
EViews上机指导书
通过研究我国城镇和农村居民消费与可支配收入的关系来学习EViews的使
用。数据如表2所示,表中各项目含义为::
Cr=农村居民人均消费支出(元) Yr=农村居民家庭人均纯收入(元)
Pr=农村居民消费价格指数(1985=100)
Cu=城镇居民人均消费支出(元) Yu=城镇居民人均可支配收入(元)Pu=城镇居民消费价格指数(1985=100)
CT=全国居民人均消费水平(元) Rpop=农村人口比例(%)
P=全国居民消费价格指数(1985=100)
表2 城镇、农村居民人均消费与人均可支配收入年份Cu Yu Pu Cr Yr Pr CT Rpop P 1985 673.20 739.10 100.0 317.42 397.60 100.0 437 76.29 100.00 1986 798.96 899.60 107.0 356.95 423.80 106.1 485 75.48 106.50 1987 884.40 1002.20 116.4 398.29 462.60 112.7 550 74.68 114.30 1988 1103.98 1181.40 140.5 476.66 544.90 132.4 693 74.19 135.80 1989 1210.95 1375.70 163.3 535.37 601.50 157.9 762 73.79 160.20 1990 1278.89 1510.20 165.4 584.63 686.30 165.1 803 73.59 165.20 1991 1453.81 1700.60 173.8 619.79 708.60 168.9 896 73.63 170.80 1992 1671.73 2026.60 188.8 659.21 784.00 176.8 107072.37 181.70 1993 2110.81 2577.40 219.2 769.65 921.60 201.0 133171.86 208.40 1994 2851.34 3496.20 274.1 1016.81 1221.00 248.0 174671.38 258.60 1995 3537.57 4283.00 320.1 1310.36 1577.70 291.4 223670.96 302.80 1996 3919.47 4838.90 348.3 1572.08 1926.10 314.4 264170.63 327.90 1997 4185.64 5160.30 359.1 1617.15 2090.10 322.3 283469.52 337.10 1998 4331.61 5425.10 356.9 1590.33 2162.00 319.1 297268.09 334.40 1999 4614.91 5854.00 352.3 1577.42 2210.30 314.3 313866.65 329.70 2000 4998.00 6280.00 355.1 1670.13 2253.40 314.0 339765.22 331.00 2001 5309.01 6859.60 357.6 1741.09 2366.40 316.5 360963.78 333.30 2002 6029.88 7702.80 354.0 1834.31 2475.60 315.2 381862.34 330.60 2003 6510.94 8472.20 357.2 1943.30 2622.20 320.2 408960.91 334.60
数据来源:《中国统计年鉴2004》
§1 创建工作文件(Workfile)
一、使用菜单操作方式
使用EViews进行经济计量分析的第一步就是新建或调入一个Workfile。只有新建或打开一个已有的Workfile, EViews才允许用户输入开始进行数据处理。
1.打开一个已有的工作文件
点击菜单File→Open→EViews Workfile…,会弹出如下窗口(图3):
图3
在Open窗口中找到你所存放的Workfile的位置,打开这个文件就可以了。
2.新建一个Workfile
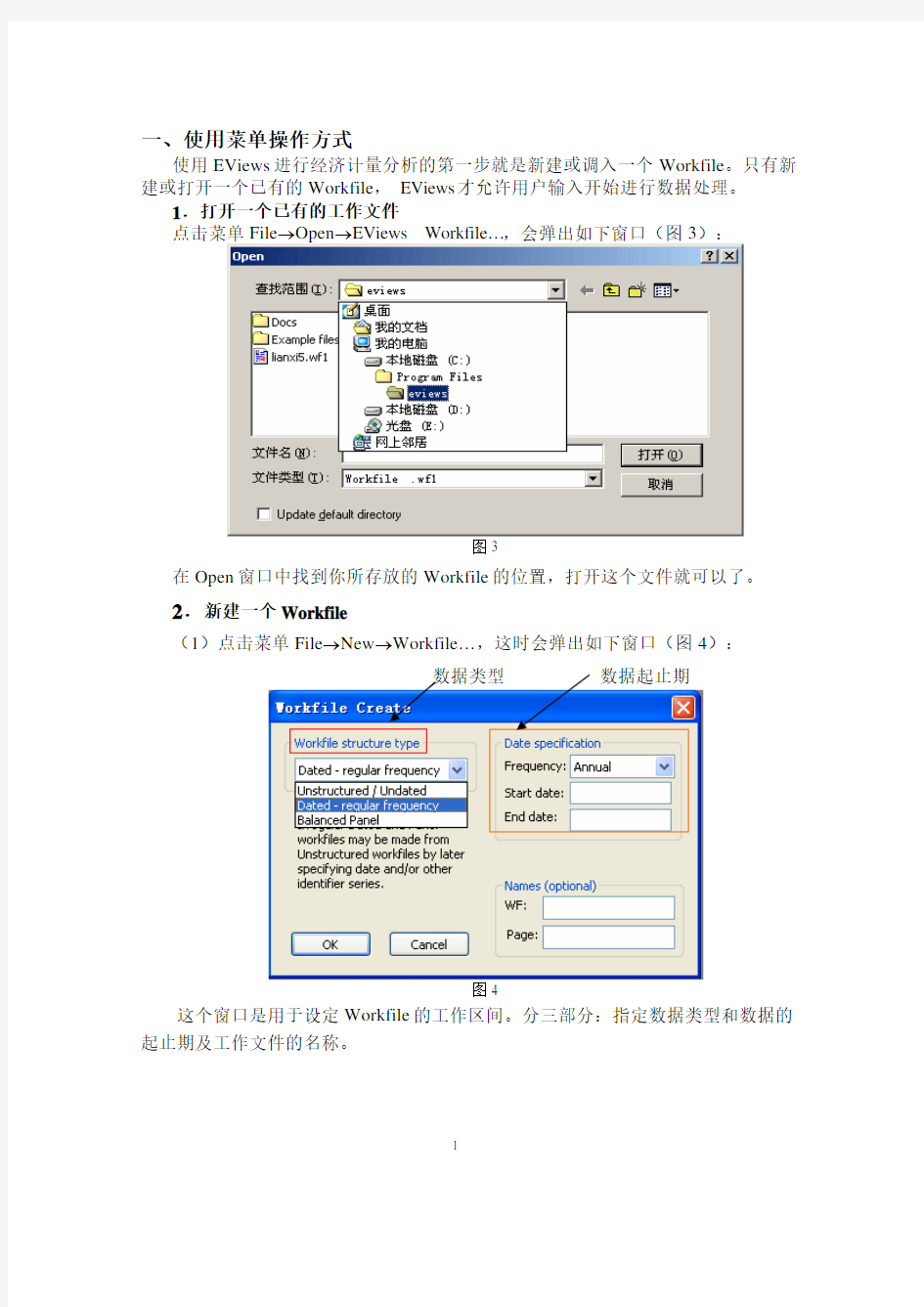
(1)点击菜单File→New→Workfile…,这时会弹出如下窗口(图4):
数据类型
图4
这个窗口是用于设定Workfile的工作区间。分三部分:指定数据类型和数据的起止期及工作文件的名称。
Workfile structure type:是指定数据的类型,包括时间序列数据(Dated-regular frequency)、非结构/非日期数据(Unstructured/Undated)和面板数据(Balanced Panel)。只要点击下拉菜单选择相应的数据类型即可。
Names(optional):指定工作文件名及样本所在页(page)的名称。一个工作文件可以有多个page。
不同的数据类型对应不同的数据起止期。
①当选择Dated-regular frequency时,数据起止期的格式如图4。
Frequency:是指定时间序列数据的类型,分为年、半年、季度、月度、周、日。
Start date与 End date:数据的起止时间或序号,输入的格式要与选定的数据类型相匹配。具体如下:
*Annual:表示年度数据,起止时间如1985、2003。
* Semi-annual:表示数据频率为半年。如起始日期为2001上半年,终止日期为2003年下半年,则Start date中填入2001:1,End date 中填入2003:2,或者输入2001S1和2003S2(S是Semi-annual的缩写)。
*Quarterly:表示季度数据。如1998:1 表示1998年第1季度, 2003:4 表示2003年第4季度,或者输入1998Q1和2003Q4(Q是Quarterly 的缩写)。
*Monthly:表示月度数据。如1998:12表示1998年12月,或者输入1998M1和2003M12(M是Monthly的缩写)。
