
H.264概览
1. 引言
数字电视和DVD-video的出现使得广播电视和家庭娱乐发生了彻底的变革.越来越多的这些应用成为可能随着视频压缩技术的标准化.MPGE系列的下一个标准,MPEG4,正使得新一代的基于因特网的视频应用成为可能.而现在视频压缩的ITU-T H.263标准被广泛的应用于视频会议系统.
MPEG4(视频)和H.263都是基于视频压缩(视频编码)技术的标准(大约从1995年开始).运动图像专家组和视频编码专家组(MPEG和VCEG)致力于开发一个比MPEG4和H.263有更好性能的新标准,有着高品质,低比特视频流的特性一个更好的视频图像压缩方法.新标准"高级视频编码"(A VC)的历史可追溯到7年前.
1995年,为了通过电话线传输视频信号而制定的H.263标准定稿以后.ITU-T视频编码专家组(VCEG)就开始工作在两个更深入的发展领域:一个是"短期"的努力去增加H.263的额外特性(制定出标准的版本2),还有一个"长期"的努力,去开发一个适用于低比低率下可视通信的新标准,提供比之前的ITU-T标准更有效,明显更好的视频压缩方法.2001年,ISO运动图像专家组(MPEG)意识到H.26L的潜在优点,就组成了视频联合工作组(JVT),包括MPEG和VCEG的的专家.JVT的主要任务就是将H.26L"模式"草案发展成为一个完全的国际标准.实际上,结果产生了两个标准:ISO MPEG4第10部分和ITU-T H.264. 新标准的官方命名是"高级视频编码"(A VC);然而,旧的命名H.26L和以ITU文档号命名的IH.264[1]更广为人知.
2. H.264 编解码器
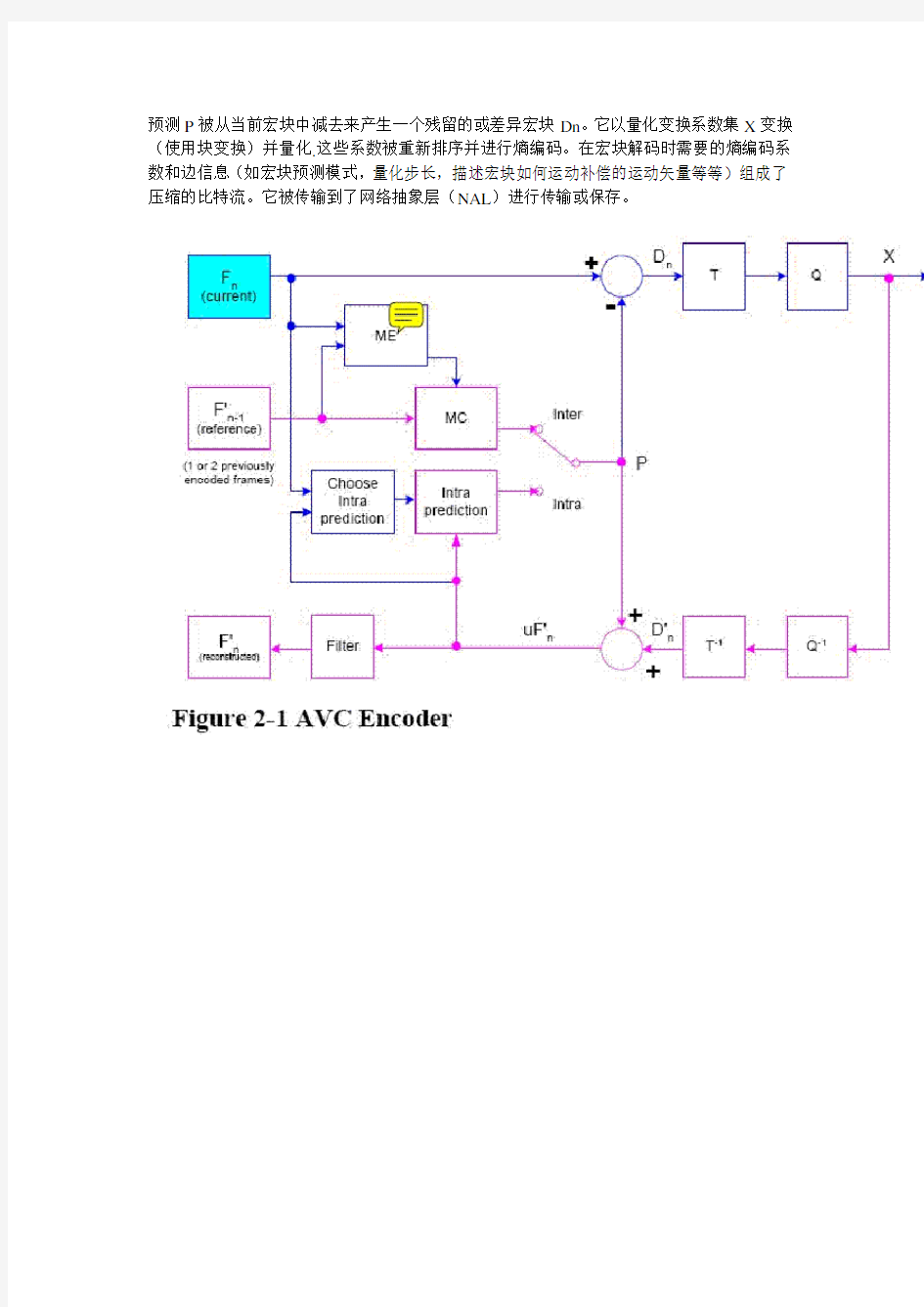
和之前的标准一样(如MPEG1,MPEG2和MPEG4),H.264标准草案并没有明确定义一个编解码器.在一定程度上,标准定义了视频比特流编码和与之相对应的解码方法的语法.然而实际上,一个符合的编码和解码器一般包括如图Figure 2-1 和Figure 2-2中所示的功能模块.同时这些图中所示功能通常是必须的,但编解码器还是可以有相当多的变种.基本的功能模块(预测,传输,量化,熵编码)与之前的标准(MPEG1,MPEG2,MPEG4,H.261,H.263)差不多.H.264的最重要的变化是在这些功能模块的实现细节上.
编码器包括两个数据流路径.一个"前向"路径(从左到右,以蓝色表示)和一个"重构"路径(从右到左,以洋红色表示).解码器的数据流路径以从右到左的方式表示,以此来说明编码器和解码器之间的相同点.
