个数据拟合问题: (1)取定x 0=3.9, t 0=1790,拟合待定参数r ;
源程序: clear
p=@(r,t)3.9.*exp(r.*(t-1790)); t=1790:10:2000;
c=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.0,92.0,106.5,123.2,131.7,150.7,179.3,204.0,226.5,251.4,281.4]; r=nlinfit(t,c,p,0.0359) sse=sum((c-p(r,t)).^2)
plot(t,c,'r*',1790:1:2000,p(r,1790:1:2000),'r') axis([1790,2000,0,290])
xlabel('年份'),ylabel('人口(单位:百万)') title('拟合美国人口数据—指数增长型') legend('拟合数据')
调试结果:r =0.0212 sse =1.7418e+004
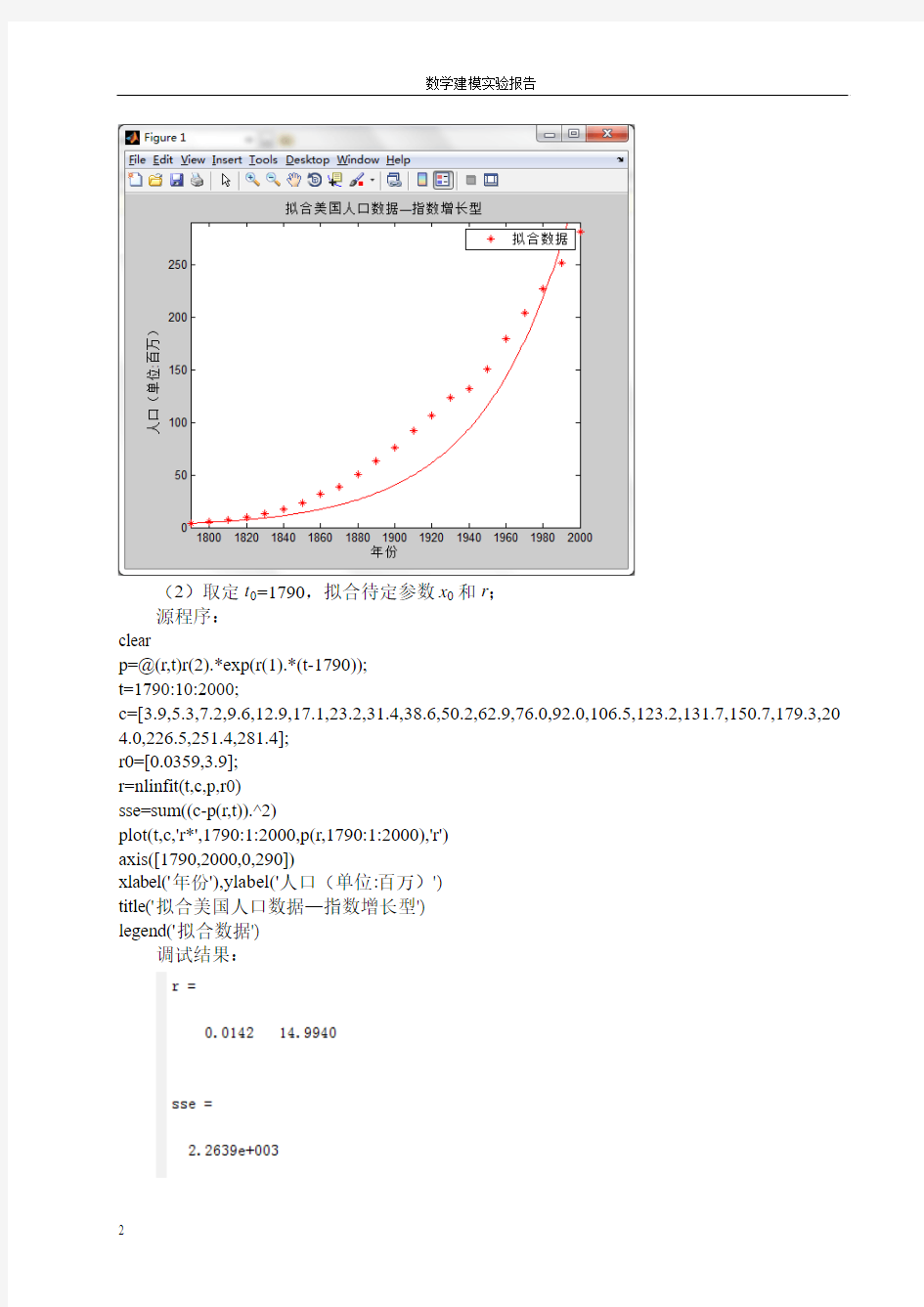
(2)取定t0=1790,拟合待定参数x0和r;
源程序:
clear
p=@(r,t)r(2).*exp(r(1).*(t-1790));
t=1790:10:2000;
c=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.0,92.0,106.5,123.2,131.7,150.7,179.3,20 4.0,226.5,251.4,281.4];
r0=[0.0359,3.9];
r=nlinfit(t,c,p,r0)
sse=sum((c-p(r,t)).^2)
plot(t,c,'r*',1790:1:2000,p(r,1790:1:2000),'r')
axis([1790,2000,0,290])
xlabel('年份'),ylabel('人口(单位:百万)')
title('拟合美国人口数据—指数增长型')
legend('拟合数据')
调试结果:
(3)拟合待定参数t0, x0和r.要求写出程序,给出拟合参数和误差平方和的计算结果,并展示误差平方和最小的拟合效果图.
源程序:
clear
p=@(r,t)r(2).*exp(r(1).*(t-1790+1.*r(3)));
t=1790:10:2000;
c=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.0,92.0,106.5,123.2,131.7,150.7,179.3,20 4.0,226.5,251.4,281.4];
r0=[0.0359,3.9,1];
[r,x]=nlinfit(t,c,p,r0)
sse=sum((c-p(r,t)).^2)
a=1790+1.*r(3)
subplot(2,1,1)
plot(t,c,'r*',1790:1:2000,p(r,1790:1:2000),'r')
axis([1790,2000,0,290])
xlabel('年份'),ylabel('人口(单位:百万)')
title('拟合美国人口数据—指数增长型')
legend('拟合数据')
subplot(2,1,2)
plot(t,x,'k+',[1790,2000],[0,0],'k')
axis([1790,2000,-20,20])
xlabel('年份'),ylabel('误差')
title('拟合误差')
调试结果:
2、通过变量替换,可以将属于非线性模型的指数增长模型转化成线性模型,并用Matlab 函数polyfit进行计算,请说明转化成线性模型的详细过程,然后写出程序,给出拟合参数和误差平方和的计算结果,并展示拟合效果图.