*Weekly、Daily:表示周、日数据。因篇幅关系,这里不再详述。
②当选择Unstructured/Undated时,数据起止期的格式如图5。
图5
Data range:输入横截面数据的范围。比如有30个省份的gdp数据,则在Observations输入30。
③当选择Balanced Panel时,数据起止期的格式如图6。
图6
Frequency:是指定面板数据在时间序列上的类型,分为年、半年、季度、月度、周、日。
Start date与 End date:数据的起止时间或序号,输入的格式要与选定的数据类型相匹配。
Number of cross sections:截面个体数。
指定了数据类型及输入相应的起止时间后,单击OK按钮,就可以看到工作文件出现在主窗口中。在本例中选择年度数据,起止时间为1985-2003年。如图7
所示:
图7
(2)工作窗口
图7显示的是工作文件窗口,包括如下内容:
① 标题栏:指明窗口的类型workfile 及名称,还有控制按钮。如:
Workfile:UNTITLED ,Untitled 表示工作文件未保存和未命名。此时可点击工具栏中的Save 或主菜单中File →Save ,则会弹出Saveas 的窗口,读者就可选择workfile 保存的路径及名称,点击“保存”后,会弹出序列在硬盘中的保存格式,如图8。此例中保存为con_income 。
图8
② 工具栏:提供常用操作的快捷方式。工具栏左边的三个按钮View 、Proc 、Object 与主菜单栏上的同名菜单的功能完全一样。这里只介绍一些常用的选项:
A .Proc 菜单栏:
▼Set Sample…:设定样本回归区间。选择该项时,会弹出如下窗口(图9):
对象名称
图9
在Sample range pairs中,会显示已有的sample区间,你可以对此进行修改,并点击OK。图9中“@all”是EViews设定的特殊关键字(keywords),表示与工作文件的时间范围(range)相同,如果工作文件的时间范围发生变化,则sample也跟着改变。在此例则等同于“1985 2003”。
在IF condition中可以输入条件表达式,通过该表达式来确定样本区间。两者可同时确定。等同于工具栏上的Sample按钮。
▼Structure/Resize Current Page…:改变工作文件的时间范围,数据类型。点击后弹出窗口如下(图10):
图10
在本例中,若想把数据扩充到2007年,则可把End date中2003改成2007,点击OK即可。
B.Object的菜单项
▼New Object…:创建新的对象。
▼Copy selected…:复制所选对象。
▼Rename selected…:重命名所选对象。
▼Delete selected…:删除所选对象。同工具栏上的Delete按钮。
③信息栏:显示工作区间和样本区间、workfile的显示方式及默认的方程。Filter:*:表示显示全部对象;如果是Filter:a*;则表示显示所有名字以字母
“a”开头的对象。Default Eq:表示最近一次估计过的方程;NONE:表示工作文
件中还没创建过方程。
④对象保存区:各种已建立的对象都显示在这个窗口中。对象的显示分为两部分:对象的图标和对象的名称。在一个新创建的workfile中,都会自动显示两个对象:c和resid。
c:系数向量。左边的图标表示c的类型是向量(Coef),保存估计系数。
Resid:残差序列。左边的图标表示resid的类型是序列(Series)。用于保存最近一次估计的方程的残差。
双击所选取的对象就可以打开相应的窗口,右击某个对象可弹出快捷菜单选择某种操作。要选择多个对象,可按住Ctrl或Shift键的同时点击对象。
3.保存工作文件
此时可点击工具栏中的Save或主菜单中File→Save,则会弹出Saveas的窗口,
用户就可选择workfile保存的路径及名称。
二、使用命令行操作方式
1.创建工作文件
命令格式: wfcreate (options) frequency start_date end_date[num_cross_sections] wfcreate(options) u num_observations
第一行命令用于创建时间序列数据和面板数据,frequency是时间序列的数据类型,如年度数据Annual用字母“a”表示,具体如下:
Semi-annual
a:Annual s:
Monthly
Quarterly m:
q:
w: Weekly d: Daily(5 day week)
7: Daily(7day week) u: Undated or irregular
(options)可建立工作文件名,如果省略,则建立一个未命名的工作文件。
[num_cross_sections]则指定面板数据的截面个体数。
我们的例子是创建一个名为con_income的工作文件,命令如下:
create (wf =con_income) a 1985 2003
con_income文件将自动存入默认的路径(EViews的安装文件夹下)中。
第二行命令则创建横截面数据,num_obervations表示样本数。
2.保存工作文件
保存未命名的工作文件或重新保存经修改的工作文件,则可使用Save命令。命令格式:Save 文件名或 Wfsave 文件名
Save con_income 表示存入默认路径中。
Save D:\ zly\con_income 表示存入D盘的zly目录下。
工作文件的扩展名是.wf1,EViews在保存时自动将工作文件存为此扩展名,如本例中为con_income.wf1。
3.打开工作文件
命令格式:Load workfile_name
Wfopen workfile_name
如果文件不在默认路径下,则在文件名前输入对应的路径。如
Load d:\zly\con_income.wf1 或Wfopen d:\zly\con_income.wf1
4.设定样本区间
