
收稿日期:1999-12-15 基金项目:陕西省教委自然科学专项基金资助项目(99J K096) 作者简介:邢志栋(1950-),男,副教授.变分不等式问题的新发展 邢志栋1,曾云辉1,刘三阳2 (11西北大学数学系,陕西西安 710069;21西安电子科技大学理学院,陕西西安 710071) 摘要:在简要地介绍变分不等式的基本理论和算法的基础上,归纳出当前求解变分不等式的4类主要 数值方法:投影收缩算法;基于间隙函数的鞍点算法;基于K -K -T 方程组的简单约束优化算法和基于法 方程的解法. 关键词:变分不等式;投影收缩;法方程 中图分类号:O178;O221 文献标识码:A 文章编号:1001-2400(2000)05-0648-05 New advan ces in m ethods for varia tiona l inequa lit y XI NG Zhi-do ng 1,ZENG Yun-hui 1,LI U Sa n-y ang 2 (1.Dept.of Mathm atics,Northwest Univ.,Xi c an 710069,China; 2.School of Science,Xidian Univ.,Xi c an 710071,China) Abs t r a c t : The ba s i c t he o r y a nd a l g o r i t hm s o f v a r i a t i o nal i nequa l i t y a r e i nt r o duc e d, a nd v a r i o us m e t ho ds ha v e be e n de v e l o pe d f o r t he r e s o l ut i o n o f VI P.The y a r e t he pr o j e c t i o n a nd c o nt r a c t i o n m e t ho d,t he s a ddl e po i nt a l g o r i t hm s ba s e d o n t he g a p f unc t i o n ,t he s i m pl e c o ns t r a i ne d opt i m i z a t i o n m e t ho d o n K -K -T e qua t i o ns a nd t he s t a t e g y m a j o r i ng i n t he e qui v a i e nt no r m a l e qua t i o n i ns t e a d o f t he i ni y i a l v ar i a t i o na l i ne qua l i t y. Ke y W o r ds: v a r i a t i o na l i ne qua l i t y ;pr o j e c t i o n and co nt r a c t i o n m e t ho d;no r m a l e qua- t i o n 1 变分不等式问题的基本理论 111 变分不等式的定义及与其他数学规划问题的关系 设X 为n 维欧氏空间R n 中的非空闭凸集,映射F :R n y R m ,则变分不等式问题(VI (X ,F)): 求x I X , 使F (x )T (y -x )\0 , P y I X . (1)变分不等式问题(VI)与其他数学规划有着密切联系: 1)如果X 取为R n 中的开集,文献[1]称VI (X ,F )为广义方程组,即 F (x )=0 ; (2) 2)假设F (x )的梯度¨F (x )为对称阵,此时VI (X ,F)的一个解x *为约束优化问题 min g(x ) s.t.x I X ,(3) 的一个驻点,文献[2]称其为驻点问题. 3)当可行集X 为非负象限时,变分不等式VI (X ,F )等价于非线性互补问题NCP (F ),即 2000年10月 第27卷 第5期 西安电子科技大学学报(自然科学版)JOURNAL OF XID IAN UNIVERSITY Oct.2000 Vol.27 No.5
智能计算读书报告(二) 智能优化算法 姓名:XX 学号:XXXX 班级:XXXX 联系方式:XXXXXX