解题思路:
将属于非线性模型的指数增长模型转化成线性模型,即对函数式两边求导:ln[x(t)]=ln[x(0)]+r*[t-t(0)],最后变成一次函数形式:Y=rX+b,即令ln[x(t)]=Y, ln[x(0)]=b,[t-t(0)]=X.
源程序:
clear
t=1790:10:2000;
c=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.0,92.0,106.5,123.2,131.7,150.7,179.3,20 4.0,226.5,251.4,281.4];
[p,s]=polyfit(t-1790,log(c),1)
b1=p(1)
b2=exp(p(2))
subplot(2,1,1)
plot(t,c,'r*',t,exp(polyval(p,t-1790)),'r')
axis([1790,2000,0,290])
xlabel('年份'),ylabel('人口(单位:百万)')
title('拟合美国人口数据—指数增长型')
legend('拟合数据')
c1=(c-exp(polyval(p,t-1790))).^2
c2=sum(c1)
subplot(2,1,2)
plot(t,c1,'k+',[1790,2000],[0,0],'k')
axis([1790,2000,-20,20])
xlabel('年份'),ylabel('误差')
title('拟合误差')
调试结果:
3、请分析指数增长模型非线性拟合和线性化拟合的结果有何区别?原因是什么?
答:如下图:可以看出非线性拟合线性比较均匀、平滑,误差平方和的个数较多,误差相比较而言较小;而线性拟合线性不均匀,有很大的断点,误差平方和的个数也相比较而言较少,并且,误差随着人口数的增长而增长。
非线性拟合
线性拟合
4、如果用阻滞增长模型00
()
00()()e r t t Nx x t x N x --=
+-模拟美国人口1790年至2000年的变
化过程,请用Matlab 统计工具箱的函数nlinfit 计算阻滞增长的以下三个数据拟合问题:
(1)取定x 0=3.9, t 0=1790,拟合待定参数r 和N ; 源程序: clear
p=@(a,t)(a(2).*3.9)./(3.9+(a(2)-3.9).*exp(-a(1).*(t-1790))); t=1790:10:2000;
c=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.0,92.0,106.5,123.2,131.7,150.7,179.3,204.0,226.5,251.4,281.4]; a=nlinfit(t,c,p,[0.03,350]) sse=sum((c-p(a,t)).^2) plot(t,c,'r*',t,p(a,t),'r') axis([1790,2000,0,300])
xlabel('年份'),ylabel('人口(单位:百万)') title('拟合美国人口数据—阻滞增长型') legend('拟合数据') 调试结果:
(2)取定t 0=1790, 拟合待定参数x 0, r 和N ;
源程序:
clear
p=@(a,t)(a(2).*a(3))./(a(3)+(a(2)-a(3)).*exp(-a(1).*(t-1790)));
t=1790:10:2000;
c=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.0,92.0,106.5,123.2,131.7,150.7,179.3,20 4.0,226.5,251.4,281.4];
a=nlinfit(t,c,p,[0.03,350,4.0])
sse=sum((c-p(a,t)).^2)
plot(t,c,'r*',t,p(a,t),'r')
axis([1790,2000,0,300])
xlabel('年份'),ylabel('人口(单位:百万)')
title('拟合美国人口数据—阻滞增长型')
legend('拟合数据')
调试结果:
(3)拟合待定参数t0, x0, r和N.要求写出程序,给出拟合参数和误差平方和的计算结
果,并展示误差平方和最小的拟合效果图.
源程序:
clear
p=@(a,t)(a(2).*a(3))./(a(3)+(a(2)-a(3)).*exp(-a(1).*(t-1790+1*a(4))));
t=1790:10:2000;
c=[3.9,5.3,7.2,9.6,12.9,17.1,23.2,31.4,38.6,50.2,62.9,76.0,92.0,106.5,123.2,131.7,150.7,179.3,20 4.0,226.5,251.4,281.4];
[a,x]=nlinfit(t,c,p,[0.03,350,4.0,10])
sse=sum((c-p(a,t)).^2)
t0=1790+1*a(4)
subplot(2,1,1)
plot(t,c,'r*',t,p(a,t),'r')
axis([1790,2000,0,300])
xlabel('年份'),ylabel('人口(单位:百万)')
title('拟合美国人口数据—阻滞增长型')
legend('拟合数据')
subplot(2,1,2)
plot(t,x,'k*',[1790,2000],[0,0],'k-')
axis([1790,2000,-20,20])
xlabel('年份'),ylabel('误差')
title('拟合误差图—阻滞增长型')
legend('拟合数据')
调试结果:
第二讲 插值与数据拟合模型 函数插值与曲线拟合都是要根据一组数据构造一个函数作为近似,由于近似的要求不同,二者的数学方法上是完全不同的。而面对一个实际问题,究竟用插值还是拟合,有时容易确定,有时则并不明显。 在数学建模过程中,常常需要确定一个变量依存于另一个或更多的变量的关系,即函数。但实际上确定函数的形式(线性形式、乘法形式、幂指形式或其它形式)时往往没有先验的依据。只能在收集的实际数据的基础上对若干合乎理论的形式进行试验,从中选择一个最能拟合有关数据,即最有可能反映实际问题的函数形式,这就是数据拟合问题。 一、插值方法简介 插值问题的提法是,已知1+n 个节点n j y x j j ,,2,1,0),,( =,其中j x 互不相同,不妨设b x x x a n =<<<= 10,求任一插值点)(*j x x ≠处的插值*y 。),(j j y x 可以看成是由某个函数)(x g y =产生的,g 的解析表达式可能十分复杂,或不存在封闭形式。也可以未知。 求解的基本思路是,构造一个相对简单的函数)(x f y =,使f 通过全部节点,即),,2,1,0()(n j y x f j j ==,再由)(x f 计算插值,即*)(*x f y =。 