命令格式:smpl 样本区间或 smpl 样本区间 if 条件表达式
5.改变工作文件的范围
命令格式:expand start end
例:由于预测需要,要把工作区间从1985-2003年扩到1985-2010年,则命令为:
expand 1985 2010。
§2 数据输入、编辑和分析
建立或调入工作文件以后,可以输入和编辑数据,对数据进行加工和分析。
一、输入数据
有四种输入数据方式:
1.以菜单方式——单个序列方式输入数据
在EViews窗口或工作文件窗口中点击Object → New object …,则会弹出下面窗口(图11):
图11
在Type of Object中选择Series类型;在Name for Object中输入序列名称cu (城镇人均消费支出),点击OK,则回到workfile界面,双击cu序列,则打开数据编辑窗口。点击Edit+/-打开数据编辑状态,(用户可以根据习惯点击Smpl+/-改变数据按行或列的显示形式,)然后输入数据(与excel类似)。如下图(图12):
①
图12
然后用相同的方法再建立序列yu(城镇人均可支配收入)、pu(城镇居民消费价格指数)。
在图12标注①处是指在Group中数据存在的方式,可以是原始数据状态,可以是一阶差分、对数等。
2.以菜单方式――群组方式输入数据
在EViews窗口中点击Quick→Empty Group(Edit Series),则会进入数据编辑窗口,点击obs 行,然后输入序列名cu,按enter,则弹出窗口13,选择所建立数据类型。
图13
图13中,Numeric series是数字型序列,缺失数据为NA;
Numeric series containing dates是日期型序列;
Alpha series是字符型序列,比如姓名、地址等。
在Group中可以输入多个序列。输入序列名后,可以输入数据,方式同上。弹出如下窗口(图14):
与图12同
①②
图14
图14中的①Untitled:表示没有给Group命名。点击Group中的Name菜单,则出现(图15)
图15
在Name to identify object中输入名称urban或可以默认GROUP01,在下面的Display name中可输入注释,也可不输,点击OK后,在workfile中就会出现名为urban的group了。不仅如此,存在group中的序列也会以Series的形式存在workfile中。如现在workfile中有(图16):
给ser01重命名
图16
②yu :表示输入序列名,按enter 后,就会出现与序列cu 一样的格式。 在Group 中也可以先输入数据,再给序列命名。输完cu 、yu 后,在第三列1985年处输入数据100.0后,按enter 键,EViews 会自动给序列命名为SER01。
你可以修改此序列名,有两种方法:
(1)在Group 中直接点击SER01,后输入你自己建立的序列名pu ,按enter 就可以了。如图17:
图17
Series
Group
(2)在workfile中:选中ser01序列,按右键,在快捷菜单中选Rename…,如图16;或点击Object→Rename Selected,则会弹出Object Name窗口(与图15同),在Name选项中输入pu,点击OK就行了。
3.以命令行方式――data/group命令
命令格式为:data <序列名1> <序列名2>......<序列名n>
在命令框中输入data cu yu pu
回车后弹出的数据编辑框与第2种输入方式完全相同。如图18所示:
图18
4.以命令行方式――Series命令
命令格式为:series 序列名或 series 序列名=公式
输入命令:series cu
series yu
series pu
回车后,数据输入方式与第1种方法完全相同。
上面介绍的数据输入方式都是通过键盘实现的。EViews也支持直接从各种格式的外部文件输入数据。
二、编辑数据
建立数据后,可以对数据进行各种编辑。
1.产生新的序列
在本例中,消费支出cu和人均可支配收入yu都是名义数据,现在要转换成以
1985年为基年的实际数据,设城镇人均实际消费支出和城镇人均实际可支配收入分
别用cup和yup表示,则计算公式为
cup=cu / pu*100; yup=yu / pu*100
操作如下:
(1)菜单方式
点击菜单Object→Generate series…或Quick→Generate series…或workfile中的工具栏Genr,则弹出窗口(图19):
图19
在Enter equation框中键入相应的公式后,点击OK,则生成新序列cup。yup 的处理与cup同。
(2)命令方式
格式: genr 对象名=公式或series 对象名=公式
本例命令如下:genr cup=cu/pu*100 回车
genr yup=yu/pu*100 回车
或 series cup=cu/pu*100 回车
series yup=yu/pu*100 回车
在公式中,还经常会用到一些函数,比如取对数等,例如对cu去对数,则
Genr lcu=log(cu)
常用的函数如下表(表3):
函数名称功能函数名称功能
abs(x) 求序列x的绝对值 log(x) 取x的自然对数
exp(x) 求指数e x sqre(x) 对x求平方根
求x的一阶差分mean(x) 求均值 d(x)
求x的n阶差分min(x) 求最小值 d(x,n)
max(x) 求最大值 var(x) 求方差
sum(x) 求和 stdev(x) 求标准差
求x,y的相关系数。
sumsq(x) 求平方和 cor(x,y)
求x,y的协方差inv(x) 求倒数1/x cov(x,y)
x(-1) 取x的滞后一期 x(-n) 取x的滞后n期2.给对象重命名
格式:Rename 原对象名新对象名
3.删除对象
格式:Delete 对象名
4.在Group中添加或删除序列
删除序列:打开Group窗口,然后用鼠标选择所要删除的序列,按右键,在弹出的菜单中选择Remove Series即可;