一、引言 智能优化算法又称为现代启发式算法,是一种具有全局优化性能、通用性强、且适用于并行处理的算法。这种算法一般具有严密的理论依据,而不是单纯凭借专家的经验,理论上可以在一定时间内找到最优解或者近似最优解。所以,智能优化算法是一数学为基础的,用于求解各种工程问题优化解的应用科学,其应用非常广泛,在系统控制、人工智能、模式识别、生产调度、VLSI技术和计算机工程等各个方面都可以看到它的踪影。 最优化的核心是模型,最优化方法也是随着模型的变化不断发展起来的,最优化问题就是在约束条件的限制下,利用优化方法达到某个优化目标的最优。线性规划、非线性规划、动态规划等优化模型使最优化方法进入飞速发展的时代。 20世纪80年代以来,涌现出了大量的智能优化算法,这些新颖的智能优化算法被提出来解决一系列的复杂实际应用问题。这些智能优化算法主要包括:遗传算法,粒子群优化算法,和声搜索算法,差分进化算法,人工神经网络、模拟退火算法等等。这些算法独特的优点和机制,引起了国内外学者的广泛重视并掀起了该领域的研究热潮,并且在很多领域得到了成功地应用。 二、模拟退火算法(SA) 1. 退火和模拟退火 模拟退火算法(Simulated Annealing,SA)最早的思想是由N. Metropolis 等人于1953年提出。1983 年,S. Kirkpatrick 等成功地将退火思想引入到组合优化领域。它是基于Monte-Carlo迭代求解策略的一种随机寻优算法,其出发点是基于物理中固体物质的退火过程与一般组合优化问题之间的相似性。模拟退火算法从某一较高初温出发,伴随温度参数的不断下降,结合概率突跳特性在解空间中随机寻找目标函数的全局最优解,即在局部最优解能概率性地跳出并最终趋于全局最优。模拟退火算法是一种通用的优化算法,理论上算法具有概率的全局优化性能,目前已在工程中得到了广泛应用,诸如VLSI、生产调度、控制工程、机器学习、神经网络、信号处理等领域。 模拟退火算法是通过赋予搜索过程一种时变且最终趋于零的概率突跳性,从而可有效避免陷入局部极小并最终趋于全局最优的串行结构的优化算法。 模拟退火其实也是一种贪心算法,但是它的搜索过程引入了随机因素。模拟
《并行算法设计与分析》考题与答案 一、1.3,处理器PI的编号是: 解:对于n ×n 网孔结构,令位于第j行,第k 列(0≤j,k≤n-1)的处理器为P i(0≤i≤n2-1)。以16处理器网孔为例,n=4(假设j、k由0开始): 由p0=p(j,k)=p(0,0) P8=p(j,k)=p(2,0) P1=p(j,k)=p(0,1) P9=p(j,k)=p(2,1) P2=p(j,k)=p(0,2) P10=p(j,k)=p(2,2) P3=p(j,k)=p(0,3) P11=p(j,k)=p(2,3) P4=p(j,k)=p(1,0) P12=p(j,k)=p(3,0) P5=p(j,k)=p(1,1) P13=p(j,k)=p(3,1) P6=p(j,k)=p(1,2) P14=p(j,k)=p(3,2) P7=p(j,k)=p(1,3) P15=p(j,k)=p(3,3) 同时观察i和j、k之间的关系,可以得出i的表达式为:i= j * n+k
一、1.6矩阵相乘(心动算法) a)相乘过程 设 A 矩阵= 121221122121 4321 B 矩阵=1 23443212121121 2 【注】矩阵元素中A(i,l)表示自左向右移动的矩阵,B(l,j)表示自上向下移动的矩阵,黑色倾斜加粗标记表示已经计算出的矩阵元素,如12, C(i,j)= C(i,j)+ A(i,l)* B(l,j) 1 2、
4、
6、
8、
10 计算完毕 b)可以在10步后完成,移动矩阵长L=7,4*4矩阵N=4,所以需要L+N-1=10