2.1 编码器(前向路径)
当一个输入帧Fn被提交编码。该帧以宏块(相当于16X16像素的原始图像)为单位来进行处理。每个宏块被编码成帧内模式或帧间模式。在这两种情况下,会产生一个基于重建帧的预测宏块P。在帧内模式下,P根据之前已经编码,解码,重建的当前帧n中的采样产生(图中以uF’n表示。注意是未经过滤的采样用来产生P)。在帧间模式下,P根据采用一个或多个参考帧的运动补偿预测来产生。在图中,参考帧表示为之前已经编码的帧F’n-1;然而,每个宏块的预测可能根据过去或将来(以时间为序)的一或多个已经编码并重构的帧来产生。
预测P被从当前宏块中减去来产生一个残留的或差异宏块Dn。它以量化变换系数集X变换(使用块变换)并量化.这些系数被重新排序并进行熵编码。在宏块解码时需要的熵编码系数和边信息(如宏块预测模式,量化步长,描述宏块如何运动补偿的运动矢量等等)组成了压缩的比特流。它被传输到了网络抽象层(NAL)进行传输或保存。
2.2 编码器(重建路径)
为了编码更进一步的宏块,需通过解码宏块量化系数X来重建一帧。系数X被重新调整(Q-1)并且进行逆变换(T-1)来产生一个不同的宏块Dn’,这与原始的差异宏块Dn不同;它在量化过程中有了损耗,所以D n’是Dn的一个失真版本。
预测宏块P被加到Dn’中来创建一个重建宏块uF’n(原始宏块的一个失真版本)。为了减少阻断失真的影响使用了一个滤镜,重建参考帧从一系列的宏块F’n中创建。
2.3 解码器
解码器从NAL(网络抽象层)接收压缩的比特流。数据元素被熵解码并且重新排列来产生一个量化系数集X。它们被重新调整并进行逆转换来生成D n’(与编码器中所示的Dn’相同)。使用比特流中解码出的头部信息,解码器生成一个预测宏块P,与在编码器中生成的原始预测帧P相同。P被加到Dn’中来生成uFn’,uF’n经过过滤生成了解码的宏块Fn’。
编码器的重建路径应该从图示和上面的讨论中清除,它实际上是为了确保编码器和解码器使用相同的参考帧来生成预测帧P。如果不这样做,编码器和解码器中的预测帧P就不会相同,导致编码器和解码器之间存在一个越来越大的误差或是“偏移”。
3.参考资料
1 ITU-T Rec. H.264 / ISO/IEC 11496-10, “Advanced Video Coding”, Final Committee Draft, Document JVTE022,September 2002
帧内宏块预测
1.引言
联合视频工作组(JVT)正在定案一个新的自然视频图像编码(压缩)标准。新标准被称为H.264或称作MPEG-4 Part 10、“高级视频编码(AVS)”。这篇文档描述了H.264编解码器中宏块帧内编码的方法。
如果一个块或宏块按帧内模式编码,会基于之前已经编码并重构(未过滤)的块生成一个预测宏块。这个预测块P被从之前已经编码的当前宏块中减去。对于亮度(luma)采样,P可能为每个4X4子块或16X16宏块产生。对于每个4X4的亮度块总共有9种可选的预测模式;对于16X16亮度块有4种可供选择的模式;而每个4X4的色度块只有一种预测模式(注:此处当理解成只有一种8X8的色度分块模式?)。
2.4X4亮度块预测模式
Figure 1显示在一个QCIF帧中的一个亮度宏块和一个需要进行预测的4X4的亮度块。该块左边和上边的采样(即像素对应值)已经被编码、重建并且因而能够在编码器和解码器中用来生成预测块。基于Figure 2中标识为A-M的采样计算出预测块P。注意在有些情况下,不是所有的采样A-M都在当前切片(即分块)中可用:为了保持切片解码的独立性,只有在当前切片中可用的采样才会用来进行预测。直流(DC)预测(模式2)根据A-M中的哪些采样可用来修改;其它模式(1-8)或许只能使用在所有预测中用到的采样都可用的情况(除了E,F,G,H 不可用的情况。这些值可从D中复制)。
Figure 3中的箭头标出了每种模式下预测的方向。在模式3-8中,预测值根据预测采样A-Q的加权平均来产生。编码器可能为每个块选择一种预测模式来减小P和被编码块之间的误差。
例:对Figure 1中所示的4X4块使用9种预测模式(0-8)计算。Figure 4显示了每种预测生成的预测块P。每种预测模式的绝对误差和(SAE)表明了预测误差的规模。在这种例子中,与实际当前块匹配最好的是模式7(垂直向左),因为这种模式给出了最小的SAE;经过视觉上的比较可以看出P块与原始的4X4块非常相似。
3. 16X16亮度块预测模式
16X16亮度块预测模式是一个上述4X4亮度块预测模式的一种替代方法,整个16X16的亮度块可以被预测。有四种模式可以使用。如Figure 5所示:
模式0(垂直):从块上部的采样推出(H)。
模式1(水平):从块左侧的采样推出(V)。
模式2(直流):从块上部和左侧的采样的均值推出(H+V)
模式3(平面):对块上部和左侧的采样H和V使用一个线性“平面”函数,这在平滑的亮度区域中效果最好。
例:
Figure 6 显示了一个左侧和上部采样已经编码的亮度宏块。预测结果(Figure 7)表明最佳匹配由模式3给出。帧内16X16模式在分布均匀的图像区域中效果比较好。
4. 8X8色度块预测模式
一个宏块的每个8X8的色度分量从之前已编码重构的上部和(或)左侧的色度采样中预测。色度块的四种预测模式和第3部分中描述(Figure 5所示)的16X16亮度块预测模式非常相似,除了模式号不同:直流(模式0),横向(模式1),垂直(模式2)和平面(模式3)。相同的预测模式在色度块中也始终适用(色度和亮度的相同预测模式的预测方法相同)。
注意:如果亮度分量中的8X8块被编码成帧内预测模式,色度块也要编码成帧内预测模式。
5.帧内预测模式编码
每个4X4块所选择的帧内预测模式必须传递给解码器,这就要求一个大量的位来存储。然而,相邻4X4块帧内预测模式高度相关。例如,如果Figure 8中的之前已经编码的4X4块A和B使用模式2,很可能块C(当前编码块)的最佳预测模式也是模式2。
对每个当前块C,编码器和解码器计算出最可能模式(most_probable_mode).如果A和B都使用了4X4帧内预测模式并且都包含在当前切片中,最可能模式就是A和B中模式号最小的预测模式;否则最可能模式设置为2(直流预测)。
编码器给每个4X4块发送标志use_most_probable_mode,如果标志为”1”,参数most_probable_mode被使用。如果标志为”0”,另一个参数
remaining_mode_selector被发送,表明需改变模式。如果
remaining_mode_selector比当前most_probable_mode小,预测模式就设置成remaining_mode_selector; 否则预测模式设置成remaining_mode_selector+1.采用这种方法,remaining_mode_selector只需使用8个值(0到7)来标志当前帧内预测模式(0到8)。
6.参考资料
1 ITU-T Rec. H.264 / ISO/IEC 11496-10, “Advanced Video Coding”, Final Committee Draft, Document JVTF100,
December 2002
2 Iain E G Richardson, “H.264 and MPEG-4 Video Compression”, John Wiley & Sons, to be published late
2003
P片帧间预测
1.引言
联合视频工作组(JVT)正在定案一个新的自然视频图像编码(压缩)标准。新标准[1]被称为H.264或称作MPEG-4 Part 10、“高级视频编码(AVS)”。这篇文档描述了H.264中以P-片来进行帧间预测编码的方法。
帧间预测从一个或多个之前已经编码的视频帧中生成一个预测模型。这个模型由对参考帧中的采样进行漂移产生(运动补偿预测)。AVC CODEC 使用基于块的运动补偿,与从H.261以来的主要编码标准中采用的规则相同。然而,它与早期标准有着重要的区别:(1)支持多种块大小(最小4X4)的预测;(2)细粒度的次像素运动矢量(量度分量可精确到1/4像素)。
2 树结构的运动补偿
AVC对亮度采样支持16X16到4X4之间多种块大小的运动补偿。每个宏块(16X16采样)的亮度分量能以Figure 2-1中所示的4种方式分割:16X16,16X8,8X16或8X8.每个细分区域是一个宏块分区。如果选择8X8分割模式,宏块内的四个8X8宏块分区都能够以4种方式再次分割,如图Figure 2-2所示:8X8,8X4,4X8或4X4(称作宏块子分区)。这些分区和子分区使得每个宏块内都可以有很多种组合方式。这种将宏块分割成不同大小运动补偿子块的方法称作树结构运动补偿。
每个分区或子分区都有一个独立的运动矢量。每个运动矢量必须编码并传输;另外,分区(分割方式)的选择也必须被编码到压流的比特流中。选择大的分区(如16X16,16X8,8X16)意味着只需很少的比特来标记运动矢量的选择和分区的类型;然而,运动补偿残差可能包含了大量的帧中高细节部分信息。选择一个小的分区大小(8X4,4X4等等)可以在运动补偿后得到一个较小的残差,但它需要更多的比特来标记运动矢量和分区的类型。因此分区大小的选择对压缩效果有着很大的影响。通常情况下,一个大的分区适用于帧内分布均匀的区域而一个小的分区将有利于细节区域的描述。