添加序列:选中任何一个序列(包括空序列),按鼠标右键,在弹出的菜单中选中Insert Series,在弹出的窗口中输入添加序列名即可。
三、数据的统计分析
1.相关系数矩阵
打开group:urban窗口,点击Quick→Group Statistics→Correlations,弹出窗口如下图20:
图20
在图20中输入Group名,则对Group中所有的序列求相关系数。点击OK 后,结果如图21:
图21
可见各序列之间的相关度都很高。这个操作是显示Group中所有序列之间的相关系数矩阵,如果只想显示其中一些序列的相关关系,则可在图20中输入cu、yu、pu,点击OK后结果如下:
图22
进行同样的操作,然后在图20中输入cup、yup、pu,则结果如下:
图23
从图22与图23可知,城镇人均消费支出cu(cup)与城镇人均可支配收入yu (yup)的相关度很高。
2.显示各序列的描述统计量
在Group窗口中点击View→Descriptive Stats→Common Sample,则有结果如图24,给出了各序列的均值、中位数、最大值、最小值、标准差、偏度、峰度、J-B 统计量、观测值数。
图24
四、画图
1.在一张图上建立cu、yu、pu的线形图
①点击Quick→Graph…;
②在弹出如图20的窗口中输入cu、yu、pu(EViews按输入序列的先后,称cu线形图为Line1;yu线形图为Line2;依次类推。),点击OK;
③在随后弹出如图25的窗口中按默认选项,点击OK,结果如下(图26):
可以看出人均消费支出有不断上升的趋势。可以对图26进行各种修改:如改变图形的类型、坐标尺度、线形等。点击图形按右键,则会弹出快捷菜单如下(图27):
图27
点击快捷菜单中的Options…或双击图形内任何位置,则会弹出如图25的窗口。
EViews通过图形选项窗(图25)提供了丰富多彩的绘图选项,在这里可以设置图形的类型、显示方式、坐标轴的刻度等。其中最基本的是图形类型(Graph Type),列出了以下类型:Line Graph(线型图),Stacked Lines(叠线图),Bar Graph(直方图),Stacked Bars(叠柱图),Mixed Bar&Line(柱线混合图),Scatter Diagram(散点图)和Pie Chart(餅图)。其它选项的含义和用法,这里就不一一介绍,有兴趣的读者,可参见联机Help的“Users GuideI”中的13和14章。
2.建立yup和cup的X_Y线形图。线形用折线和数据点(空心圆点)同时表示;颜色用绿色。
操作如下:
①点击Quick→Graph…;
②在弹出如图20的窗口中输入yup、cup(先输入的序列作为横轴,第二个序列作为纵轴),点击OK;
③在随后弹出如图25的窗口:
OK OK Symbol Symbols and Lines Symbol Line Color Symbol Line Line XY Graph Basic →??
?
??
??
??
?
?
?
?
?→??????????→→→→???→→第一行绿色//Type Graph Type ,结果如图28:
图28
同学们如果对画图的命令方式感兴趣,可参考Help →Command reference →Chapter 3:Graph Creation Commands 。
§3 单方程回归和预测
一、估计城镇消费函数 (一)确定方程形式
从图19看出,cup 与yup 的相关系数为0.999;观察消费性支出与可支配收入的线形图(见图28),可知两者呈高度线性关系。在经济理论指导下,依据凯恩斯理论,设定理论模型:
cup= a + b (yup)
(二)用普通最小二乘法(OLS )估计模型
汇编语言程序上机过程 实验目的: 1、掌握常用工具软件 PE,MASM和LINK的使用。 2、伪指令: SEGMENT,ENDS,ASSUME,END,OFFSET,DUP。 3、利用的 1号功能实现键盘输入的方法。 4、了解.EXE文件和.COM文件的区别及用INT 21H 4C号功能返回系统的方法。 程序: datasegment messagedb'This is a sample program of keyboard and disply' db0dh,0ah,'Please strike the key!',0dh,0ah,'$' dataends stacksegmentpara stack 'stack' db50 dup(?) stackends codesegment assumecs:code,ds:data,ss:stack start:movax,data movds,ax movdx,offset message movah,9 int21h again:movah,1 int21h cmpal,1bh jeexit cmpal,61h jcnd cmpal,7ah jand andal,11011111b nd:movdl,al movah,2 int21h jmpagain
exit:movah,4ch int21h codeends endstart 实验步骤: 1、用用文字编辑工具(记事本或EDIT)将源程序输入,其扩展名为.ASM。 2、用MASM对源文件进行汇编,产生.OBJ文件和.LST文件。若汇编时提示有错,用文字编辑工具修改源程序后重新汇编,直至通过。 3、用TYPE命令显示1产生的.LST文件。 4、用LINK将.OBJ文件连接成可执行的.EXE文件。 5、在DOS状态下运行LINK产生的。EXE文件。即在屏幕上显示标题并提示你按键。每按一键在屏幕上显示二个相同的字符,但小写字母被改成大写。按ESC键可返回DOS。若未出现预期结果,用DEBUG检查程序。 实验报告: 1、汇编,连接及调试时产生的错误,其原因及解决办法。 2、思考: 1)若在源程序中把INT 21H的'H'省去,会产生什么现象? 2)把 INT 21H 4CH号功能改为 INT 20H,行不行?