第四章 并行算法的设计基础 习题例题: 1. 试证明Brent 定理:令W (n)是某并行算法A 在运行时间T(n)内所执行的运算数量,则 A 使用p 台处理器可在t(n)=O(W(n)/p+T(n))时间内执行完毕。 2. 假定P i (1≤i ≤n )开始时存有数据d i , 所谓累加求和指用 1 i j j d =∑来代替P i 中的原始值 d i 。 算法 PRAM-EREW 上累加求和算法 输入: P i 中保存有d i , l ≤ i ≤ n 输出: P i 中的内容为 i j j l d =∑ begin for j = 0 to logn – 1 do for i = 2j + 1 to n par-do (i) P i = d i-(2^i) (ii) d i = d i + d i-(2^j) endfor endfor end (1)试用n=8为例,按照上述算法逐步计算出累加和。 (2)分析算法时间复杂度。 3. 在APRAM 模型上设计算法时,应尽量使各处理器内的局部计算时间和读写时间大致 与同步时间B 相当。当在APRAM 上计算M 个数的和时,可以借用B 叉树求和的办法。 假定有j 个处理器计算n 个数的和,此时每个处理器上分配n/p 个数,各处理器先求出自身的局和;然后从共享存储器中读取它的B 个孩子的局和,累加后置入指定的共享存储单元SM 中;最后根处理器所计算的和即为全和。算法如下: 算法 APRAM 上求和算法 输入: n 个待求和的数 输出: 总和在共享存储单元SM 中 Begin (1) 各处理器求n/p 个数的局和,并将其写入SM 中 (2) Barrier (3) for k = [ log B ( p(B – 1) + 1) ] – 2 downto 0 do 3.1 for all P i , 0 ≤ i ≤ p – 1,do if P i 在第k 级 then P i 计算其B 各孩子的局和并与其自身局和相加,然后将结果写入SM 中 endif
《计算机系统结构》大作业 对并行算法的介绍和展望 专业计算机科学与技术 班级 111 学号 111425020133 姓名完颜杨威 日期 2014年4月17日 河南科技大学国际教育学院
对并行算法的介绍和展望 我们知道,算法是求解问题的方法和步骤。而并行算法就是用多台处理机联合求解问题的方法和步骤,其执行过程是将给定的问题首先分解成若干个尽量相互独立的子问题,然后使用多台计算机同时求解它,从而最终求得原问题的解。并行算法的研究涉及到理论、设计、实现、应用等多个方面,要保持并行算法研究的持续性和完整性,需要建立一套完整的“理论-设计-实现-应用”的学科体系,也就是所谓的并行算法研究的生态环境。其中,并行算法理论是并行算法研究的理论基础,包含并行计算模型和并行计算复杂性等;并行算法的设计与分析是并行算法研究的核心内容;并行算法的实现是并行算法研究的应用基础,包含并行算法实现的硬件平台和软件支撑技术等;并行应用是并行算法研究的发展动力,除了包含传统的科学工程计算应用外,还有新兴的与社会相关的社会服务型计算应用等。 并行算法主要分为数值计算问题的并行算法和非数值计算问题的并行算法。而并行算法的研究主要分为并行计算理论、并行算法的设计与分析、和并行算法的实现三个层次。现在,并行算法之所以受到极大的重视,是为了提高计算速度、提高计算精度,以及满足实时计算需要等。然而,相对于串行计算,并行计算又可以划分成时间并行和空间并行。时间并行即流水线技术,空间并行使用多个处理器执行并发计算,当前研究的主要是空间的并行问题。并行算法是一门还没有发展成熟的学科,虽然人们已经总结出了相当多的经验,但是远远不及串行算法那样丰富。并行算法设计中最常用的的方法是PCAM方法,即划分,通信,组合,映射。首先划分,就是将一个问题平均划分成若干份,并让各个处理器去同时执行;通信阶段,就是要分析执行过程中所要交换的数据和任务的协调情况,而组合则是要求将较小的问题组合到一起以提高性能和减少任务开销,映射则是要将任务分配到每一个处理器上。任何一个并行算法必须在一个科学的计算模型中进行设计。我们知道,任何算法必须有计算模型。任何并行计算模型必须要有为数不多、有明确定义的、可以定量计算的或者可以实际测量的参数,这些参数可以构成相应函数。并行计算模型是算法设计者与体系结构研究者之间的一个桥梁,是并行算法设计和分析的基础。它屏蔽了并行机之间的差异,从并行机中抽取若干个能反映计算特性的可计算或可测量的参数,并按照模型所定义的计算行为构造成本函数,以此进行算法的复杂度分析。 经过多年的发展,我国在并行算法的研究上也取得了显著进展,并行计算的应用已遍布天气预报、石油勘探、航空航天、核能利用、生物工程等领域,理论研究与应用普及均取得了很大发展。随着高性价比可扩展集群并行系统的逐步成熟和应用,大规模电力系统潮流并行计算和分布式仿真成为可能。目前,并行算法在地震数据处理中应用已较为成熟,近年来向更实用的基于PC机群的并行技术发展.