宏块(Cr和Cb)中每个色度分量的分辨率为亮度分量的一半。每个色度块和亮度块的分割方式相同,只是分区大小是水平和垂直方向的分辨率的一半(如一个8X16亮度分区对应一个4X8的色度分区;一个8X4亮度分区对应一个4X2的色度分区)。每个运动矢量(每个分区一个)的水平和垂直分量运用到色度块上时减半。
例:Figure 2-3显示了一个残留帧(未经过运动补偿)。AVC参考编码器为帧的每个部分选择了“最好的”分区大小。这种分区大小尽量减小编码残差和运动矢量。为每个区域选择的宏块分区显示在残留帧上(图示)。在帧间变化很小的区域(残留帧上显示为灰色)采用16X16分区方式;在运动的细节描述部分(残留帧上显示为黑色或白色)采用较小的分区效果更好。
3.次像素运动矢量
帧间编码宏块的每个分区根据参考图片中的一个相同大小的区域预测。两个区域间的偏移(运动矢量)的分辨率(亮度分量)为1/4像素。次像素位置的亮度和色度采样在参考图片中不存在,所以它们必须通过对附近的图像采样进行插补来创建。Figure 3-1给出了一个例子。当前帧(a)中的一个4X4的子分区根据参考图像的一个邻近区域来预测。如果运动矢量的水平和垂直分量为整数(b),则参考块中的相关采样实际已经存在(灰点)。如果一个或两个向量分量都为分数值(c),预测采样(灰点)根据参考帧中相邻采样(白点)间的插补产生。
次像素运动补偿的效果明显优于整数像素补偿,但是却增加了复杂性。1/4像素精度效果优于半像素精度。
在亮度分量中,半像素位置的次像素采样首先产生,它使用一个6头有限脉冲响应滤波器(6-tap Finite Impulse Response filter)从邻近的整数像素采样中插值。这意味着每个半像素采样是6个邻近整数采样的加权和。一旦所有的半像素采样可用,每个1/4像素采样通过对相邻的半像素和整数像素使用双线性插值得到。如果视频源采样比是4:2:0,色度分量需使用1/8像素采样(与亮度的1/4像素采样对应)。这些采样通过对整数像素的色度采样进行插值(线性插值)得到。
4.运动矢量预测
为每个分区编码一个运动矢量需要大量的比特,特别是在选择小的分区的时候。通常情况下邻近分区的运动矢量都高度相关,所以每个运动矢量可以通过相邻并且之前已经编码的分区的矢量预测。预测矢量MVp基于之前已计算出的运动矢量产生。当前矢量和预测矢量间的差异MVD被编码并传输。预测矢量MVp的生成方法取决于运动补偿块的大小和相邻矢量是否可用。“基本”预测值是当前分区或子分区相邻上部和对角线方向右下和相邻左侧的宏块分区或子分区的运动矢量的中间值。如果(a)选择16X8或8X16的分区并且(或者)(b)有些邻近分区不可用作预测值,则预测值会作出改变。如果当前宏块被跳过(未传输),则会产生一个预测矢量,即使宏块以16X16分区模式编码。
在解码器中,预测矢量MVp以相同的方式形成并加到解码后的矢量差异MVD中。若有跳过宏块,则这里没有解码矢量(MVD),这时会根据MVp的规模产生一个运动补偿宏块。
5.参考资料
1 ITU-T Rec. H.264 / ISO/IEC 11496-10, “Advanced Video Coding”, Final Committee Draft, Document JVTG050,March 2003
变换和量化
1.引言
联合视频工作组(JVT)正在定案一个新的自然视频图像编码(压缩)标准。新标准[1]被称为H.264或称作MPEG-4 Part 10、“高级视频编码(AVS)”。这篇文档描述了标准所定义或隐含的变换和量化过程。
每个残差宏块被传输,量化并编码。之前的标准如MPEG-1,MPEG-2,MPEG-4和H.263使用了8X8离散余弦变换(DCT)作为基本变换。H.264的基本规范使用三种变换,采用何种变换取决于被编码的残差数据:(1)对宏块内部(以16X16模式预测)的亮度直流系数4X4数组进行变换。(2)对(任何宏块中的)色度直流系数2X2数组进行变换(3)对所有其它的4X4块的残差数据进行变换。如果使用了“自适应块大小变换”选项,则根据运动补偿块大小(4X8,8X4,8X8,16X8等等)选择更进一步的变换。
宏块中的数据以图Figure 1-1中所示顺序进行传输。如果宏块以16X16帧内模式编码,则标注为“-1”的块(包含每个4X4亮度块的直流系数)首先被传输。然后,亮度残差块0-15按所示顺序传输(16X16宏块内部直流系数被设为0)。块16和块17各自包含一个来自色度分量Cb和Cr的2X2排列。最后,色度残差块18-25(直流系数为0)被发送。
2. 4X4残差变换和量化(块0-15,18-25)
在运动补偿预测和帧内预测后对4X4残差数据块(在Figure 1-1中标志为0-15和18-25)使用这个变换。这个变换基于DCT但是有一些基本的区别:
(1)它是一个整数变换(所有的操作可以用整数算术进行,没有降低精度)。
(2)逆变换在H.264标准中已经被充分描述,如果这个描述被正确的继承,那么编码器与解码器之间不应该存在不匹配。
(3)变换的核心部分是没有乘法的,即它只需进行加、减和移位。
(4)一个缩放乘法(完整变换的一部分)被融入到量化器中(减少了总的乘法次数)。
变换和量化的整个过程可以使用16位整数算术来进行,并且每个系数只乘一次,没有降低精度。
2.1 从4X4 DCT推出的整数变换
对一个输入阵列X进行4X4 DCT变换:
这里
这个矩阵乘法可以被分解成下面的等价形式(等式Equation 2-2)
CXC^T(即CXC’)是一个“核心”2-D变换。E是一个比例因子矩阵,并且符号⊕(圆圈中实为X号)表示(CXC’)的每个元素与E中对应位置的比例因子相乘(用点乘代替矩阵乘法)。常量a和b与之前值相等,d=c/b(近似于0.414).
为简化变换实现过程,d被近似成0.5。为了确保变换仍然正交,b也需要进行改变。所以
a=1/2 b=(2/5)^(1/2) d=1/2
矩阵C的第2行和第4行和矩阵C’的第2列和第4列以一个2为比例因子缩放(乘以2)并且后缩放矩阵E也被按比例缩小来进行补偿。(这就避免了核心变换CXC’中乘1/2的运算,使得使用整数算术运算不会降低精度)。最终的变换变成:
这个变换是4X4 DCT变换的一个近似变换。因为改变了因子d和b,所以新的变换的输出不会与4X4 DCT变换完全相同。
逆变换的形式为:
这次,Y的每个系数与矩阵Ei中对应位置的合适加权因子相乘,以此来进行预缩放。注意矩阵C和C’中的+/-(1/2)因子;它们可以通过一个右移来实现并且不会造成明显的精度损失,因为Y已经经过了预缩放。
正变换和逆变换都是正交的,即T^-1(T(X))=X.
2.2 量化
H.264使用了一个纯量量化器。它的定义和实现因为实际要求而变得复杂。它有以下要求:
(1)避免除法和(或)浮点算术运算。
(2)使上述的后缩放和预缩放矩阵Ef,Ei中的因子统一。
基本的正变换量化器操作如下:
Z ij = round(Y ij/Qstep)
Y ij是上述变换的一个系数,Qstep是量化步长,Z ij是一个量化系数。
标准支持的量化步长有52种,量化步长根据量化参数QP建立索引。每个量化参数对应的量化步长的值如表Table 2-1所示。注意QP每增加6,量化步长约增加一倍;QP每增加1,量化步长增加12.5%.各种各样的量化步长使得编码器可以精确,灵活的在比特率和质量之间权衡。亮度和色度的QP值可能不同,虽然
两个参数的变化范围都是0-51,但QP Chroma是从Q Py中得来的,QPc比QPy小,QPy 的值大于30。一个用户定义的QPy和QPc之间的偏移量或许可以从一个图像参数集中得到。
后缩放因子a^2,ab/2或b^2/4(Equation 2-3)是正量化器的一部分。首先,输入块X经过变换产生一个系数未经缩放的块W=CXC’。然后,每个系数Wij被量化并且缩放(在单一操作中)。
PF根据位置(i,j)来决定是为a^2,ab/2 或是b^2/4(如式Equation 2-3所示):
--------------------------------------------
Position PF
--------------------------------------------
(0,0),(2,0),(0,2),(2,2) a^2
(1,1),(1,3),(3,1),(3,3) b^2/4
其它 ab/2
------------------------------------------------------------------
因子(PF/Qstep)在H.264参考模型程序[3]中的实现方法是乘以MF(一个乘法因子)再进行一次右移,这样就避免了除法操作。
这里MF/2^qbits=PF/Qstep,qbits=15+floor(QP/6)
用整数算术,Equation 2-6可以用下述方法实现:
在这里>>代表二进值右移。在参考模型程序中,f在帧内块中等于2^qbits/3,在帧间块中等于2^qbits/6.