微处理器与接口技术 实验指导
实验一监控程序与汇编语言程序设计实验 一、实验要求 1、实验之前认真预习,明确实验的目的和具体实验内容,设计好主要的待实验的程序,做好实验之前的必要准备。 2、想好实验的操作步骤,明确通过实验到底可以学习哪些知识,想一想怎么样有意识地提高教学实验的真正效果。 3、在教学实验过程中,要爱护教学实验设备,认真记录和仔细分析遇到的现象与问题,找出解决问题的办法,有意识地提高自己创新思维能力。 4、实验之后认真写出实验报告,重点在于预习时准备的内容,实验数据,实验过程、遇到的现象和解决问题的办法,自己的收获体会,对改进教学实验安排的建议等。善于总结和发现问题,写好实验报告是培养实际工作能力非常重要的一个环节,应给以足够的重视。 二、实验目的 【1】学习和了解TEC-XP16教学实验系统监控命令的用法; 【2】学习和了解TEC-XP16教学实验系统的指令系统;
【3】学习简单的TEC-XP16教学实验系统汇编程序设计。 三、实验注意事项 (一)实验箱检查 【1】连接电源线和通讯线前TEC-XP16实验系统的电源开关一定要处于断开状态,否则可能会对TEC-XP16实验系统上的芯片和PC机的串口造成损害。 【2】五位控制开关的功能示意图如下: 【3】几种常用的工作方式【开关拨到上方表示为1,拨到下方为0】 (二)软件操作注意事项 【1】用户在选择串口时,选定的是PC机的串口1或串口2,而不是TEC-XP16实验系统上的串口。即选定的是用户实验时通讯线接的PC机的端口; 【2】如果在运行到第五步时没有出现应该出现的界面,用户需要检查是不是打开了两个软件界面,若是,关掉其中一个再试; 【3】有时若TEC-XP16实验系统不通讯,也可以重新启动软件或是重新启动PC再试; 【4】在打开该应用软件时,其它的同样会用到该串口的应用软件要先关掉。
第三章统计学实验指导 实验五:统计抽样与抽样分布 实验目的: 运用“数据分析”工具生成满足一定分布条件的随机数据。 理解抽样分布的实质。 能根据标准正态分布计算累积概率和指定累积概率下的分位数。 实验要求: 独立完成课堂各类习题和练习,按要求完成实验内容。 实验形式: 教师演示、指导 实验学时:2学时 实验内容: 1、简单随机抽样:从既定的总体数据中生成一个指定样本容量的样本 2、指定分布形态的随机数样本:根据指定总体分布形态,利用“随机数发生器”生成一个指定样本容量的样本。 3、已知总体数据的前提下,利用简单随机抽样得出一定数目的样本,验证样本统计量与总体参数间的关系。 4、利用函数相互计算Z分布条件下的概率与Z值。 一、简单随机抽样 是指从一个已知总体中,随机抽取一定容量的数据组成样本的过程。 操作方法:利用“数据分析”工具,选择“抽样”统计功能,进入抽样对话框。 输入区域:待抽样的总体数据,只能是数值型数据。如果变量名一同被选入,则选中“标志”,表示所选区域中第一个单元格不参与抽样,否则不选。抽样方法:周期——从第一个数据开始,按指定周期整数倍的位置选出数据组成样本,可理解成(非概率)等距抽样。 随机——简单随机重复抽样。样本数——样本容量 输出选项:指明样本数据的存放位置。通常为输出区域(定义起始单元格即可)。应用1:从容量为30的总体中随机重复抽取容量为10的样本。 应用2:模仿教材,从容量为4的总体中(取值分别为1、2、3、4)随机抽取容
量为2的所有样本。观察样本均值的抽样分布特征与总体分布特征间的关系。操作步骤:(1)按照重复抽样从总体中共组合出16个样本; (2)分别计算总体均值、方差、各样本组合的均值、方差; (3)对样本均值进行分组整理,并绘制次数分布图,观察形状。 结论:样本均值的抽样分布为对称单峰钟形分布(正态) 样本均值的均值为总体均值;样本方差的均值为总体方差;样本均值的方差为总体方差的1/n。 二、产生指定总体分布类型下的随机样本数据 如果已知某类变量的数据所服从分布的类型,根据其分布特征,我们可以在某种程度上“模拟”此分布条件下的随机数。 操作方法:“数据分析”工具中的“随机数发生器”统计功能。在对话框中: 变量个数:默认生成指定分布的样本数据列,即一次生成的样本个数,通常为1个样本列。 随机数个数:样本中数据的个数,即样本容量。 分布:常用的随机变量分布类型,比如离散变量对应的分布(柏努利、二项分布、泊松、模式、自定义等),连续变量的分布(均匀分布、正态分布等)。 参数:某特定分布类型的参数特征值。如均匀分布的起止值、正态分布的均值和方差、泊松分布的均值、伯努利分布的成功概率、二项分布的成功概率和试验总次数、指定数据及其对应出现概率的一般离散分布等。 随机数基数:通常不需设定基数。但在某种特殊情形下,有时候需要数据重现,在指定基数后,以后再产生同分布的随机数列时,输入该基数时,数据不再随机出现,而是和指定基数时产生的数据相同。 应用3:从一个总体均值为10,总体标准差为2的正态分布总体中,随机抽取容量为50的样本数据。 操作步骤:在随机数发生器中,选择正态分布类型,设计好参数取值和数据的存放区域即可生成随机数列。 应用4:生成容量为20的2个相同样本数据,生成条件:取值介于0到100之间的均匀分布。 操作步骤:利用随机数发生器,与正态分布操作类似,设定基数。
.= 《管理统计学》实验指导书及 实验报告 王金玉编著 沈阳航空工业学院经济管理学院 班级 学号 姓名 成绩