1.拉格朗日多项式插值 插值多项式 从理论和计算的角度看,多项式是最简单的函数,设)(x f 是n 次多项式,记作 0111)(a x a x a x a x L n n n n n ++++=-- (1) 对于节点),(j j y x 应有 n j y x L j j n ,,2,1,0,)( == (2) 为了确定插值多项式)(x L n 中的系数011,,,,a a a a n n -,将(1)代入(2),有 ???????=++++=++++=++++---n n n n n n n n n n n n n n n n y a x a x a x a y a x a x a x a y a x a x a x a 01110111110001010 (3) 记 T n T n n n n n n n n n n y y y Y a a a A x x x x x x X ),,,(,),,,(,11110011111 100 ==?????? ? ??=---- 方程组(3)简写成 Y XA = (4) 注意X det 是Vandermonde 行列式,利用行列式性质可得 ∏≤<≤-= n k j j k x x X 0)(det 因j x 互不相同,故0det ≠X ,于是方程(4)中A 有唯一解,即根据1+n 个节点可以确定唯一的n 次插值多项式。 拉格朗日插值多项式 实际上比较方便的做法不是解方程(4)求A ,而是先构造一组基函数: n i x x x x x x x x x x x x x x x x x l n i i i i i i n i i i ,,2,1,0,) ())(()()())(()()(110110 =--------=+-+- (5) )(x l i 是n 次多项式,满足
一、前言部分 本文首先指明了数据拟合的研究背景和意义,以及关于数据拟合问题所做的相关工作和当前的研究现状。二次拟合曲线由于有着良好的几何特性、较低的次数及灵活的控制参数,成为基本的体素模型之一,在计算机图形学和计算机辅助几何设计等领域中起着重要的作用。 解决数据拟合问题的基本思想是最小二乘法,本文中给出了最小二乘法的基本思想。分析解决数据拟合问题所采用的算法,并对典型性的算法进行了较为详细的求解。 关键词数据拟合;最小二乘法;多项式拟合; 二、主题部分 2.1 国内外研究动态,背景及意义 数学分有很多学科,而它主要的学科大致产生于商业计算的需要、了解数字间的关系、测量土地及预测天文事件。而在科技飞速发展的今天数学也早已成为众多研究的基础学科。尤其是在这个信息量巨大的时代,实际问题中国得到的中离散数据的处理也成为数学研究和应用领域中的重要的课题。 比如科学实验中,我们经常要从一组试验数据(,) i i x y,i = 0,1,...,n中来寻找自变量x和因变量y之间的函数关系,通常可以用一个近似函数y = f (x)表示。而函数y = f (x)的产生方法会因为观测数据和具体要求不同而不同,通常我们可以采用数据拟合和函数插值两种方法来实现。 数据拟合主要考虑到了观测数据会受到随机观测误差的影响,需要寻求整体误差最小、能够较好的反映出观测数据的近似函数y = f (x),这时并不要求得 到的近似函数y = f (x)必须满足y i = () i f x,i = 0,1,…,n。 函数插值则要求近似函数y = f (x)在每一个观测点 i x处一定要满足y i= () i f x,i = 0,1,…,n。在这种情况下,通常要求观测数据相对比较准确,即不考虑观测误差的影响。 所以,可以通过比如采样、实验等方法而得到若干的离散的数据,根据这些离散的数据,我们往往希望能得到一个连续函数(也就是曲线)或者更加密集的离散方程与已知数据相吻合。这个过程叫做拟合。也就是说,如果数据不能满足某一个特定的函数的时候,而要求我们所要求的逼近函数“最优的” 靠近那些数据点,按照误差最小的原则为最优标准来构造出函数。我们称这个函数为拟合函数。 2.1.1 国内外研究现状 在通过对国内外有关的学术刊物、国际国内有关学术会议和网站的论文进行参阅。数据拟合的研究和应用主要是面对各种工程问题,有着系统的研究和很大的发展。通过研究发展使得数据拟合有着一定的理论研究基础。尤其是关于数据
第一题 解:由题意可设 2 123()s t a t a t a =++ 中的A=(1a ,2a ,3a )使得: 2 6 1 [()]i i i s t s =-∑最小 用多项式拟合的命令 输入以下命令: 输出结果:A = 2.2488 11.0814 -0.5834 2() 2.2488t 11.0814t 0.5834f x =+- 第二题 输入以下命令: >> x=[19 25 31 38 44]; >> y=[19.0 32.3 49.0 73.3 97.8]; >> A=polyfit(x,y,2)
>> z=polyval(A,x); >> plot(x,y,'k+',x,z,'r') 输出结果:A = 0.0497 0.0193 0.6882 =x x (2+ f ) x + .0 6882 .0 0193 .0 0497 因为2 6882 .0 ) = .0 f+ x (x f+ ) b 0497 (x a =,所以2 x 草图 >> x=1200:400:4000; >> y=1200:400:3600; >> height=[1130 1250 1280 1230 1040 900 500 700; 1320 1450 1420 1400 1300 700 900 850; 1390 1500 1500 1400 900 1100 1060 950; 1500 1200 1100 1350 1450 1200 1150 1010; 1500 1200 1100 1550 1600 1550 1380 1070; 1500 1550 1600 1550 1600 1600 1600 1550; 1480 1500 1550 1510 1430 1300 1200 980]; >> mesh(x,y,height) >>
13. 数据插值与拟合 实际中,通常需要处理实验或测量得到的离散数据(点)。插值与拟合方法就是要通过离散数据去确定一个近似函数(曲线或曲面),使其与已知数据有较高的拟合精度。 1.如果要求近似函数经过所已知的所有数据点,此时称为插值问 题(不需要函数表达式)。 2.如果不要求近似函数经过所有数据点,而是要求它能较好地反 映数据变化规律,称为数据拟合(必须有函数表达式)。 插值与拟合都是根据实际中一组已知数据来构造一个能够反映数据变化规律的近似函数。区别是:【插值】不一定得到近似函数的表达形式,仅通过插值方法找到未知点对应的值。【拟合】要求得到一个具体的近似函数的表达式。 因此,当数据量不够,但已知已有数据可信,需要补充数据,此时用【插值】。当数据基本够用,需要寻找因果变量之间的数量关系(推断出表达式),进而对未知的情形作预测,此时用【拟合】。