例:
设QP=4,则Qstep=1.0
(i,j)=(0,0),则PF=a^2=0.25
qbits=15,则2^qbits=32768
MF/2^qbits=PF/Qstep,则MF=(32768 X 0.25)/1=8192
根据QP和系数位置(i,j)值,MF的一组值(每组6个)如表Table 2-2所示:
Table 2-2 Multiplication Factor MF
表中第二列和第三列(因子为b^2/4和ab/2的位置)的值对Equaton 2-6的结果做了些小的修改(因为只有逆量化过程被标准化,所以为提高解码器的可感质量而改变一个前置量化器是可以接受的)。
QP>5的时候,MF因子保持不变(以6为周期重复上表)但是QP每增加6,除数2^qbits增加一倍。例如,当6<=QP<=11时,qbits=16;12<=QP<=17时,qbits=17
等等。
2.3 改变标度(逆量化)
逆量化操作如下:
Y’ij = Z ij.Qstep
Equation 2-8
逆变换中的预缩放因子(矩阵Ei,对应于系数位置值分别为a^2,ab和b^2)也是这个操作的一部分,同时增加了一个为64的常量比例系数来避免舍入错误。
W’ij = Z ij.Qstep.PF.64
Equation 2-9
比例系数W’ij随后使用“核心”逆变换(Ci’WCi: 如Equation 2-4)进行变换。逆变换的输出值被除以64来除去比例因子(这可以通过一次加法和一次右移来实现)。
H.264标准没有直接指明Qstep或PF,而0<=QP<=5时每个系数位置的参数V=(Qstep.PF.64)被定义。逆量化操作为:
W’ij = Z ij.Vij.2^floor(QP/6)
Equation 2-10
例:
设QP=3,则Qstep=0.875,2^floor(Qp/6)=1
(i,j)=(1,2),则PF=ab=0.3162
V=(Qstep.PF.64)=0.875X0.3162X65 =18(近似值)
W’ij=Zij X 18 X 1
0<=QP<=5时V的值在标准中的定义如下表:
Table 2-3 Rescaling factor V
【中文版】以太坊白皮书 翻译:少平、Seven 当中本聪在2009 年1 月启动比特币区块链时,他同时向世界引入了两种未经测试的革命性的新概念。第一种就是比特币(bitcoin),一种去中心化的点对点的网上货币,在没有任何资产担保、内在价值或者中心发行者的情况下维持着价值。到目前为止,比特币已经吸引了大量的公众注意力,就政治方面而言它是一种没有中央银行的货币并且有着剧烈 的价格波动。然而,中本聪的伟大试验还有与比特币同等重要的一部分:基于工作量证明的区块链概念使得人们可以就交易顺序达成共识。作为应用的比特币可以被描述为一个先申请(first-to-file)系统:如果某人有50BTC 并且同时向A 和B 发送这50BTC,只有被首先被确认的交易才会生效。没有固有方法可以决定两笔交易哪一笔先到,这个问题阻碍了去中心化数字货币的发展许多年。中本聪的区块链是第一个可靠的去中心化解决办法。现在,开发者们的注意力开始迅速地转向比特币技术的第二部分,区块链怎样应用于货币以外的领域。 常被提及的应用包括使用链上数字资产来代表定制货币和
金融工具(彩色币),某种基础物理设备的所有权(智能资产),如域名一样的没有可替代性的资产(域名币)以及如去中心化交易所,金融衍生品,点到点赌博和链上身份和信誉系统等更高级的应用。另一个常被问询的重要领域是“智能合约”- 根据事先任意制订的规则来自动转移数字资产的 系统。例如,一个人可能有一个存储合约,形式为“A 可以每天最多提现X 个币,B 每天最多Y 个,A 和B 一起可以随意提取,A 可以停掉B 的提现权”。这种合约的符合逻辑的扩展就是去中心化自治组织(DAOs)- 长期的包含一个组织的资产并把组织的规则编码的智能合约。以太坊的目标就是提供一个带有内置的成熟的图灵完备语言的区块链,用这种语言可以创建合约来编码任意状态转换功能,用户只要简单地用几行代码来实现逻辑,就能够创建以上提及的所有系统以及许多我们还想象不到的的其它系统。 总之,我们相信这样的设计是迈向“加密货币2.0”的坚实一步;我们希望以太坊的出现之于加密货币生态系统的标志性意义,正如1995 年前后Web2.0 之于互联网。 历史 去中心化的数字货币概念,正如财产登记这样的替代应用一样,早在几十年以前就被提出来了。1980 和1990 年代的匿名电子现金协议,大部分是以乔姆盲签技术(Chaumian blinding)为基础的。这些电子现金协议提供具有高度隐私性
H.264概览 1. 引言 数字电视和DVD-video的出现使得广播电视和家庭娱乐发生了彻底的变革.越来越多的这些应用成为可能随着视频压缩技术的标准化.MPGE系列的下一个标准,MPEG4,正使得新一代的基于因特网的视频应用成为可能.而现在视频压缩的ITU-T H.263标准被广泛的应用于视频会议系统. MPEG4(视频)和H.263都是基于视频压缩(视频编码)技术的标准(大约从1995年开始).运动图像专家组和视频编码专家组(MPEG和VCEG)致力于开发一个比MPEG4和H.263有更好性能的新标准,有着高品质,低比特视频流的特性一个更好的视频图像压缩方法.新标准"高级视频编码"(A VC)的历史可追溯到7年前. 1995年,为了通过电话线传输视频信号而制定的H.263标准定稿以后.ITU-T视频编码专家组(VCEG)就开始工作在两个更深入的发展领域:一个是"短期"的努力去增加H.263的额外特性(制定出标准的版本2),还有一个"长期"的努力,去开发一个适用于低比低率下可视通信的新标准,提供比之前的ITU-T标准更有效,明显更好的视频压缩方法.2001年,ISO运动图像专家组(MPEG)意识到H.26L的潜在优点,就组成了视频联合工作组(JVT),包括MPEG和VCEG的的专家.JVT的主要任务就是将H.26L"模式"草案发展成为一个完全的国际标准.实际上,结果产生了两个标准:ISO MPEG4第10部分和ITU-T H.264. 新标准的官方命名是"高级视频编码"(A VC);然而,旧的命名H.26L和以ITU文档号命名的IH.264[1]更广为人知. 2. H.264 编解码器 和之前的标准一样(如MPEG1,MPEG2和MPEG4),H.264标准草案并没有明确定义一个编解码器.在一定程度上,标准定义了视频比特流编码和与之相对应的解码方法的语法.然而实际上,一个符合的编码和解码器一般包括如图Figure 2-1 和Figure 2-2中所示的功能模块.同时这些图中所示功能通常是必须的,但编解码器还是可以有相当多的变种.基本的功能模块(预测,传输,量化,熵编码)与之前的标准(MPEG1,MPEG2,MPEG4,H.261,H.263)差不多.H.264的最重要的变化是在这些功能模块的实现细节上. 编码器包括两个数据流路径.一个"前向"路径(从左到右,以蓝色表示)和一个"重构"路径(从右到左,以洋红色表示).解码器的数据流路径以从右到左的方式表示,以此来说明编码器和解码器之间的相同点. 2.1 编码器(前向路径) 当一个输入帧Fn被提交编码。该帧以宏块(相当于16X16像素的原始图像)为单位来进行处理。每个宏块被编码成帧内模式或帧间模式。在这两种情况下,会产生一个基于重建帧的预测宏块P。在帧内模式下,P根据之前已经编码,解码,重建的当前帧n中的采样产生(图中以uF’n表示。注意是未经过滤的采样用来产生P)。在帧间模式下,P根据采用一个或多个参考帧的运动补偿预测来产生。在图中,参考帧表示为之前已经编码的帧F’n-1;然而,每个宏块的预测可能根据过去或将来(以时间为序)的一或多个已经编码并重构的帧来产生。
FIDIC业主/咨询工程师标准服务协议书条件 (白皮书) 业主/咨询工程师标准服务协议书(协议书) 业主/咨询工程师标准服务协议书条件(第一部分标准条件) 业主/咨询工程师标准服务协议书条件(第二部分特殊应用条件) 业主/咨询工程师标准服务协议书条件(第二部分附注)
业主/咨询工程师标准服务协议书(协议书) 兹就以下事项达成本协议: 1.本协议书中的措词和用语应与下文提及的“业主/咨询工程师标准服务协议书条件”中分别赋予它们的含义相同。 2.下列文件应被认为是组成本协议书的一部分,并应被作为其一部分进行阅读和理解,即: (1)中标函; (2)业主/咨询工程师标准服务协议书条件(第1部分——标准条件和第2部分——特殊应用条件); (3)附件,即 附件A——服务范围 附件B——业主提供的职员、设备、设施和其他人员的服务 附件C——报酬和支付 3.考虑到下文提及的业主对咨询工程师的支付,咨询工程师在此答应业主遵照本协议书的规定履行服务。 4.业主在此同意按本协议书注明的期限和方式,向咨询工程师支付根据协议书规定应付的款项似此作为履行服务的报酬。 本协议书谨于前文所载明之年月日,由立约双方根据其有关的法律签署并开始执行。 特此证明。