实验一用Excel对数据的图表描述 实验目的:掌握用EXCEL进行数据的搜集整理和显示 实验步骤: 用Excel进行数据的统计分组描述,可以获得相应数据分组的频数、频率以及向上向下累计频数、频率的情况,并能做出相应的直方图、折线图等描述数据分布特征的统计图形。我们举例介绍一下数据的Excel图表描述的操作方法。 【例1-1】为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果如下,数据进行适当的 分组,编制频数分布表;(2)制作合适的统计图反映分布特征。 700 716 728 719 685 709 691 684 705 718 706 715 712 722 691 708 690 692 707 701 708 729 694 681 695 685 706 661 735 665 668 710 693 697 674 658 698 666 696 698 706 692 691 747 699 682 698 700 710 722 694 690 736 689 696 651 673 749 708 727 688 689 683 685 702 741 698 713 676 702 701 671 718 707 683 717 733 712 683 692 693 697 664 681 721 720 677 679 695 691 713 699 725 726 704 729 703 696 717 688 一、编制分布数列 在Excel中有两类方法可以实现分布数列的编制:一是使用相关的函数,如Frequency函数;二是使用分析工具中的【直方图】工具。本例中我们采用函数方法。具体步骤如下: 第一步:将表1-1中的数据输入或导入到Excel电子表格中,并输入相应的分组数据。如图1-1所示。 图1-1 图1-1中,C、J列均为原始输入数据,寿命数据在A2:A101(图中未完全显示出来),J列的接受区域的各个数据(各组的上限值)是使用Frequency函数或【直方图】分析工具编制分布数列所必需的数据。 第二步:选定D5:D14,输入公式“=Frequency(A2:A101,J5:J14)”,然后按Ctrl+Shift+Enter组合键,即可计算出各组的频数。该函数的第一个参数指定用于编制数列的原始数据,第二个参数指定每一组的上限。在D15中输入公式“=sum (D5:D14)”计算出频数的合计。 第三步:计算频率。在E5中输入公式“=D5/D$15*100”,然后将该公式复制到E6:E14即可。D15存放的是频数的合计数。 第四步:计算向上累计频数。在F5单元格中输入“=D5”,在F6单元格中输入公式“=D6+F5”,再将公式复制到F7:F14。
前言加载“数据分析”功能 Excel菜单栏“工具”选项中“数据分析”工具是统计分析时经常需要用到的,在初次使用时会发现在Excel相应位置中找不到这一选项,其原因在于在安装Office办公集成软件或Microsoft Excel时,一般使用的是“自动”或“典型”安装。为此,需要使用者自己加载这一功能。 操作步骤是:在Excel界面中,单击“工具“菜单,显示各种条目,选中“加载宏”命令,在弹出的“加载宏”对话框中选择“分析工具库”,单击“确定”按钮,如图0-1和图0-2所示。 图0-1 在“工具”菜单中单击“加载宏”选项 图0-2 在“加载宏”列表中选择“分析工具库” 在加载成功“数据分析”选项后,单击“工具”菜单,即可出现“数据分析”选项,如图0-3所示。
图0-3 在“工具”菜单中单击“数据分析”选项 实验三抽样与参数估计 实验目的:熟练使用随机数字表及抽样命令抽取所需要的样本单位并进行简单的参数估计,本部分提供了两种抽样方法和四种参数估计的基本方法有利于学习者根据自己特点选择适当的方法进行参数估计,有利于帮助学习者理解抽样分布的含义 实验要求:同学们利用随机数字表从同一总体中抽选样本量相同的样本,根据样本数据利用描述统计命令计算样本均值及标准差,然后利用多个样本均值能够做出抽样分布;能够利用Excel计算得到不同分布下的临界值及总体均值的置信区间,并能结合实际背景对所得结果进行统计意义解释。 实验内容: 任务一: 1、利用实验指导三中的抽样方法对给的成绩进行抽样,随机抽取50个,计算样本的均值,标准差(直接利用数据分析里面的描述统计),抽样平均值的平均误差,及格率,及格率标准差(p131例子),及格率抽样平均误差。 2、均值估计:结合书本的计算公式利用抽样的结果,在置信度分别为0.8,0.9,0.9545,0.99下,估计总体的均值的置信区间 3、比例估计:结合书本的计算公式利用抽样的结果,在置信度分别为
汇编语言上机操作 一、建立子文件夹 如:D:\hb\masm 二、复制相关文件 把masm.exe、link.exe、ml.exe三个文件复制到上述文件夹中。 三、进入DOS方式 开始/运行/cmd 当前提示符可能是: C:\documents and settings\administrator> 四、常用DOS操作命令 1、改变当前盘 输入d: 并回车,屏幕显示: D:\> 2、改变当前目录 1)进入下一级目录 D:\>cd hb 回车后,屏幕显示: D:\hb>cd masm 回车后,屏幕显示: E:\hb\masm> 问题:可以一次进入下面二级或多级目录吗? 2)返回上一级目录 D:\hb\masm>cd.. 回车后,屏幕显示: D:\hb\>cd.. 回车后,屏幕显示: D:\> 问题:可以直接返回根目录吗? D:\hb\masm>cd\ 回车后,屏幕显示: D:\> 3、显示当前目录容 D:\>dir /p 分页显示当前目录容 问题:如何显示d:\text中的容? D:\>dir d:\text↙ 4、DOS方式下如何运行程序? DOS方式下的可执行文件(即程序文件)扩展名为.exe或.,运行时只需要在系统提示符下输入文件主名即可。例如,有一个文件名为test.exe,存入在D:\hb\masm 中,运行时,可以这样做: D:\hb\masm>test↙ 五、汇编语言上机过程 1、编辑源程序 运行:edit 回车后,进入EDIT环境,输入完后存盘(file/save)并退出(file/exit)。