一、数据插值 根据选用不同类型的插值函数,逼近的效果就不同,一般有:(1)拉格朗日插值(lagrange插值) (2)分段线性插值 (3)Hermite (4)三次样条插值 Matlab 插值函数实现: (1)interp1( ) 一维插值 (2)intep2( ) 二维插值 (3)interp3( ) 三维插值 (4)intern( ) n维插值 1.一维插值(自变量是1维数据) 语法:yi = interp1(x0, y0, xi, ‘method’) 其中,x0, y0为原离散数据(x0为自变量,y0为因变量);xi为需要插值的节点,method为插值方法。 注:(1)要求x0是单调的,xi不超过x0的范围; (2)插值方法有‘nearest’——最邻近插值;‘linear’——线性插值;‘spline’——三次样条插值;‘cubic’——三次插值;
数据拟合 问题的提出及最小二乘原理 取 x 的n 个不全相同的值n x x x ,,,21 作独立试验,得到样本 ()11,y x ,()22,y x ,…,()n n y x ,,则 i i i bx a y ε++=, 设()2 ,0~σεN i ,各 i ε 相互独立 于是 () 2 ,~σi i bx a N y +, n i ,,2,1 =。且由 n y y y ,,,21 的独立性,知n y y y ,,,21 的联合概率密度为 ()?? ? ?? ?---??? ??=∑=n i i i n bx a y L 12 2 21exp 21σπσ (1) 现用最大似然估计法来估计未知参数 b a ,。对于任意一组观察值 n y y y ,,,21 ,(1)式就是样本的似然函数。显然,要L 取最大值, 只需函数 ()() ∑=--=n i i i bx a y b a Q 12 , 取最小值。 如果 y 不是正态变量,则直接用(1)式估计b a ,使 y 的观察值 i y 与 i bx a + 偏差的平方和 ()b a Q , 为最小。这种方法叫最小二乘法。 如果y 是正态变量,则最小二乘法与最大似然估计法给出相同的结果。 取 ()b a Q ,分别关于b a ,的偏导数,并令它们等于0,得到b a ,
应满足方程 ()()???????=---=??=---=??∑∑==020211n i i i i n i i i x x b a y b Q x b a y a Q (2) (2)式称为正规方程组。解此方程组即可确定 b a ,,从而得到直线方程 bx a y +=*。 对一组测定数据用最小二乘原理找出其合适的数学公式,可以分以下几步: 1. 由观测数据作出散点图 2. 根据散点图确定近似公式的函数类 3. 用最小二乘原理确定函数中的未知参数 这一方法称为数据拟合法。 常用的曲线(函数类)有直线、多项式、双曲线、指数曲线等,实际操作中可以在直观判断的基础上,选几种曲线分别做拟合,然后比较看哪条曲线的最小二乘指标最小。 一. 多变量的数据拟合 若影响变量 y 的因素不只是一个,而是几个,譬如有 k 个因素 k x x x ,,,21 ,这时通过n 次实验可以得到数据表: 实验 1x 2x … k x y 1 11x 21x … 1k x 1y 2 12x 22x … 2k x 2y … … … … … … n n x 1 n x 2 … kn x n y
第十章 插值与拟合方法建模 在生产实际中,常常要处理由实验或测量所得到的一批离散数据,插值与拟合方法就是要通过这些数据去确定某一类已经函数的参数,或寻求某个近似函数使之与已知数据有较高的拟合精度。插值与拟合的方法很多,这里主要介绍线性插值方法、多项式插值方法和样条插值方法,以及最小二乘拟合方法在实际问题中的应用。相应的理论和算法是数值分析的内容,这里不作详细介绍,请参阅有关的书籍。 §1 数据插值方法及应用 在生产实践和科学研究中,常常有这样的问题:由实验或测量得到变量间的一批离散样点,要求由此建立变量之间的函数关系或得到样点之外的数据。与此有关的一类问题是当原始数据 ),(,),,(),,(1100n n y x y x y x 精度较高,要求确定一个初等函数)(x P y =(一般用多项式或分段 多项式函数)通过已知各数据点(节点),即n i x P y i i ,,1,0,)( ==,或要求得函数在另外一些点(插值点)处的数值,这便是插值问题。 1、分段线性插值 这是最通俗的一种方法,直观上就是将各数据点用折线连接起来。如果 b x x x a n =<<<= 10 那么分段线性插值公式为 n i x x x y x x x x y x x x x x P i i i i i i i i i i ,,2,1,,)(11 1 11 =≤<--+--= ----- 可以证明,当分点足够细时,分段线性插值是收敛的。其缺点是不能形成一条光滑曲线。 例1、已知欧洲一个国家的地图,为了算出它的国土面积,对地图作了如下测量:以由西向东方向为x 轴,由南向北方向为y 轴,选择方便的原点,并将从最西边界点到最东边界点在x 轴上的区间适当的分为若干段,在每个分点的y 方向测出南边界点和北边界点的y 坐标y1和y2,这样就得到下表的数据(单位:mm )。
实验题目: 用多项式模型进行数据拟合实验 1 实验目的 本实验使用多项式模型对数据进行拟合,目的在于: (1)掌握数据拟合的基本原理,学会使用数学的方法来判定数据拟合的情况; (2)掌握最小二乘法的基本原理及计算方法; (3)熟悉使用matlab 进行算法的实现。 2 实验步骤 2.1 算法原理 所谓拟合是指寻找一条平滑的曲线,最不失真地去表现测量数据。反过来说,对测量 的实验数据,要对其进行公式化处理,用计算方法构造函数来近似表达数据的函数关系。由于函数构造方法的不同,有许多的逼近方法,工程中常用最小平方逼近(最小二乘法理论)来实现曲线的拟合。 最小二乘拟合利用已知的数据得出一条直线或曲线,使之在坐标系上与已知数据之间的距离的平方和最小。模型主要有:1.直线型2.多项式型3.分数函数型4.指数函数型5.对数线性型6.高斯函数型等,根据应用情况,选用不同的拟合模型。其中多项式型拟合模型应用比较广泛。 给定一组测量数据()i i y x ,,其中m i ,,3,2,1,0 =,共m+1个数据点,取多项式P (x ),使得 min )] ([0 2 2=-=∑∑==m i i i m i i y x p r ,则称函数P (x )为拟合函数或最小二乘解,此时,令 ∑==n k k k n x a x p 0 )(,使得min ])([02 002=??? ? ??-=-=∑∑∑===m i n k i k i k m i i i n y x a y x p I ,其中 n a a a a ,,,,210 为待求的未知数,n 为多项式的最高次幂,由此该问题化为求),,,(210n a a a a I I =的极值问题。 由多元函数求极值的必要条件:0)(200 =-=??∑∑==m i j i n k i k i k i x y x a a I ,其中n j ,,2,1,0 = 得到: ∑∑∑===+=n k m i i j i k m i k j i y x a x 00 )(,其中n j ,,2,1,0 =,这是一个关于n a a a a ,,,,210 的线 性方程组,用矩阵表示如下所示:
辽宁工程技术大学上机实验 报告
(2)取定t0=1790,拟合待定参数x0和r; 程序代码: >> p=@(r,t)r(2).*exp(r(1).*(t-1790)); >> t=1790:10:2000; >> c=[,,,,,,,,, ,,,,,,,,,,,,]; >> r0=[,]; >> r=nlinfit(t,c,p,r0); >> sse=sum((c-p(r,t)).^2); >> plot(t,c,'b*',1790:1:2000,p(r,1790:1:2000),'b') >> axis([1790,2000,0,290]) >> xlabel('年份'),ylabel('人口(单位:百万)') >> title('拟合美国人口数据-指数增长型') >> legend('拟合数据') 程序调用: >> r r = >> sse sse = +003
(3)拟合待定参数t0, x0和r.要求写出程序,给出拟合参数和误差平方和的计算结果,并展示误差平方和最小的拟合效果图. 程序代码: >> p=@(r,t)r(2).*exp(r(1).*(t-1790+1.*r(3))); >> t=1790:10:2000; >> c=[,,,,,,,,, ,,,,,,,,,,,,]; >> r0=[,,1]; >> [r,x]=nlinfit(t,c,p,r0); >> sse=sum((c-p(r,t)).^2); >> a=1790+1.*r(3); >> subplot(2,1,1) >> plot(t,c,'b*',1790:1:2000,p(r,1790:1:2000),'b') >> axis([1790,2000,0,290]) >> xlabel('年份'),ylabel('人口(单位:百万)') >> title('拟合美国人口数据-指数增长型') >> legend('拟合数据') >> subplot(2,1,2) >> plot(t,x,'k+',[1790:2000],[0,0],'k') >> axis([1790,2000,-20,20])
1.线性最小二乘法 x=[19 25 31 38 44]'; y=[19.0 32.3 49.0 73.3 97.8]'; r=[ones(5,1),x.^2]; ab=r\y % if AB=C then B=A\C x0=19:0.1:44; y0=ab(1)+ab(2)*x0.^2; plot(x,y,'o',x0,y0,'r') 运行结果: 2.多项式拟合方法 x0=[1990 1991 1992 1993 1994 1995 1996]; y0=[70 122 144 152 174 196 202]; a=polyfit(x0,y0,1) y97=polyval(a,1997) x1=1990:0.1:1997; y1=a(1)*x1+a(2);
plot(x1,y1) hold on plot(x0,y0,'*') plot(1997,y97,'o') 3.最小二乘优化 3.1 lsqlin 函数 例四: x=[19 25 31 38 44]'; y=[19.0 32.3 49.0 73.3 97.8]'; r=[ones(5,1),x.^2]; ab=lsqlin(r,y) x0=19:0.1:44; y0=ab(1)+ab(2)*x0.^2; plot(x,y,'o',x0,y0,'r') 3.2lsqcurvefit 函数
(1)定义函数 function f=fun1(x,tdata); f=x(1)+x(2)*exp(-0.02*x(3)*tdata); %其中x(1)=a,x(2)=b,x(3)=k (2) td=100:100:1000; cd=[4.54 4.99 5.35 5.65 5.90 6.10 6.26 6.39 6.50 6.59]; x0=[0.2 0.05 0.05]; x=lsqcurvefit(@fun1,x0,td,cd) % x(1)=a,x(2)=b,x(3)=k t=100:10:1000; c=x(1)+x(2)*exp(-0.02*x(3)*t); plot(t,c) hold on plot(td,cd,'*')
第五章离散选择模型 在初级计量经济学里,我们已经学习了解释变量是虚拟变量的情况,除此之外,在实际问题中,存在需要人们对决策与选择行为的分析与研究,这就是被解释变量为虚拟变量的情况。我们把被解释变量是虚拟变量的线性回归模型称为离散选择模型,本章主要介绍这一类模型的估计与应用。 本章主要介绍以下内容: 1、为什么会有离散选择模型。 2、二元离散选择模型的表示。 3、线性概率模型估计的缺陷。 4、Logit模型和Probit模型的建立与应用。 第一节模型的基础与对应的现象 一、问题的提出 在研究社会经济现象时,常常遇见一些特殊的被解释变量,其表现是选择与决策问题,是定性的,没有观测数据所对应;或者其观测到的是受某种限制的数据。 1、被解释变量是定性的选择与决策问题,可以用离散数据表示,即取值是不连续的。例如,某一事件发生与否,分别用1和0表示;对某一建议持反对、中立和赞成5种观点,分别用0、1、2表示。由离散数据建立的模型称为离散选择模型。 2、被解释变量取值是连续的,但取值的范围受到限制,或者将连续数据转化为类型数据。例如,消费者购买某种商品,当消费者愿意支付的货币数量超过该商品的最低价值时,则表示为购买价格;当消费者愿意支付的货币数量低于该商品的最低价值时,则购买价格为0。这种类型的数据成为审查数据。再例如,在研究居民储蓄时,调查数据只有存款一万元以上的帐户,这时就不能以此代表所有居民储蓄的情况,这种数据称为截断数据。这两种数据所建立的模型称为受限被解释变量模型。有的时候,人们甚至更愿意将连续数据转化为上述类型数据来度量,例如,高考分数线的设置,