然而,在非地震方法中,并行算法应用较少见文献报道,研究尚处于初级研究阶段。在大地电磁的二维和三维正、反演问题上,并行计算技术逐渐得到越来越多关注和重视.随着资源和能源需求的增长,地球物理勘探向深度和广度快速发展,大幅增长的数据量使得高性能并行计算机和高效的并行算法在勘探地球物理学中的发展和应用将占据愈来愈重要的地位。计算机技术在生物医学领域已经广泛应用,实践证明,并行算法在生物医学工程的各个领域中具有广泛的应用价值,能有效提高作业效率。随着电子科学技术的发展,电磁问题变得越来越复杂,为了在有限的计算机资源条件下求解大规模复杂电磁问题,许电磁学家已
第5章 并行算法的一般设计策略 习题例题: 1、 令n是待排序的元素数,p=2d是d维超立方中处理器的数目。假定开始随机选定主元x,并将其播送给所有其他处理器,每个处理器按索接收到的x,对其n/p个元素按照≤x 和>x进行划分,然后按维进行交换。这样在超立方上实现的快排序算法如下: 算法5.6 超立方上快排序算法 输入:n个元素,B = n/p, d = log p 输出: 按超立方编号进行全局排序 Begin (1)id = processor’s label (2)for i=1 to d do (2.1) x = pivot / * 选主元 * / (2.2) 划分B为B1和B2满足B1 ≤B<B2 (2.3) if第i位是零 then (i) 沿第i维发送B2给其邻者 (ii) C = 沿第i维接收的子序列 (iii) B= B1∪C else (i) 沿第i维发送B1给其邻者 (ii) C = 沿第i维接收的子序列 (iii) B= B2∪C endif endfor (3)使用串行快排序算法局部排序B = n/p个数 End ① 试解释上述算法的原理。 ② 试举一例说明上述算法的逐步执行过程。 2、 ① 令T = babaababaa。P =abab,试用算法5.4计算两者的匹配情况。 ② 试分析KMP算法为何不能简单并行化。 3、 给定序列(33,21,13,54,82,33,40,72)和8个处理器,试按照算法5.2构造一棵为在PRAM-CRCW模型上执行快排序所用的二叉树。 4、 计算duel(p, q)函数的算法如下: 算法5.7 计算串匹配的duel(p, q) 的算法 输入: WIT〔1: n-m+1〕,1≤p<q≤n-m+1,(p - q) < m/2 输出: 返回竞争幸存者的位置或者null(表示p和q之一不存在) Begin if p=null then duel= q else
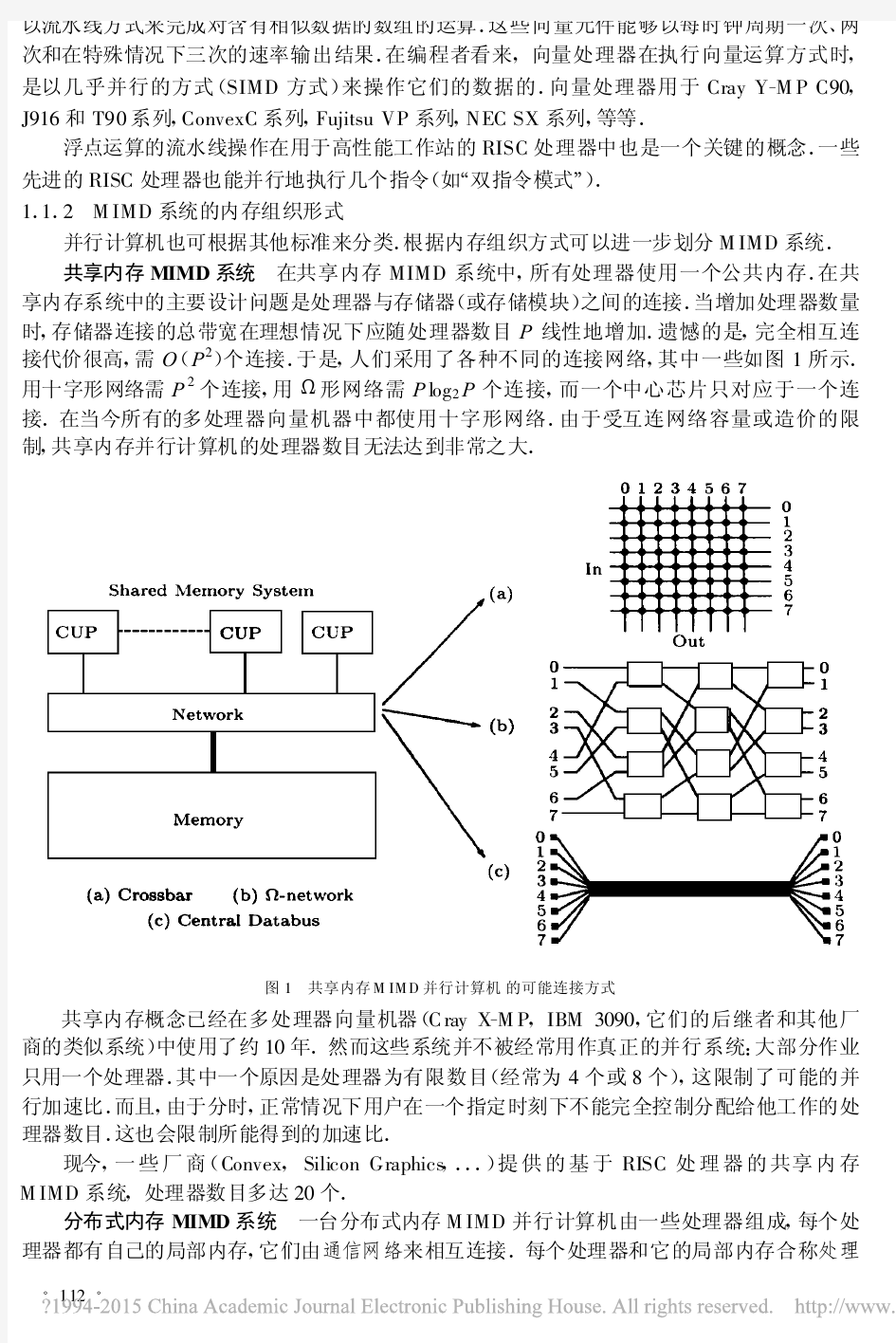
《并行算法》课程总结与复习 Ch1 并行算法基础 1.1 并行计算机体系结构 并行计算机的分类 ?SISD,SIMD,MISD,MIMD; ?SIMD,PVP,SMP,MPP,COW,DSM 并行计算机的互连方式 ?静态:LA(LC),MC,TC,MT,HC,BC,SE ?动态:Bus, Crossbar Switcher, MIN(Multistage Interconnection Networks) 1.2 并行计算模型 PRAM模型:SIMD-SM, 又分CRCW(CPRAM,PPRAM,APRAM),CREW,EREW SIMD-IN模型:SIMD-DM 异步APRAM模型:MIMD-SM BSP模型:MIMD-DM,块内异步并行,块间显式同步 LogP模型:MIMD-DM,点到点通讯 1.3 并行算法的一般概念 并行算法的定义 并行算法的表示 并行算法的复杂度:运行时间、处理器数目、成本及成本最优、加速比、并行效率、工作量 并行算法的WT表示:Brent定理、WT最优 加速比性能定律 并行算法的同步和通讯 Ch2 并行算法的基本设计技术 基本设计技术 平衡树方法:求最大值、计算前缀和 倍增技术:表序问题、求森林的根 分治策略:FFT分治算法 划分原理: 均匀划分(PSRS排序)、对数划分(并行归并排序)、方根划分(Valiant归并排序)、功能划分( (m,n)-选择) 流水线技术:五点的DFT计算 Ch3 比较器网络上的排序和选择算法 3.1 Batcher归并和排序 0-1原理的证明 奇偶归并网络:计算流程和复杂性(比较器个数和延迟级数)