2、汇编 D:\hb\masm>masm add5.asm↙ 生成目标程序文件add5.obj。(如果有语法错误,会提示错误所在行号和错误类型)3、连接 D:\hb\masm>link add5↙ 生成可执行文件add5.exe。 六、DEBUG程序调用及汇编语言程序调试方法 调试程序DEBUG是DOS支持的又一种系统软件,主要用于汇编语言程序的调试。汇编和连接过程只能查出源程序的语法错误,不能查出功能上的错误和程序不完善的地方。DEBUG程序为用户提供多种命令,大致有:显示和修改寄存器和存贮单元的容;执行程序中任意一段或一条指令;汇编单条源语句和反汇编机器码指令;查找字符代码;端口的输入和输出;文件装入存和写入磁盘等。用户利用这些命令可以查出任何程序功能上的错误。下面说明DEBUG程序的启动方法和主要命令意义。 (一)DEBUG程序的启动 DEBUG程序有两种启动方法。DEBUG程序是在DOS盘上的一个独立的可执行程序(扩展名为.COM),所以,DEBUG程序的第一种启动方法就是把它看作和一般的可执行程序一样,只要打入DEBUG和回车键,就可以把它装入存。但是这样启动只把DEBUG 程序本身装入存并进入等待DEBUG命令状态,还没有把要调试的程序装入存。第二种启动DEBUG的程序的方法是一次相继装入DEBUG程序和要调试的程序。打入的命令格式如下: DEBUG[d:][path]filename[.ext][parml][parm2] 其中的Filename是要调试程序的文件名,可选项[d:][path]和[.ext]分别是要调试程序的所在盘符、路径和扩展名。可选项[parml]和[parm2]是DEBUG程序为要调试程序准备的参数(一般不用)。 例进入DEBUG程序并装入要调试程序。其操作如下: D:\hb\masm>DEBUG add5.exe (进入DEBUG,并装配add5.exe) 此时屏幕上出现一个短线,这表示可以使用DEBUG命令了。 如果启动DEBUG时没有指定要调试的文件名,则需要用N命令指定要调试的文件,再用L命令将其装入存。操作如下: D:\hb\masm>debug↙ - n add5.exe↙ - l↙ (二)DEBUG命令 在说明每个命令之前,先说明一些共同信息: ■DEBUG命令都是以一个英文字母开头,后面跟一个或多个参数。 ■命令字母和参数可用大写或小写或混合形式。 ■命令字母和参数中,相邻两个十六进制之间必须用逗号或空格分开.其它各部分之间有无空格或逗号都可以。 ■执行任何命令期间都可用Ctrl+Break键方法结束命令的执行。
实验一DEBUG常用命令及8086指令使用 实验目的: 通过实验掌握下列知识: 1、8086指令: MOV,ADD,ADC,SUB,SBB,DAA,XCHG 2、DEBUG命令: A,D,E,F,H,R,T,U。 3、ASCII码及用16进制数表示二进制码的方法。 4、8086寄存器: AX,BX,CX,DX,F,IP。 内容及步骤: 一、DEBUG 命令使用: 1、打 DEBUG 进入 DEBUG 控制,显示提示符 '_ '。 2、用命令 F100 10F 'A' 将'A'的ASCII码填入内存。 3、用命令 D100 10F 观察内存中的16进制码及屏幕右边的ASCII字符。 4、用命令 F110 11F 41 重复上二项实验,观察结果并比较。 5、用命令 E100 30 31 32 …… 3F将30H-3FH写入地址为100开始的内存 单元中,再用D命令观察结果,看键入的16进制数是什么字符的ASCII码? 6、用H命令检查下列各组16进制数加减结果并和你的手算结果比较: (1)34H,22H (2)56H,78H (3)A5,79H (4)1284H,5678H (5)A758,347FH 7、用R 命令检查各寄存器内容,特别注意AX,BX,CX,DX,IP及标志位中ZF,CF 和AF的内容。 8、用R命令将AX,BX内容改写为1050H及23A8H。 二、8086常用指令练习 1、传送指令 1)用A命令在内存100H处键入下列内容: MOV AX,1234 MOV BX,5678 XCHG AX,BX MOV AH,35 MOV AL,48
MOV DX,75AB XCHG AX,DX 2)用U命令检查键入的程序并记录,特别注意左边的机器码。 3)用T命令逐条运行这些指令,每运行一行检查并记录有关寄存器及IP的变化情况。并注意标志位有无变化。 2、加减法指令: 1)用A命令在内存100H处键入下列内容: MOV AH,34 MOV AL,22 ADD AL,AH SUB AL,78 MOV CX,1284 MOV DX,5678 ADD CX,DX SUB CX,AX SUB CX,CX 2)用U命令检查键入的程序及对应的机器码。 3)用T命令逐条运行这些指令,检查并记录有关寄存器及ZF情况。 3、带进位加减法: 1)用A命令在内存200H处键入下列内容,并用U命令检查: MOV AH,12 MOV AL,84 MOV CH,56 MOV CL,78 ADD AL,CL ADC AH,CH MOV DH,A7 MOV DL,58 SUB DL,7F
实验一熟悉SPSS 一、实验目的 通过本次实验,了解SPSS的基本特征、结构、运行模式、主要窗口等,了解如何录入数据和建立数据文件,掌握基本的数据文件编辑与修改方法,对SPSS有一个浅层次的综合认识。 二、实验性质 必修,基础层次 三、主要仪器及试材 计算机及SPSS软件 四、实验内容 1.操作SPSS的基本方法(打开、保存、编辑数据文件) 2.问卷编码 3.录入数据 五、实验学时 2学时(可根据实际情况调整学时) 六、实验方法与步骤 1.开机 2.找到SPSS的快捷按纽或在程序中找到SPSS,打开SPSS 3.认识SPSS数据编辑窗、结果输出窗、帮助窗口、图表编辑窗、语 句编辑窗 4.对一份给出的问卷进行编码和变量定义 5.按要求录入数据 6.联系基本的数据修改编辑方法 7.保存数据文件 8.关闭SPSS,关机。 七、实验注意事项
1.实验中不轻易改动SPSS的参数设置,以免引起系统运行问题。 2.遇到各种难以处理的问题,请询问指导教师。 3.为保证计算机的安全,上机过程中非经指导教师和实验室管理人员 同意,禁止使用移动存储器。 4.每次上机,个人应按规定要求使用同一计算机,如因故障需更换, 应报指导教师或实验室管理人员同意。 5.上机时间,禁止使用计算机从事与课程无关的工作。 八、上机作业 (1)、定义变量:试录入以下数据文件,并按要求进行变量定义。 1)变量名同表格名,以“()”内的内容作为变量标签。对性别(Sex)设值标签“男=0;女=1”。 2)正确设定变量类型。其中学号设为数值型;日期型统一用“mm/dd/yyyy“型号;生活费用货币型。