就把高出分数线和低于分数线划分为了两类。 下面是几个离散数据的例子。 例5.1 研究家庭是否购买住房。由于,购买住房行为要受到许多因素的影响,不仅有家庭收入、房屋价格,还有房屋的所在环境、人们的购买心理等,所以人们购买住房的心理价位很难观测到,但我们可以观察到是否购买了住房,即 我们希望研究买房的可能性,即概率(1) P Y=的大小。 例5.2 分析公司员工的跳槽行为。员工是否愿意跳槽到另一家公司,取决于薪资、发展潜力等诸多因素的权衡。员工跳槽的成本与收益是多少,我们无法知道,但我们可以观察到员工是否跳槽,即 例5.3 对某项建议进行投票。建议对投票者的利益影响是无法知道的,但可以观察到投票者的行为只有三种,即 研究投票者投什么票的可能性,即(),1,2,3 ==。 P Y j j 从上述被解释变量所取的离散数据看,如果变量只有两个选择,则建立的模型为二元离散选择模型,又称二元型响应模型;如果变量有多于二个的选择,则为多元选择模型。本章主要介绍二元离散选择模型。 离散选择模型起源于Fechner于1860年进行的动物条件二元反射研究。1962年,Warner首次将它应用于经济研究领域,用于研究公共交通工具和私人交通工具的选择问题。70-80年代,离散选择模型被普遍应用于经济布局、企业选点、交通问题、就业问题、购买行为等经济决策领域的研究。模型的估计方法主要发展于20世纪80年代初期。(参见李子奈,高等计量经济学,清华大学出版社,2000年,第155页-第156页) 二、线性概率模型 对于二元选择问题,可以建立如下计量经济模型。
插值和拟合 实验目的:了解数值分析建模的方法,掌握用Matlab进行曲线拟合的方法,理解用插值法建模的思想,运用Matlab一些命令及编程实现插值建模。 实验要求:理解曲线拟合和插值方法的思想,熟悉Matlab相关的命令,完成相应的练习,并将操作过程、程序及结果记录下来。 实验内容: 一、插值 1.插值的基本思想 ·已知有n +1个节点(xj,yj),j = 0,1,…, n,其中xj互不相同,节点(xj, yj)可看成由某个函数y= f (x)产生; ·构造一个相对简单的函数y=P(x); ·使P通过全部节点,即P (xk) = yk,k=0,1,…, n ; ·用P (x)作为函数f ( x )的近似。 2.用MA TLAB作一维插值计算 yi=interp1(x,y,xi,'method') 注:yi—xi处的插值结果;x,y—插值节点;xi—被插值点;method—插值方法(‘nearest’:最邻近插值;‘linear’:线性插值;‘spline’:三次样条插值;‘cubic’:立方插值;缺省时:线性插值)。注意:所有的插值方法都要求x是单调的,并且xi不能够超过x的范围。 练习1:机床加工问题 每一刀只能沿x方向和y方向走非常小的一步。 表3-1给出了下轮廓线上的部分数据 但工艺要求铣床沿x方向每次只能移动0.1单位. 这时需求出当x坐标每改变0.1单位时的y坐标。 试完成加工所需的数据,画出曲线. 步骤1:用x0,y0两向量表示插值节点; 步骤2:被插值点x=0:0.1:15; y=y=interp1(x0,y0,x,'spline'); 步骤3:plot(x0,y0,'k+',x,y,'r') grid on 答:x0=[0 3 5 7 9 11 12 13 14 15 ]; y0=[0 1.2 1.7 2.0 2.1 2.0 1.8 1.2 1.0 1.6 ]; x=0:0.1:15; y=interp1(x0,y0,x,'spline'); plot(x0,y0,'k+',x,y,'r') grid on
数据拟合方法研究 中文摘要 在我们实际的实验和勘探中,都会产生大量的数据。为了解释这些数据或者根据这些数据做出预测、判断,给决策者提供重要的依据。需要对测量数据进行拟合,寻找一个反映数据变化规律的函数。 本文介绍了几种常用的数据拟合方法,线性拟合、二次函数拟合、数据的n次多项式拟合等。并着重对曲线拟合进行了研究,介绍了线性与非线性模型的曲线拟合方法,最小二乘法、牛顿迭代法等。在传统的曲线拟合基础上,为了提高曲线拟合精度,本文还研究了多项式的摆动问题,从实践的角度分析了产生这些摆动及偏差的因素和特点,总结了在实践中减小这些偏差的处理方法。采用最小二乘法使变量转换后所得新变量离均差平方和最小,并不一定能使原响应变量的离均差平方和最小,所以其模型的拟合精度仍有提高的空间。本文以残数法与最小二乘法相结合,采用非线性最小二乘法来得到拟合效果更好的曲线模型。随着计算机技术的发展,实验数据处理越来越方便。但也提出了新的课题,就是在选择数据处理方法时应该比以往更为慎重。因为稍有不慎,就会非常方便地根据正确的实验数据得出不确切的乃至错误的结论。所以提高拟合的准确度是非常有必要的 关键词:数据拟合、最小二乘法、曲线拟合、多项式摆动、残数法
Data Fitting Method Abstract In our experiments and exploration, it will produce large amounts of data. In order to explain these data to make predictions based on these data to determine, provide an important basis for policy makers .Need to fit the measured data to find a function to reflect data changes in the law.This article describes several commonly used data fitting methods, and focused on a nonlinear curve fitting of the model. This paper introduces some commonly used data fitting method, linear fitting, secondary function fitting, data n times polynomial fitting etc. T And focuses on the curve fitting, introduced the linear and nonlinear model of curve fitting method, the least square method, Newton iterative method, etc. In the traditional curve fitting basis, in order to improve the curve fitting precision, this paper also studies the polynomial swing, from the perspective of the practice the oscillation and deviation of factors and