双调归并网络:计算流程和复杂性(比较器个数和延迟级数) Batcher排序网络:原理、种类和复杂性 3.2 (m, n)-选择网络 分组选择网络 平衡分组选择网络及其改进 Ch4 排序和选择的同步算法 4.1 一维线性阵列上的并行排序算法 4.2 二维Mesh上的并行排序算法 ShearSort排序算法 Thompson&Kung双调排序算法及其计算示例 4.3 Stone双调排序算法 4.4 Akl并行k-选择算法:计算模型、算法实现细节和时间分析 4.5 Valiant并行归并算法:计算模型、算法实现细节和时间分析 4.7 Preparata并行枚举排序算法:计算模型和算法的复杂度 Ch5 排序和选择的异步和分布式算法 5.1 MIMD-CREW模型上的异步枚举排序算法 5.2 MIMD-TC模型上的异步快排序算法 5.3分布式k-选择算法 Ch6 并行搜索 6.1 单处理器上的搜索 6.2 SIMD共享存储模型上有序表的搜索:算法 6.3 SIMD共享存储模型上随机序列的搜索:算法 6.4 树连接的SIMD模型上随机序列的搜索:算法 6.5 网孔连接的SIMD模型上随机序列的搜索:算法和计算示例 Ch8 数据传输与选路 8.1 引言 信包传输性能参数 维序选路(X-Y选路、E-立方选路) 选路模式及其传输时间公式 8.2 单一信包一到一传输 SF和CT传输模式的传输时间(一维环、带环绕的Mesh、超立方) 8.3 一到多播送 SF和CT传输模式的传输时间(一维环、带环绕的Mesh、超立方)及传输方法8.4 多到多播送 SF和CT传输模式的传输时间(一维环、带环绕的Mesh、超立方)及传输方法8.5 贪心算法(书8.2) 二维阵列上的贪心算法 蝶形网上的贪心算法 8.6 随机和确定的选路算法(书8.3) Ch12矩阵运算
山东大学 博士学位论文 几个组合优化问题的研究姓名:董振宁 申请学位级别:博士专业:运筹学与控制论指导教师:刘家壮 20040325
几个组合优化问题的研究 董振宁 (山东大学数学与系统科学学院,济南,250100) 中文摘要 组合优化问题是运筹学中的一个重要分支,随着实践的不断发展,越来越多的新问题利用它的古典模型求解不再合适,比如最短路问题、最小费用流问题、运输问题等.因而需要对原来的古典模型进行改进,构造出新的组和优化模型,并为之设计算法.本文研究了组合优化问题中具有特殊限制的最短路问题、最小费用流同题和运输问题,共分为六章; 第一章绪论,首先介绍了组合优化问题的统一形式,由于现代大多数组合优化问题都是ⅣP—hard的,因此我们接着介绍了ⅣP—hard问题几种常见的处理方法,最后介绍了与本文有关的三类经典组合优化问题的模型及算法.设F是有限集,c是F到实数集R的映射,即c是定义在F上的一个函数.求_,∈F,使得对于任意的Y∈F,有 c(S)≤c(y) 成立.。上述问题称为组合优化问题,简记为;求rainc(.厂) 早期的组合优化问题通常可以设计出一个方便快捷的算法求得其最优解,比如最小支撑树问题.随着实践的发展,人们遇到了很多组合优化问题都找不到多项式算法.人们将其称为ⅣP问题.后来,人们归结出了一类ⅣP—hard问题,认为它们基本上不可能存在多项式时间算法.如果一个算法能够求得这些问题的最优解,则它的计算时间将会很长,以至于无法忍受.由于Ⅳ|P—hard问题无法设计出多项式算法,很多ⅣP—hard问题又非常有应用价值,因而人们都在努力为其设计近似算法、启发式算法或者遗传算法.近似算法能够保证计算结果与最优结果相比较的差别不超过某一常数血,且Q一般较小,但是算法比较复杂,在计算机上编程时比较困难;启发式算法算法通常很简单,很容易在计算机上实现,一般情况下也能够保证计算结果同最优结果差别不超过某一常数o,但是n相对于近似算法要大.也有一些启发式算法无法保证解的近似度,但计算结果通常都比较理想,如本文为