业主/咨询工程师标准服务协议书条件(第一部分标准条件) 定义及解释 1.定义 下列名词和用语,除上下文另有要求者外,应具有所赋予它们的涵义: (1)“项目”是指第二部分中指定的并为之建造工程的项目。 (2)“服务”是指咨询工程师根据协议书所履行的服务,含正常的服务、附加的服务和额外的服务。 (3)“工程”是指为完成项目所实施的永久工程(包括提供给业主的物品和设备)。 (4)“业主”是指本协议书所指的雇用咨询工程师的一方以及业主的合法继承人和允许的受让人。 (5)“咨询工程师”是指本协议书中所指的,作为一个独立的专业公司接受业主雇用履行服务的一方以及咨询工程师的合法继承人和允许的受让人。 (6)“一方”和“各方”是指业主和咨询工程师。“第三方”是指上下文要求的任何其他当事人或实体。 (7)“协议书”是指包括业主/咨询工程师标准服务协议书第一、二部分的条件以及附件A(服务范围),附件B(业主提供的职员、设备、设施和其他人员的服务),附件C(报酬和支付),中标函和正式协议书(如果已签订),或第二部分中的其他规定。 (8)“日”是指任何一个午夜至下一个午夜间的时间段。 (9)“月”是指根据阳历从一个月份中任何一天开始的一个月的时间段。 (10)“当地货币”(LC)是指项目所在国的货币,“外币”(FC)是指任何其他的货币。 (11)“商定的补偿”是指第二部分中规定的根据协议书应支付的额外款项。 2.解释 (1)本协议书中的标题不应在其解释中使用。 (2)单数包含复数含义,阳性包含阴性含义。视上下文需要而定,反之亦然。 (3)如果协议书中的规定之间产生矛盾,按年月顺序以最后编写的为准。 咨询工程师的义务 3.服务范围 咨询工程师应履行与项目有关的服务。服务的范围在附件A中规定。 4.正常的、附加的和额外的服务 (1)正常的服务是指附件A中所述的那类服务。 (2)附加的服务是指附件A中所述的那类或通过双方的书面协议另外附加于正常服务的那类服务。 (3)额外的服务是指那些既不是正常的也不是附加的,但根据第28条咨询工程师必须履行的那类服务。 5.认真地尽职和行使职权 (1)咨询工程师在根据本协议书履行其义务时,应运用合理的技能、谨慎而勤奋地工作。 (2)当服务包括行使权力或履行授权的职责或当业主与任何第三方签订的合同条款需要时,咨询工程师应: ①根据合同进行工作,如果未在附件A中对该权力和职责的详细规定加以说明,则这些详细规定必须是他可以接受的。 ②在业主和第三方之间公正地证明、决定或行使自己的处理权,如有此授权的话。但不作为仲裁人而是根据自己的职能和判断,作为一名独立的专业人员进行工作。 ③可变更任何第三方的义务,如有此授权的话。但对于可能对费用或质量或时间产生重大影响的任何变更,须从业主处得到事先批准(除非发生任何紧急情况,此时咨询工程师应尽快通知业主)。 6.业主的财产 任何由业主提供或支付费用的供咨询工程师使用的物品都属于业主的财产,并在实际可行时应如此标明。当服务完成或终止时,咨询工程师应将履行服务中未使用的物品的库存清单提交给业主,并按业主的指示移交此类物品。此类移交应被视为附加的服务。 业主的义务 7.资料
软件定义网络:网络新规范 内容表 2摘要 3新的网络架构的需求 4当前网络技术的局限性 7引入软件定义网络 8 OpenFlow内部 10基于OpenFlow的软件定义网络的好处 12结论 摘要 传统的网络体系结构已经不适应当今企业、运营商和终端用户的需求。由于行业的广泛努力,开放网络基金会(ONF)带头,软件网络(SDN)正在改变网络架构。在SDN架构中,控制平面和数据平面解耦,网络智能和状态逻辑上集中,底层网络基础设施从应用中抽象出来。因此,企业和运营商获得前所未有的可编程性,自动化和网络控制,使他们能够建立高度可扩展的、灵活的网络,迅速适应不断变化的业务需求。 ONF是一个非营利性的行业协会,引领SDN的发展和规范SDN架构的关键要素如OpenFlow?协议,它支持的网络设备的控制和数据层之间结构通信。OpenFlow是专为SDN 设计的第一标准接口,提供高性能、颗粒流量控制通过多个厂商的网络设备。 基于OpenFlow的SDN目前正在推出各种网络设备和软件,为企业和运营商提供大量的好处,包括: ●集中管理和控制多个供应商的网络设备; ●改进的自动化和管理,通过使用通用的API,从业务流程和配置系统和应用程序中抽象 基本网络细节; ●通过提供新的网络功能和服务,而不需要配置单个设备或等待供应商发布的能力快速创 新; ●可编程性通过运营商、企业,独立软件供应商,和用户(不只是设备制造商)使用常见 的编程环境,为各方提供推动收入和分化的新机会; ●由于网络设备的集中和自动化管理,统一的政策执行,以及较少的配置错误,增加了网 络的可靠性和安全性; ●在会话、用户、设备和应用程序级别上应用全面和广泛的政策的能力实现更细粒度的网 络控制; ●有更好的终端用户体验,作为应用程序利用集中的网络状态信息无缝地适应网络行为满 足用户需求。 SDN是一个动态的、灵活的网络结构,保护现有投资,未来的网络。使用SDN,今天的静态网络可以演变成一个能够快速响应不断变化的业务,最终用户,与市场需求的可扩展的服务交付平台。 一个新的网络体系结构的必要性 移动设备和内容的爆炸,服务器虚拟化,云服务出现的趋势推动了网络产业重新审视传统的网络架构中。许多传统的网络是分层的,以太网交换机以树结构布置。这种设计是有意义的,当客户端-服务器计算是占主导地位,但这样的静态架构是不适合今天的企业数据中心,校园,和运营商的环境的动态计算和存储需求的。一些关键的计算趋势推动了对一个新的网络模式的需要,包括:
STP技术白皮书
目录 1 概述 (2) 1.1 STP技术回顾 (2) 1.1.1 IEEE 802.1D STP (2) 1.1.2 IEEE 802.1w RSTP (3) 1.1.3 PVST+ (4) 1.1.4 IEEE 802.1s MSTP (5) 1.2 华为3COM支持的STP类型 (5) 2 华为3COM STP特性及相关技术 (5) 2.1 RSTP模块到MSTP模块的平滑升级 (5) 2.2 MSTP模块的RSTP模式 (6) 2.3 PATH COST缺省值的计算 (6) 2.4 指定根桥和根桥备份 (8) 2.5 BPDU PROTECTION (9) 2.6 ROOT PROTECTION (9) 2.7 LOOP PROTECTION (10) 2.8 TC PROTECTION (10) 2.9 设置交换机的超时时间因子 (10) 2.10 CONFIGURA TION DIGEST SNOOPING (11) 2.11 NO AGREEMENT CHECK (13) 2.12支持802.1s MSTP标准报文格式 (14) 2.13 BPDU TUNNEL (1) 3 互通情况 (1) 3.1 STP、RSTP和MSTP的互通 (1) 3.2 STP/RSTP/MSTP和PVST+的互通 (2) 3.3 华为3COM MSTP和CISCO MSTP的域内互通 (3) 4 附录 (3) 4.1 RSTP模块缺省配置 (3) 4.2 MSTP模块缺省配置 (4)
1 概述 1.1 STP技术回顾 在二层交换网络中,交换机并不能像路由器那样知道报文可以经过多少次转发,一旦网络存在环路就会造成报文在环路内不断循环和增生,产生广播风暴。在广播风暴的情况下,所有的有效带宽都被广播风暴占用,网络将变得不可用。 在这种环境下STP协议应运而生,STP(Spanning Tree Protocol)是生成树协议的英文缩写。它是一种二层管理协议,它通过有选择性地阻塞网络冗余链路来达到消除网络二层环路的目的,同时具备链路的备份功能。 STP协议和其他协议一样,是随着网络的不断发展而不断更新换代的。在STP的发展过程中,老的缺陷不断被克服,新的特性不断被开发出来。最初被广泛应用的是IEEE 802.1D STP,随后以它为基础产生了IEEE 802.1w RSTP、PVST+、IEEE 802.1s MSTP,下面将分别讨论。 另外,STP包含了两个含义,狭义的STP是指IEEE 802.1D中定义的STP协议,广义的STP是指包括IEEE 802.1D STP以及各种在它基础上经过改进了的生成树协议。 1.1.1 IEEE 80 2.1D STP STP协议的基本思想十分简单。自然界中生长的树是不会出现环路的,如果网络也能够像一棵树一样生长就不会出现环路。于是,STP协议中定义了根桥(Root Bridge)、根端口(Root Port)、指定端口(Designated Port)、路径开销(Path Cost)等概念,目的就在于通过构造一棵树的方法达到裁剪冗余环路的目的,同时实现链路备份和路径最优化。用于构造这棵树的算法称为生成树算法SPA(Spanning Tree Algorithm)。 要实现这些功能,网桥之间必须要进行一些信息的交互,这些信息交互单元就称为配置消息BPDU(Bridge Protocol Data Unit)。STP BPDU是一种二层报文,目的MAC是多播地址01-80-C2-00-00-00,所有支持STP协议的网桥都会接收并处理收到的BPDU报文。该报文的数据区里携带了用于生成树计算的所有有用信息。 STP的工作过程是:首先进行根桥的选举。选举的依据是网桥优先级和网桥MAC地址组合成的桥ID,桥ID最小的网桥将成为网络中的根桥,它的所有端口都连接到下游桥,所以端口角色都成为指定端口。接下来,连接根桥的下游网桥将各自选择一条“最粗壮”的树枝作为到根桥的路径,相应端口的角色就成为根端口。循环这个过程到网络的边缘,指定端口和根端口确定之后一棵树就生成了。生成树经过一段时间(默认值是30秒左右)稳定