characteristics, and summarizes the decrease in practice the treatment method of these deviations. The least square method to variable after converting from new variables are the sum of squared residuals minimum, not necessarily make the original response from all the variables of the sum of squared residuals minimum, so the model fitting precision still has room to improve.Based on the number of residual method and least square method, and the combination of nonlinear least square method to get better fitting effect of curve model.With the development of computer technology, the experiment
离散选择模型 HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】
第五章离散选择模型 在初级计量经济学里,我们已经学习了解释变量是虚拟变量的情况,除此之外,在实际问题中,存在需要人们对决策与选择行为的分析与研究,这就是被解释变量为虚拟变量的情况。我们把被解释变量是虚拟变量的线性回归模型称为离散选择模型,本章主要介绍这一类模型的估计与应用。 本章主要介绍以下内容: 1、为什么会有离散选择模型。 2、二元离散选择模型的表示。 3、线性概率模型估计的缺陷。 4、Logit模型和Probit模型的建立与应用。 第一节模型的基础与对应的现象 一、问题的提出 在研究社会经济现象时,常常遇见一些特殊的被解释变量,其表现是选择与决策问题,是定性的,没有观测数据所对应;或者其观测到的是受某种限制的数据。 1、被解释变量是定性的选择与决策问题,可以用离散数据表示,即取值是不连续的。例如,某一事件发生与否,分别用1和0表示;对某一建议持反对、中立和赞成5种观点,分别用0、1、2表示。由离散数据建立的模型称为离散选择模型。 2、被解释变量取值是连续的,但取值的范围受到限制,或者将连续数据转化为类型数据。例如,消费者购买某种商品,当消费者愿意支付的货币数量超过该商品的最低价值时,则表示为购买价格;当消费者愿意支付的货币数量低于该商品的最低价值时,则购买价格为0。这种类型的数据成为审查数据。再例如,在研究居民储蓄时,调查数据只有存款一万元以上的帐户,这时就不能以此代表所有居民储蓄的情况,这种数据称为截断数据。这两种数据所建立的模型称为受限被解释变量模型。有的时候,人们甚至更愿意将连续数据转化为上述类型数据来度量,例如,高考分数线的设置,就把高出分数线和低于分数线划分为了两类。 下面是几个离散数据的例子。 例研究家庭是否购买住房。由于,购买住房行为要受到许多因素的影响,不仅有家庭收入、房屋价格,还有房屋的所在环境、人们的购买心理等,所以人们购买住
曲线拟合 摘要 根究已有数据研究y关于x的关系,对于不同的要求得到不同的结果。 问题一中目标为使的各个观察值同按直线关系所预期的值的偏差平方和为最小,利用MATLAB中t lsqcurvefi函数在最小二乘法原理下拟合出所求直线。 问题二目标为使绝对偏差总和为最小,使用MATLAB中的fminsearch函数,在题目约束条件内求的最优答案,以此方法同样求得问题三中最大偏差为最小时的直线。 问题四拟合的曲线为二阶多项式,方法同前三问类似。 问题五为求得最佳的曲线,将之前的一次曲线换成多次曲线进行拟合得到新的结果。经试验发现高阶多项式的阶数越高拟和效果最好。 ) 关键词:函数拟合最小二乘法线性规划 | < ¥
一、问题的重述 已知一个量y 依赖于另一个量x ,现收集有数据如下: (1)求拟合以上数据的直线a bx y +=。目标为使y 的各个观察值同按直线关系所预期的值的偏差平方和为最小。 (2)求拟合以上数据的直线a bx y +=,目标为使y 的各个观察值同按直线关系所预期的值的绝对偏差总和为最小。 (3)求拟合以上数据的直线,目标为使y 的各个观察值同按直线关系所预期的值的最大偏差为最小。 (4)求拟合以上数据的曲线a bx cx y ++=2,实现(1)(2)(3)三种目标。 } (5)试一试其它的曲线,可否找出最好的? 二、问题的分析 对于问题一,利用MATLAB 中的最小二乘法对数据进行拟合得到直线,目标为使各个观察值同按直线关系所预期的值的偏差平方和为最小。 对于问题二、三、四均利用MATLAB 中的fminsearch 函数,在题目要求的约束条件下找到最佳答案。 对于问题五,改变多项式最高次次数,拟合后计算残差,和二次多项式比较,再增加次数后拟合,和原多项式比较残差,进而找到最好的曲线。 ~
离散模型 § 1 离散回归模型 一、离散变量 如果我们用0,1,2,3,4,…说明企业每年的专利申请数,申请数是一个离散的变量,但是它是间隔尺度变量,该变量类型不在本章的讨论的被解释变量中。但离散变量0和1可以用来说明企业每年是否申请专利的事项,类似表示状态的变量才在本章的讨论中。在专利申请数的问题中,离散变量0,1,2,3和4等数字具有具体的经济含义,不能随意更改;而在是否申请专利的两个选择对象的选择问题中,数字0和1只是用于区别两种不同的选择,是表示一种状态。本专题讨论有序尺度变量和名义尺度变量的被解释变量。 二、离散因变量
在讨论家庭是否购房的问题中,可将家庭购买住房的决策用数字1 表示,而将家庭不购买住房的决策用数字0表示。 10 yes x no ?=?? 如果x 作为说明某种具体经济问题的自变量,则应用以前介绍虚拟变量知识就足够了。如果现在考虑某个家庭在一定的条件下是否购买住房问题时,则表示状态的虚拟变量就不再是自变量,而是作为一个被说明对象的因变量出现在经济模型中。因此,需要对以前讨论虚拟变量的分析方法进行扩展,以便使其能够适应分析类似家庭是否购房的问题。因为在家庭是否购房问题中,虚拟因变量的具体取值仅是为了区别不同的状态,所以将通过虚拟因变量讨论备择对象选择的回归模型称为离散选择模型。 三、线性概率模型