第十二章 并行程序设计基础 习题例题: 1、假定有n 个进程P(0),P(1),…,P(n -1),数组元素][i a 开始时被分配给进程P(i )。试写出求归约和]1[]1[]0[-+++n a a a 的代码段,并以8=n 示例之。 2、假定某公司在银行中有三个账户X 、Y 和Z ,它们可以由公司的任何雇员随意访问。雇员们对银行的存、取和转帐等事务处理的代码段可描述如下: /*从账户X 支取¥100元*/ atomic { if (balance[X] > 100) balance[X] = balance[X]-100; } /*从账户Y 存入¥100元*/ atomic {balance[Y] = balance[Y]-100;} /*从账户X 中转¥100元到帐号Z*/ atomic { if (balance[X] > 100){ balance[X] = balance[X]-100; balance[Z] = balance[Z]+100; } } 其中,atomic {}为子原子操作。试解释为什么雇员们在任何时候(同时)支、取、转帐时,这些事务操作总是安全有效的。 3、考虑如下使用lock 和unlock 的并行代码: parfor (i = 0;i < n ;i++){ noncritical section lock(S); critical section unlock(S); }
假定非临界区操作取T ncs时间,临界区操作取T cs时间,加锁取t lock时间,而去锁时间可忽略。则相应的串行程序需n( T ncs + T cs )时间。试问: ①总的并行执行时间是多少? ②使用n个处理器时加速多大? ③你能忽略开销吗? 4、计算两整数数组之内积的串行代码如下: Sum = 0; for(i = 0;i < N;i++) Sum = Sum + A[i]*B[i]; 试用①相并行;②分治并行;③流水线并行;④主-从行并行;⑤工作池并行等五种并行编程风范,写出如上计算内积的并行代码段。 5、图12.15示出了点到点和各种集合通信操作。试根据该图解式点倒点、播送、散步、收集、全交换、移位、归约与前缀和等通信操作的含义。 图12.15点到点和集合通信操作
第五章并行算法的一般设计策略 习题例题: 1、令n是待排序的元素数,p=2d是d维超立方中处理器的数目。假定开始随机选定主元x,并将其播送给所有其他处理器,每个处理器按索接收到的x,对其n/p个元素按照≤ x和>x 进行划分,然后按维进行交换。这样在超立方上实现的快排序算法如下: 算法5.6 超立方上快排序算法 输入:n个元素,B= n/p, d =log p 输出:按超立方编号进行全局排序 Begin (1)id=processor’s label (2)fori=1to d do (2.1) x = pivot/ * 选主元 * / (2.2) 划分B为B1和B2满足B1 ≤B<B2 (2.3)if第i位是零then (i) 沿第i维发送B2给其邻者 (ii)C =沿第i维接收的子序列 (iii) B=B1∪C else (i)沿第i维发送B1给其邻者 (ii) C=沿第i维接收的子序列 (iii) B= B2∪C endif endfor (3)使用串行快排序算法局部排序B= n/p个数 End ①试解释上述算法的原理。 ②试举一例说明上述算法的逐步执行过程。 2、①令T=babaababaa。P =abab,试用算法5.4计算两者的匹配情况。 ②试分析KMP算法为何不能简单并行化。 3、给定序列(33,21,13,54,82,33,40,72)和8个处理器,试按照算法5.2构造一棵为在PRAM-CRCW模型上执行快排序所用的二叉树。 4、计算duel(p, q)函数的算法如下: 算法5.7 计算串匹配的duel(p,q)的算法 输入:WIT〔1:n-m+1〕,1≤p 第五章并行算法的一般设计策略 习题例题: 1、令n是待排序的元素数,p=2d是d维超立方中处理器的数目。假定开始随机选定主元x,并将其播送给所有其他处理器,每个处理器按索接收到的x,对其n/p个元素按照≤ x和>x进行划分,然后按维进行交换。这样在超立方上实现的快排序算法如下: 算法5.6 超立方上快排序算法 输入:n个元素,B = n/p, d = log p 输出:按超立方编号进行全局排序 Begin (1)id = processor’s label (2)for i=1 to d do (2.1) x = pivot / * 选主元 * / (2.2) 划分B为B1和B2满足B1 ≤B<B2 (2.3) if第i位是零then (i) 沿第i维发送B2给其邻者 (ii) C = 沿第i维接收的子序列 (iii) B= B1∪C else (i) 沿第i维发送B1给其邻者 (ii) C = 沿第i维接收的子序列 (iii) B= B2∪C endif endfor (3)使用串行快排序算法局部排序B = n/p个数 End ①试解释上述算法的原理。 ②试举一例说明上述算法的逐步执行过程。 2、①令T = babaababaa。P =abab,试用算法5.4计算两者的匹配情况。 ②试分析KMP算法为何不能简单并行化。 3、给定序列(33,21,13,54,82,33,40,72)和8个处理器,试按照算法5.2构造一棵为在PRAM-CRCW模型上执行快排序所用的二叉树。 4、计算duel(p, q)函数的算法如下: 算法5.7 计算串匹配的duel(p, q) 的算法 输入:WIT〔1: n-m+1〕,1≤p<q≤n-m+1,(p - q) <m/2 输出:返回竞争幸存者的位置或者null(表示p和q之一不存在) Begin if p=null then duel= q else if q =null then duel= p else (1) j= q - p +1 并行编程模型 1.概述 并行编程模型是并行计算,尤其是并行软件的基础,也是并行硬件系统的导向。并行编程模型可以按照以下几种方式进行表述: (1)数据并行和任务并行:根据并行程序是强调相同任务在不同数据单元上并行,还是不同任务在相同或不同数据上实现并行执行,可以将并行性分为两类:数据并行和任务并行。由于数据并行能获得的并行粒度比任务并行高,因此可以扩展并行机上的大多数程序采取数据并行方式。但是任务并行在软件工程上有很重要的作用,它可以使不同的组件运行在不同的处理单元集合上,从而获得模块化设计。人们越来越趋向予将并行程序组织成为由数据并行组件组成的任务并行组合物。 (2)显式并行和隐式并行:并行编程系统可以根据支持显式或隐式并行编程模型来对其进行分类。显式并行系统要求编程人员直接制定组成并行计算的多个并发控制线程的行为;隐式并行系统允许编程人员提供一种高层的、指定程序行为但不显示表示并行的规范,它依赖于编译器或底层函数库来有效和正确地实现并行。越来越普遍的一种做法就是将算法设计的复杂性集成到函数库上,这样可以通过一系列对函数库的调用来开发应用程序。通过这种方式,可以在一种显式并行框架中获得隐式并行的某些好处。 (3)共享存储和分布存储:在共享存储模型中,程序员的任务就是指定一组通过读写共享存储进行通信的进程的行为。在分布存储模型中,进程只有局部存储,它必须使用诸如消息传递或远程过程调用等机制来交换信息。 很多多核处理器体系结构都同时支持这两种模型。 共享存储体系结构下的并行编程模型主要是共享变量编程模型,它具有单地址空间、编程容易、可移植性差等特点,其实现有OpenMP和Pthreads等。分布式存储体系结构下的并行编程模型主要有消息传递编程模型和分布式共享编程模型两种:消息传递编程模型的特点是多地址空间、编程困难、可移植性好,其实现有MPI, PVM等; 分布式共享编程模型是指有硬件或软件的支持,在分布式体系结构下实现的具有共享变量编程模型特点的编程模型。 后者可以分别按照硬件或软件的实现分为DSM和SVM,其实现有TreadMark和JiaJia等,目前研究热点的分割全局地址空间(PGAS)模型的研究有UPC等代表,具有很强的发展潜力。 2.并行编程模型的性的评价指标 (1)时间:程序串行运行时间是指在串行计算机上,程序从开始到运行结束所用的时间。并行运行程序是从并 行计算开始时刻到最后的处理器完成运算所经过的时间。 (2)总并行开销:并行系统的开销函数或总开销为由所有处理器话费的总时间,除去在单个处理器上求解相同 问题时最快的串行算法所需要的时间。所有处理器所用总时间减去完成有用工作所花费的时间,剩余部分即是开销。 (3)加速比:在单个处理器上求解问题所花的时间与用p个相同处理器并行计算机求解同一问题所花时间之比。 (4)效率:处理器被有效利用部分时间的度量,它定义为加速比与处理器数目的比率。在理想的并行系统中, 加速比等于p,效率等于1。实际上,加速比小于p而效率在0和1之间,它依赖于处理器被利用的效率。 (5)成本:并行运行时间与所用处理器数目的乘积。成本反映每个处理器求解问题所花费时间的总和。 另外,移植性、伸缩性和对各类语言的支持度也是评价指标。 3.影响并行编程模型性能的关键因素 多核处理器系统采用单芯片多处理器核的设计,这些处理器核相互独立,每个拥有一套完整的硬件执行环境,可以同时执行多道指令。