Sakai3白皮书 【摘要】此文档陈述了下一代Sakai合作学习环境的目标。试图表达在Sakai社区中的大多数人关于Sakai将去向何方的思想。 介绍:Sakai3的由来 Sakai的重要变化时刻即将来到,正如投资大学和Mellon基金会所预想的那样,目前的系统已经成功的使世界各地的高校在社区资源合作中受益,但从Sakai 成立以来,变化一直不断。越来越熟悉Web2.0的Sakai的终端用户,正要求着一个更加自由并且给予他们更多的控制权的环境。社交网络目前已经得到广泛推广。实践证明利用Sakai进行研究、合作学习和行政合作是极其有价值的。Sakai 可以运用和整合的新的标准和开放资源项目相继出现,新的网络开发模型已经出现,这种模型充分利用了客户端的技术,极大的改善了效率,面向服务的框架已经作为公共机构一项设计和部署的优先选择而出现。最重要的是,传统的课程管理系统和电子学档的角色正迅速的变化,而且,有一个广泛的共识,那就是目前的平台要经历巨大的演变从而达到用户和公共机构的长远需求。 Sakai团队也已经学会很多。逐渐做出的越来越多的适应性调整,已经揭示了用例的范围和复杂程度,而且越来越明确的是,一部分代码将会在众多人的重写中被优化,从而降低维护开销,同时又能保持满足本地化需要的自由度。随着公共机构多年来在更多领域运用Sakai,将“网站”作为Sakai的原则的局限性越来越明显。代码和数据库的运转压力已经被确认到,并且经历了显著的改善。但是,运用目前的架构我们到达了受益递减点。Sakai实施的SOA (Service-Oriented Architecture)在实践中被证实是十分的有价值的,可以将其改进到符合现行标准,并且使它最大化的与像Kuali等新项目相融。最后,校园里的Java开发者的相对弱点使Sakai编程的简单化势在必行,进而将Sakai面向一个更加宽广的开发群体,并增加我们作为一个团队的创新能力。 概括的说,我们的目标不仅仅是Sakai的改善,更不是抄袭Google。我们的目标不简单的是创造另一个更好更便宜的Blackboard新版本。是时候明确这一点了:Sakai应利用已经建立的开放资源集中力量发展专门针对教育的需求。总之,我们应该努力创建一个不同的学术合作系统。我们将选择运用Sakai3的公共机构来运行一个本质上不同的系统。这是我们应该向教育领域提供的善举。并不只是在开放资源和私有资源之间做出选择。 基于以上原因,一个由剑桥,Georgia Tech 、 UC Davis 并且包括Indiana, Michigan, Toronto, Berkeley 和the Sakai基金会率领的公共机构团队,已经开始为下一代Sakai的开发拟定设想与初步技术方案。下一代Sakai将会基于一系列新的Sakai内核,该种内核充分利用开放资源(例如 Jackrabbit 和 Shindig),来使资源开发专注于真正关于学术合作。下一代Sakai将会呈现一个新的、以用户为中心的界面,这种界面使用起来既简单又舒适。而且它将包括新的功能,例如包括当今的用户所期待的社交网络和自由内容创作。 这个核心小组已经有了成绩了。新内核的概貌已经显现。设计工作已经开始了新的用户体验。关于Sakai诸多方面新概念正在被讨论和分析。虽仍存在一些有待从概念和技术上进一步斟酌之处,但是前进的方向却越来越清晰。下文提供
摘要 5G致力于应对2020后多样化差异化业务的巨大挑战,满足超高速率、超低时延、高速移动、高能效和超高流量与连接数密度等多维能力指标。FuTURE论坛5G 特别兴趣组(SIG)围绕着“柔性、绿色、极速”的5G愿景,以“5+2”技术理念,重新思考5G网络的设计原则: 1)香农理论再思考(Rethink Shannon):为无线通信系统开启绿色之旅 2)蜂窝再思考(Rethink Ring & Young):蜂窝不再(no more cell) 3)信令控制再思考(Rethink signaling & control):让网络更智能 4)天线再思考(Rethink antennas):通过SmarTIle让基站隐形 5)频谱空口再思考(Rethink spectrum & air interface):让无线信号“量体裁衣”,以及 6)前传再思考(Rethinking fronthaul):通过下一代前传接口(NGFI)实现柔性无线接入网(RAN) 7)协议栈再思考(Rethinking the protocol stack):实现差异化接入点灵活配置以及BBU和远端无 线系统功能优化 围绕上述理念,FuTURE论坛5G SIG 在5G网络架构、RAN和空口研发方面的取得了显著进展,本白皮书对相关成果做出总结,特别介绍了用户中心网络(UCN)和软件定义空口(SDAI)两个核心概念。UCN架构有如下四个特征: ?RAN重构:为充分利用多样化的接入技术组合、提升组网效率,传统的蜂窝边界将允许动态重构调整、传统的协议栈以及基带功能将被切分并以最优的方式分布在重构的RAN网络节点和相关子系统上; ?边缘提升:以支持超低的端到终端延迟(低至1ms),高效的数据分流、分发、本地移动性、各种边缘业务(包括RAN上下文开放使能的跨层优化),以及移动边缘云; ?CN-RAN再划分:以支持融合多制式技术、低的端到端延迟(不超过10ms),并充分利用控制转发分离(SDN)和软硬件解耦(NFV)的优点; ?网络切片即服务:支持通过SDN/ NFV实现多个垂直子平台,并能够通过一种更强大的水平平台实现多个垂直子平台的融合;对于有效地满足“互联网+”的挑战和机遇,具有重要意义。 SDN, NFV, C-RAN, NGFI, UDN, Multi-RAT/RIT, D2D和灵活网络切片是UCN核心技术。大数据分析也是UCN动态特性不可缺少的部分。
当今的互联网正处于一股浪潮之中:中心专有式服务正逐渐被去中心式服务所取代;中心式信任方逐渐被可验证式分布计算取代;脆弱的位置寻址逐渐被弹性的内容寻址取代;低效的整体服务逐渐被点对点算法市场取代。比特币、以太坊及其他区块链产品已经证明了去中心化交易分账的有效性。这些公共账本可以处理精密而智能的合同,以加密的方式交易价值数百亿美金的资产。这些系统是开放式互联网最早的实体,去中心化网络的参与者们在没有中心管理或 中心式信任方的情况下,提供了很有用处的支付服务。IPFS通过对全球性点对 点网络所使用的数十亿文件提供服务,证明了去中心化网络中内容寻址的效用。 Filecoin是一个去中心化的存储网络,它可以将云存储转变为算法市场。这个市场运作在一个拥有本地协议记号(也叫做“Filecoin”)的区块链上,在这个市场上,矿工们通过对客户提供存储服务赚取Filecoin。相对地,客户可以使用Filecoin来雇佣矿工存储或分发数据。同比特币相似,Filecoin矿工们会为了追求回报而竞相开采区块,但Filecoin的开采能力与存储积极性正相关,这可以 为客户提供更有效用的服务(而不像比特币,为了维持区块链的一致性而限制其效用)。如此就激励了矿工们尽可能多地积累存储空间并租借给客户。本协议可以将积累起来的资源组织成任何人都可信赖的、有自愈功能的存储网络。这个网络通过复制和分发内容建立自身的鲁棒性,同时还可以自动侦测和修复复制错误。客户可以通过选择复制参数防范不同的风险类型。由于协议在客户方对内容进行了端对端加密,存储空间的提供者无法得到密匙,所以这种云存 储网络可以提供足够的安全性。Filecoin作为IPFS顶端的激励层,可以为任意 数据提供存储架构,在保存去中心化数据、构建和运行分发应用以及执行智能合约的情况下格外有用。 本文包含以下内容: ?介绍Filecoin网络,概述协议并详细介绍几个重要组件。 ?概述去中心化网络(DSN)的方案和特点,然后通过Filecoin构建一个 DSN。 ?基于存储证明方案,介绍一个名为“复制证明”的新方案,该方案可以使任意的复制数据储存在独立的物理空间中。
TEE 白皮书 The Trusted Execution Environment: Delivering Enhanced Security at a Lower Cost to the Mobile Market 2010年2月 翻译:min.zhao@https://www.doczj.com/doc/183133065.html, W A T C H D A T A