现在约定备择对象的0和1两项选择模型中,下标i 表示各不同的经济主体,取值0或l 的因变量i y 表示经济主体的具体选择结果,而影响经济主体进行选择的自变量i x 。如果选择响应 YES 的概率为(1/)i p y =i x ,则经济主体选择响应 NO 的概率为1(1/)i i p y -=x , 则(/)1(1/)0(0/)i i i i i i E y p y p y =?=+?=x x x =(1/)i i p y x =。 根据经典线性回归,我们知道其总体回归方程是条件期望建立的,这使我们想象可以构造线性概率模型 (1/)(/)i i i i i p y x E y x '===x β 011i k ik i x x u βββ=++++L 描述两个响应水平的线性概率回归模型可推知,根据统计数据得到的回归结果并不一定能够保证回归模型的因变量拟合值界于[0,1]。如果通过回归模型式得到的因变量拟合值完全偏离0或l 两个数值,则描述两项选择的回归模型的实际用途
插值与拟合模型 水道测量数据问题 表1给出了在以码(1码=0.914米)为单位的直角坐标为X,Y的水面一点处以英尺(1英尺=0.3048米)计的水深Z。水深数据是在低潮时测得的。 表1 水道测量数据在低潮时测得的水深 船的吃水深度为5英尺。在矩形区域(75,200)ⅹ(-50,150)里哪些地方船要避免进入。 解答: 所给14个点的平面散点图如下,其中有两点不落在所给区域:(75,200)ⅹ(-50,150)。
图17.1 水道离散点平面图 本问题采用地球科学上的反距离权重法(IDW)。首先将所给区域(75,200)ⅹ(-50,150)按较细的网格进行剖分。然后利用所给14个点的水深值Z ,按照IDW 方法求出所有剖分点的水深值Z ,并找出水深低于5米的点。然后作出水底曲面图,等值线图,标出水深低于5米的区域。 IDW 算法: 设有n 个点(,,)i i i x y z ,计算平面上任意点(,)x y 的z 值。 1 .n i i i z w z == ∑ 其中权重: 1 1/1/p i i n p i i d w d == ∑ ,i d = 即(,)x y 处的z 值由各已知点加权得到,其权重为(,)x y 到各点距离的p 次方成反比。 p 决定距离(,)x y 近的(,)i i x y 作用的相对大小。当p 越大,则当(,)i i x y 距离(,)x y 越近, 其相对作用越大,越远相对作用越小。本题取3p =。 按照IDW 方法,x 方向剖分50个区间,区间间隔2.5;y 方向剖分80个区间,区间间隔 2.5dy =得到的水底河床图及等值线图如下。实现的Matlab 程序见后。
曲线拟合与回归分析 1、有 10个同类企业的生产性固定资产年平均价值和工业总产值资料如下: (1说明两变量之间的相关方向; (2建立直线回归方程; (3计算估计标准误差; (4估计生产性固定资产(自变量为 1100万元时的总资产 (因变量的可能值。 解: (1工业总产值是随着生产性固定资产价值的增长而增长的,存 在正向相关性。 用 spss 回归 (2 spss 回归可知:若用 y 表示工业总产值(万元,用 x 表示生产性固定资产,二者可用如下的表达式近似表示: 567 . 395 896 . 0+ =x
y (3 spss 回归知标准误差为 80.216(万元。 (4当固定资产为 1100时,总产值为: (0.896*1100+395.567-80.216~0.896*1100+395.567+80.216 即(1301.0~146.4这个范围内的某个值。 MATLAB 程序如下所示: function [b,bint,r,rint,stats] = regression1 x = [318 910 200 409 415 502 314 1210 1022 1225]; y = [524 1019 638 815 913 928 605 1516 1219 1624]; X = [ones(size(x', x']; [b,bint,r,rint,stats] = regress(y',X,0.05; display(b; display(stats; x1 = [300:10:1250]; y1 = b(1 + b(2*x1;
figure;plot(x,y,'ro',x1,y1,'g-'; 生产性固定资产价值 (万元 工业总价值 (万元 industry = ones(6,1; construction = ones(6,1; industry(1 =1022; construction(1 = 1219; for i = 1:5
数学模型实验—实验报告4 学院:河北大学工商学院专业:电气七班姓名:李青青 学号:2012484098 实验时间:2014/4/15 实验地点:B3-301 一、实验项目:数据拟合与模型参数估计 二、实验目的和要求 a.了解数据拟合的原理和Matlab中的有关命令。 Polfit:MATLAB函数:p=polyfit(x,y,n) [p,s]= polyfit(x,y,n) 说明:x,y为数据点,n为多项式阶数,返回p为幂次从高到低的多项式系数向量p。x必须是单调的。矩阵s用于生成预测值的误差估计。(见下一函数polyval) 多项式曲线求值函数:polyval( ) 调用格式:y=polyval(p,x) [y,DELTA]=polyval(p,x,s) 说明:y=polyval(p,x)为返回对应自变量x在给定系数P的多项式的值。 [y,DELTA]=polyval(p,x,s) 使用polyfit函数的选项输出s得出误差估计Y DELTA。它假设polyfit函数数据输入的误差是独立正态的,并且方差为常数。则Y DELTA将至少包含50%的预测值。 Polyval
polyval函数的主要功能是多项式的估值运算,其语法格式为y = poly val(p,x),输入变量p是长度为n+1的向量,各元素是依次按降幂排列的多项式的系数,函数返回的是那次多项式p在x处的值,x可以是一个数,也可以是一个矩阵或者一个向量,在后两种情况下,该指令计算的是在X中任意元素处的多项式p的估值。 polyvalm的主要功能是用于matlab中多项式求值。其语法格式为y=polyvalm(a,A),其中a为多项式行向量表示,A为指定矩阵。 Lsqlin 约束线性最小二乘 函数lsqlin 格式x = lsqlin(C,d,A,b) %求在约束条件下,方程Cx = d的最小二乘解x。 x = lsqlin(C,d,A,b,Aeq,beq) %Aeq、beq满足等式约束,若没有不等式约束,则设A=[ ],b=[ ]。 x = lsqlin(C,d,A,b,Aeq,beq,lb,ub) %lb、ub满足,若没有等式约束,则Aeq=[ ],beq=[ ]。 x = lsqlin(C,d,A,b,Aeq,beq,lb,ub,x0) % x0为初始解向量,若x没有界,则lb=[ ],ub=[ ]。 x = lsqlin(C,d,A,b,Aeq,beq,lb,ub,x0,options) % options为指定优化参数 lsqcurvefit