在高速缓存设计方面,每个核拥有独立的片上缓存和共享的最后一级缓存。基于多核处理器的系统特征,影响并行程序性能的因素主要包括存储带宽、片上缓存一致性和负载均衡。 (1)存储带宽。在多核系统中,最后一级缓存是被各个核所共享的,如果位于同核上的多个线程同时对不同的数据集进行操作,将会导致最后一级缓存与主存之间频繁地传送数据。由于在主存和缓存之间传送数据的速度远小于CPU的计算速度,因此有限的存储带宽成为了影响多核环境下并行程序性能的瓶颈。 (2)片上缓存一致性。所谓片上缓存一致性,是指多核系统中各个核的片上缓存位于相同存储空间上的数据必须保持一致。虽然多核系统共享的cache体系结构在最后一级cache上减少了cache一致性问题,但由于每个核 中科院数学与系统科学研究院 “并行计算” 课程讲义(草稿)” 张林波 计算数学与科学工程计算研究所 科学与工程计算国家重点实验室 2003 年1月29 目录 第一部分MPI消息传递编程 第一章预备知识 §1.1 高性能并行计算机系统简介 §1.1.1 微处理器的存储结构 §1.1.2 Cache 结构对程序性能的影响 §1.1.3 共享内存SMP 型并行计算机 §1.1.4 分布式内存MP P 型并行计算机 §1.1.5 DSM 型并行计算机 §1.1.6 SMP/D SM 机群 §1.1.7 微机/1.4.作站机群 §1.1.8 TOP500 §1.2 并行编程模式 §1.2.1 自动并行与手1.4.并行 §1.2.2 0penMP §1.2.3 DSM 编程模式 §1.2.4 高性能Fortran: HPF §1.2.5 消息传递并行编程模式 §l.3 Unix 程序开发简介 §l.3.1 Unix中常用的编译系统 §1.3.2 实用1.4.具make §1.4 消息传递编程平台MPI §1.4.1 MPI 程序的编译与运行 §1.4.2 利用MPICH 建立MPI 程序开发与调试环境第二章MPI 基础知识 §2.1 下载MPI标准的PS 文档 §2.2 一些名词与概念 §2.3 编程模式 §2.4 MPI 函数的一般形式 §2.5 MPI 的原始数据类型 §2.5.1 Fortran 77 原始数据类型 §2.5.2 C 原始数据类型 §2.6 MPI 的几个基本函数 §2.6.1 初始化MPI 系统 §2.6.2 检测MPI 系统是否已经初始化 §2.6.3 得到通信器的进程数及进程在通信器中的序号§2.6.4 退出MPI 系统 §2.6.5 异常终止MPI 程序的执行 §2.6.6 查询处理器名称 §2.6.7 莸取墙上时间及时钟精度 §2.7 MPI 程序的基本结构 §2.7.1 Fortran 77 程序 §2.7.2 C 程序 第三章点对点通信 §3.1 标准阻塞型点对点通信函数 §3.1.1 标准阻塞发送 §3.1.2 阻塞接收 §3.1.3 阻塞型消息传递实例 §3.1.4 其它一些阻塞型消息传递函数 §3.2 消息发送模式 §3.2.1 阻塞型缓冲模式消息发送函数 §3.3 阻塞型与非阻塞型函数 §3.4 非阻塞型点对点通信函数 §3.4.1 非阻塞发送 §3.4.2 非阻塞接收 §3.4.3 通信请求的完成与检测 §3.4.4 通信请求的释放 §3.5 消息探测与通信请求的取消 §3.5.1 消息探测 §3.5.2 通信请求的取消 §3.6 点对点通信函数汇总 §3.7 持久通信请求 §3.7.1 创建持久消息发送请求 §3.7.2 创建持久消息接收请求 §3.7.3 开始基于持久通信请求的通信 §3.7.4 持久通信请求的完成与释放 第四章数据类型 §4.1 与数据类型有关的一些定义 §4.1.1 数据类型定义 §4.1.2 数据类型的大小 §4.1.3 数据类型的下界、上界与域 §4.1.4 MPI_LB 和MPI_UB §4.1.5 数据类型查询函数 §4.2 数据类型创建函数 §4.2.1 MPI_Type_contiguous §4.2.2 MPI_Type_vector §4.2.3 MPI_Type_hvector §4.2.4 MPI_Type_indexed §4.2.5 MPI_Type_hindexed并行算法的般设计策略
并行计算作业一·
并行算法讲义
相关主题
文本预览