目录 目录 .................................................................................................................................................. 2 概述 .................................................................................................................................................. 3 第一章:移动设备的安全需求. (3) 1.1安全需求的演化 ............................................................................................................... 3 1.2参与者的安全视角............................................................................................................ 5 第二章:TEE 介绍 ........................................................................................................................... 6 第三章:TEE 的位置 ....................................................................................................................... 7 第四章:使用场景 .. (9) 4.1企业应用 ........................................................................................................................... 9 4.2内容管理 ......................................................................................................................... 10 4.3移动支付 ......................................................................................................................... 10 4.4.服务发布 (11) 4.4.1. 服务发布........................................................................................................... 11 4.4.2. 服务管理........................................................................................................... 11 4.4.3. 举例:企业应用的服务发布 (12) 第五章:为什么将TEE 标准化..................................................................................................... 12 第六章:TEE 修订规划 ................................................................................................................. 12 第七章:总结 ................................................................................................................................ 13 附录A :术语与缩写 ..................................................................................................................... 14 附录B :名词定义 ......................................................................................................................... 14 附录C :Rich OS, TEE 和SE 的比较 . (15) W A T C H D A T A
Sakai3白皮书(中文版) 【摘要】此文档陈述了下一代Sakai互助学习环境的方针试图抒发在Sakai社区中的大多数人关于Sakai将去的方向何方的思惟 介绍:Sakai3的由来 Sakai的重要变化时刻即将来到,正如投资大学和Mellon基金会所预想的那样,目前的系统已经成功的使世界各地的高校在社区资源合作中受益,但从Sakai成立以来,变化一直不断。越来越熟悉Web2.0的Sakai的终端用户,正要求着一个更加自由并且给予他们更多的控制权的环境。社交网络目前已经得到广泛推广。实践证明利用Sakai进行研究、合作学习和行政合作是极其有价值的。Sakai可以运用和整合的新的标准和开放资源项目相继出现,新的网络开发模型已经出现,这种模型充分利用了客户端的技术,极大的改善了效率,面向服务的框架已经作为公共机构一项设计和部署的优先选择而出现。最重要的是,传统的课程管理系统和电子学档的角色正迅速的变化,而且,有一个广泛的共识,那就是目前的平台要经历巨大的演变从而达到用户和公共机构的长远需求。 Sakai团队也已经学会很多。逐渐做出的越来越多的适应性调整,已经揭示了用例的范围和复杂程度,而且越来越明确的是,一部分代码将会在众多人的重写中被优化,从而降低维护开销,同时又能保持满足本地化需要的自由度。随着公共机构多年来在更多领域运用Sakai,将“网站”作为Sakai的原则的局限性越来越明显。代码和数据库的运转压力已经被确认到,并且经历了显著的改善。但是,运用目前的架构我们到达了受益递减点。Sakai实施的 SOA(Service-Oriented Architecture)在实践中被证实是十分的有价值的,可以将其改进到符合现行标准,并且使它最大化的与像Kuali等新项目相融。最后,校园里的 Java开发者的相对弱点使Sakai编程的简单化势在必行,进而将Sakai面向一个更加宽广的开发群体,并增加我们作为一个团队的创新能力。 概括的说,我们的目标不仅仅是Sakai的改善,更不是抄袭Google。我们的目标不简单的是创造另一个更好更便宜的Blackboard新版本。是时候明确这一点了: Sakai应利用已经建立的开放资源集中力量发展专门针对教育的需求。总之,我们应该努力创建一个不同的学术合作系统。我们将选择运用Sakai3的公共机构来运行一个本质上不同的系统。这是我们应该向教育领域提供的善举。并不只是在开放资源和私有资源之间做出选择。 基于以上原因,一个由剑桥,Georgia Tech 、 UC Davis 并且包括 Indiana, Michigan, Toronto, Berkeley 和the Sakai基金会率领的公共机构团队,已经开始为下一代 Sakai的开发拟定设想与初步技术方案。下一代Sakai将会基于一系列新的Sakai内核,该种内核充分利用开放资源(例如 Jackrabbit 和 Shindig),来使资源开发专注于真正关于学术合作。下一代Sakai将会呈现一个新的、以用户为中心的界面,这种界面使用起来既简单又舒适。而且它将包括新的功能,例如包括当今的用户所期待的社交网络和自由内容创作。 这个核心小组已经有了成绩了。新内核的概貌已经显现。设计工作已经开始了新的用户体验。关于Sakai诸多方面新概念正在被讨论和分析。虽仍存在一些有待从概念和技术上进一步斟酌之处,但是前进的方向却越来越清晰。下文提供了更多细节,包括:对您的大学的益处,怎样了解更多、如何加入这项努力。
技术报告(Knime: The Konstanz Information Miner) 摘要---knime是一个能用来很简单的虚拟装配和交互执行数据管道的标准的环境 Knime被设计成为一个教学,研究以及合作的平台,在这里你可以很容易的集成新的算法,数据操纵或者是可视化的方法比如一个新的模块或是节点。在这本白皮书我们将介绍有关设计方面的基础构架以及怎样将新节点插入的简单过程。 第一概述 在过去的几年里,人们对标准的数据分析环境的迫切需求已经达到前所未有的程度。 为了充分利用大量不同种类的数据分析方法,这样一个环境是必须的—--能够简单而直观的 使用,允许对分析进行快速和交互式的变换,用户可以可视化的搜索结果。 为了应付这些挑战,数据流水线操作环境是再合适不过一种模型。 它允许用户通过标准的组建模块可视化地组装和修改数据分析流,同时提供一种直观,图示的方法来记载操作日记。 Knime就能提供这样的一个环境。 图1展示的是一个例子的数据分析流截图 在中间,一个数据流正从三个源节点读入同时在多处进行处理,也跟分析流相平行,包括预处理,建模,以及可视化节点。在这种类繁多的节点中,你可以选择数据源,数据处理步骤,模型搭建算法,可视化技术甚至是输入输出模型工具,然后将它拖到工作区,可以让它和其他节点连接起来。让所有操作实现图形交互的能力创建了检索你手中的数据集功能强大的环境Knime是用Java编写的而他的图形作业编辑区是一个类似Eclipse插件程序的工具。 扩充是很容易的,通过打开API和数据抽象框架,把正确定义的新节点快速加入就可以了。在这本白皮书里我们会描述一些有关Knime内核的细节。更多信息你可以登陆网站查询。 第二部分构架 Knime的构架在设计之初就有三个主要的原则: ?可视化,交互式构架:数据流应该通过简单的拖放各种处理单元来组合。标准的应用程序能被设计通过单个的数据管道。 ?模块化:处理单元和数据容器不应该相互依靠,以便分布式计算和不同算法的独立开发的实现更简单。数据类型被封装,也就是说没有数据类型被重定义,新的数据类型能够伴随着
解码SDN 在过去的一年中,软件定义网络SDN一直是网络界的讨论重点。但从很多方面来说,网络一直被软件定义着。软件渗透在所有影响我们生活的技术中,而网络也没有什么不同。然而,网络受软件配置、交付和管理方式的限制——从字面上来说,就是需要通过在1980年代微型计算机和DOS时期使用的命令行进行整体更新和管理。 网络软件的挑战 在行业中,网络软件一直是创新的累赘。因为每一个网络设备必须单独配置——通常是手工完成,就是指通过键盘——网络无法跟上现代云系统所需的快速变化。亚马逊或谷歌等互网络公司投入数百名工程师建立自己的云系统,以作为应对网络配置的解决方案。但对于大多数企业来说 建立自己的私有云不是一个合理的方法。随着虚拟化和云计算彻底改变了计算与存储方式,网络已经远远落后。 在服务供应商的环境中,配置和管理自己的网络往往使运营商焦头烂额。就像谷歌,他们也为配置自己的网络建立了运营支持系统,但这些系统就像用了20多年之久,常常因网络软件带来的负担而崩溃。对于服务供应商来说,网络是他们的业务。 为了实现新的业务机会,他们必须向网络供应商推出新的功能。于是,网络软件再一次使网络行业败象毕露——被开发为一个整体式嵌入系统,而不具备应用程序的概念。每一个新功能都需要软件堆栈的整体更新。想象一下,这就像每一次加载新应用都需要更新智能手机上的操作系统。而这就是网络行业强加给其客户的。更糟糕的是,每一次更新往往带有很多其它的变化——这些变化有时候会产生新的问题。因此,在引进到网络之前服务供应商必须认真、彻底地测试每一个更新。 什么是SDN 企业和服务供应商都在寻求应对网络挑战的解决方案。他们希望网络能根据自己的业务政策进行动态的调整和响应。他们希望这些政策能实现自动化,从而减少
BTCEX全球区块链资产交易平台 -----交易投资挖矿,分红收益永不停息Copyright ? 2017 btcex.one. All rights reserved.
目录 1.背景 (3) 1.1.区块链资产交易平台现状 (3) 1.2.现存区块链资产交易平台存在的问题 (4) 2.交易平台介绍 (5) 2.1精选区块链资产 (5) 2.2用户投票上线资产 (5) 2.3顺应币币兑换新潮流 (5) 2.4提供C2C交易专区 (5) 2.5安全稳定 (5) 2.6流畅的交易体验 (6) 2.7国际化的平台 (6) 2.8丰富多彩的优惠活动吸引更多用户 (6) 2.9创新的盈利模式 (6) 2.10平台贡献者持续奖励 (7) 3.技术架构 (8) 4.平台发展路线图 (9) 5.Token Sale细则 (10) 5.1Token介绍 (10) 5.2Token应用 (10) 5.3BEB的经济价值 (10) 5.4BEB售卖计划 (11) 5.5资金用途 (12) 6.风险提示 (13)
1.背景 1.1. 区块链资产交易平台现状 2009年中本聪提出区块链概念并创造比特币(BTC),开启了区块链世界的大门,2015年以太坊(ETH)横空出世,基于智能合约的区块链应用将区块链生态的演化再次向前推进。随着区块链技术的不断更新,各国政府及企业均注意到了区块链在价值传递、信息传输等领域存在的巨大潜力及价值。日本、澳大利亚等国家相继确?立比特币(BTC)的合法地位;微软、摩根大通等企业巨头成立EEA(企业以太坊联盟),开展基于以太坊的技术研究。区块链行业正在从初始的爆发当中走向成熟,优质区块链资产层出不穷。由此,区块链资产的兑换需求将呈爆发式的增长。据不不完全统计,2016年年1?月区块链资产总市值只有70亿美金,而2017年12?月已上升至4000亿美金,全球区块链资产日交易额也从4000万美金增长至80亿美金,并且仍处于上升趋势。 可以预见,区块链资产投资领域的参与者及参与资金都将持续增长,而好的交易平台又都处于强势地位,大力压榨区块链行业基金,使得好多优势区块链项目不能体现出真实价值,不利于行业发展,因此我们慎重决定,联合俄罗斯,中国几大私人矿场,在日本成立基金会,招揽全球顶级开发人才,利用最新互联网技术,将交易所,矿场资源整合,顺应时势,开发一款面向全球的交易平台&算力平台(比特币目前的价值主要由挖矿成本决定),让区块链红利惠及早期参与者。
Sphinx4
Sphinx4 FRAMEWORK 高度的灵活性和模块化 每个标记元素在图中代表一个模块,可以很容 易地更换,从而让研究人员尝试不同的模块实现, 同时不需要修改系统的其他部分 3个模块:前端处理模块、解码器、语言专家 Sphinx4API的注释和翻译: https://www.doczj.com/doc/183133065.html,/taiyb/article/category/24567 57
一、前端 前端包括一个或多个平行的称为数据处理器的通信信号处理模块。支持多个链同时从相同或不同的输入信号中计算不同类型的参数。每一个数据处理器相当于是一个特定的信号处理函数。例如:一个处理器对输入数据执行FFT(快速傅里叶变化)。另一个处理器执行的是高通滤波对输入数据。 在处理器链中的每一个数据处理器都实现了DataProcessor接口。实现了Data接口的对象进行前端,从前端出来,在前端的处理器中通过。输入前端的数据一般是音频数据,但是前端是允许任意类型的输入的。类似的,输出的数据一般是特征,但是允许输出任意的输出类型。你能够配置前端接收任意类型的输入,返回任意类型的输出。 前端是一个Pull模型,采用的是pull的设计模式。为了获得前端的输出,你需调用frontend.getData();。在前端调用getData()方法会依次调用上(前)一个数据处理器在数据处理器链中的,直到第一个数据处理器的getData()方法被调用,这个处理器是从输入中读取Data对象。前端的输入实际上是另一个数据处理器,通常是前端的一部分。
二、语言专家 在sphinx – 4中,语言专家是一个可插入模块,允许人们用不同的语言专家实现动态配置系统。它是为解码器(decoder)创建和管理搜索空间的,此类为是一个提供了语言模型服务的一般接口。 任何语言专家的主要作用是为解码器呈现搜索空间(构建搜索空间)。通过调用getSearchGraph 方法,搜索管理类对象能够获得搜索空间。此方法返回的是一个搜索图类对象。在搜索图中的初始状态能够通过调用getInitialState方法获得,后续状态能够通过调用SearchState.getSuccessors()方法获得。 一个语言专家有大量关于它在哪里返回搜索状态的顺序的维度。例如在一个flat语言专家也许会在一个字的开始处返回一个字状态,然而tree语言专家也许会在一个字的结尾处返回一个字的状态。同样的一个语言专家也许会在彻底的省略掉一些状态类型(如一个单元状态)。一些搜索管理器也许会想知道由语言专家产生的不同状态类型的先验顺序。SearchGraph.get N u m StateOrder()方法用来获得状态类型的数量,此状态类型将会被语言专家返回即由其创造。 被语言专家所表示的搜索空间依赖于词汇的长度(尺寸)和其拓扑,搜索空间也有会包含大量的状态。一些语言专家会动态的产生搜索状态,也就是说,在搜索空间中代表一个搜索状态的对象直到搜索管理器需要的时候才被创建。搜索管理器在比较状态之前需要决定一个特定的状态是否被加入。因为搜索状态有可能被动态的产生。被语言专家返回的状态通常能够提供e q uals 和hash C ode 方法的非常有效率的实现。这允许搜索管理器高效的维护在H ashMaps中的状态。 本身包含三个可插拔的组件:语言模型、字典、声学模型