3)变量值宽统一为10,身高与体重、生活费的小数位2,其余为0。
汇编语言上机实验指导书 一、概述 上机实验总学时为14学时,其中综合性实验为2学时。实验共有6项暂定为7次,每次2学时。 1.实验辅导的主要内容 实验辅导的内容包括每个实验的实验目的;实验内容;对实验的算法及实验方法的必要说明;实验准备;实验步骤;实验报告要求;实验程序及参考框图。开始的实验介绍较细,后面的实验简要介绍。 2.实验的软硬件要求 关于汇编语言程序设计的硬件要求不高,有IBM-PC/XT即可,但应有彩色显示器以便进行图形实验。软件方面应有MASM.EXE5.0版(包括LINK.EXE),与MS-DOS版本配套的DEBUG程序和EDIT.EXE编辑软件(其它编辑软件也可以)。 3.加强实践能力的培养 实验目的不光是为了验证书本理论,更重要的是对实践能力的培养。其中包括: 实际调试程序的能力,例如修改程序参数的能力,查看结果的能力,设置断点调试运行的能力等; 开发汇编语言应用程序的能力,例如应用有关汇编软件的能力,进行系统调用和BIOS功能调用的能力,进行模块程序设计的能力等。 对某一问题用不同的程序实现的能力,例如我们为每个实验提供了参考程序(或程序段),目的是让每个实验者参照样板程序将实验成功地实现,在掌握其方法后,自己改变程序或自己编制程序加以实现。 实验一汇编语言运行环境及方法、简单程序设计(2学时、验证性) 1.实验目的: (1) 熟悉汇编语言运行环境和方法 (2)了解如何使用汇编语言编制程序 (3) 熟悉DEBUG有关命令的使用方法 (4) 利用DEBUG掌握有关指令的功能 (5) 利用DEBUG运行简单的程序段 2.实验内容 (1)学会输入、编辑汇编语言程序 (2)学会对汇编语言程序进行汇编、连接和运行 (3)进入和退出DEBUG程序 (4)学会DEBUG中的D命令、E命令、R命令、T命令、A命令、G命令等的使用。对于U命令、N命令、W命令等,也应试一下。 3.实验准备 (1)仔细阅读有关汇编语言环境的内容,事先准备好使用的例子。 (2)准备好源程序清单、设计好调试步骤、测试方法、对运行结果的分析。 (3) 编写一个程序:比较2个字符串所含的字符是否相同。若相同则显示’Match.’,否则显示’No match!’; (1)仔细阅读有关DEBUG命令的内容,对有关命令,都要事先准备好使用的例子。 4.实验步骤 (1)在DOS提示符下,进入MASM目录。 (2)在MASM目录下启动EDIT编辑程序,输入源程序,并对其进行汇编、连接和运行。 ①调用edit输入、编辑源程序并保存在指定的目录中;例:edit abc.asm ②用汇编程序masm对源程序汇编产生目标文件obj。例:masm abc 不断修改错误,直至汇编通过为止。 ③用连接程序link产生执行文件exe.例:link abc
第二章统计学实验指导 实验一:统计整理与分组 实验目的: 运用excel进行常见数据类型的统计整理,能熟练运用菜单和各类函数进行数据筛选、排序,运用数据透视表绘制统计频数分布表。 实验要求: 独立完成课堂各类习题和练习,按要求完成实验内容。 实验形式: 教师演示、指导 实验内容: 1、品质数据分组:利用数据透视表直接绘制,但是需要注意排序数据 2、数值数据分组:对数据排序后,能分析选择数值数据的分组形式。 能利用数据透视表编制单项式分组统计次数数列; 熟练应用统计函数编制组距式分组统计次数分布数列。 一、统计数据的预处理 1、数据筛选:参见指导P37—39 (1)自动筛选: 将鼠标定位于数据文件的变量标题行; 点击菜单“数据”——筛选——自动筛选后,则在标题行出现下拉箭头; 在需要筛选的变量下点击下拉箭头,自行选择筛选功能(前10个,自定义),后确定。 自动筛选结果会自动从原数据区域中被选择出来显示,不符合条件的被屏蔽。 自动筛选一次只能执行一次筛选条件。 取消筛选:将数据“数据”——筛选——自动筛选再点击一次,去掉自动筛选前的“√”。(2)高级筛选: 选择空白区域创立筛选条件区域:筛选变量、筛选条件值 菜单“数据”——筛选——高级筛选后,进入高级筛选对话框;
筛选方式:通常是筛选结果另行放置,防止与原数据混淆。 列表区域:整个数据库区域,一般系统会自动选择。 条件区域:高级筛选可同时执行多个条件的综合筛选结果,选出符合条件的数据区域。 如果同时多个条件筛选,条件区域中将多个条件变量取值同行放置,表示“与”。 若至少满足多个条件之一,条件区域中将多个条件变量取值换行放置,表示“或”。 筛选文化程度为大学本科或岗位为管理员的员工则如此设置: 应用1:利用自动筛选选择男性员工; 利用高级筛选选择当前工资在3万元以上的工人; 利用高级筛选选择年龄在40岁以下或大学本科及以上的职工。 2、数据排序:参见指导P41 将鼠标定位于待分析数据区域的任意位置; 点击菜单“数据”——排序后,进入排序对话框; 排序对话框中: 主要关键字:排序变量。 次要关键字:各总体单位排序变量取值相同时,若指定次要关键字,则按此排序,否则按出现的先后顺序排。 我的数据区域:选择参与排序的数据区域。有标题行,则数据区域第一行不参与排序,一般数据区域首行为变量名时如此选择。否则,无标题行,数据从第一行第一列开始排序。 选项:指定升降序排列形式:次序、方向、方法,用于字符型数据的排序设置。 应用2:对加工零件数按照一定大小进行排序; 对售后服务质量按照一定优劣进行排序。 二、统计分组 统计整理及分析结果的编写通常在word 文档中录入和编辑,只要能用excel 生成相 对规范的统计表和统计图,然后可以复制到word 中进行美化排版即可。 管理员
8086汇编语言上机调试步骤 1、在网络课堂-微机原理与接口技术-实验指导-汇编工具下载,下载汇编工具并解压,文件夹名为“masm”。 2、用鼠标点击“masm”文件夹。进入该文件夹后将看到 MASM.EXE, LINK.EXE , DEBUG.EXE3个文件进行复制操作。 3、用鼠标点击“我的电脑”再点击D: 盘,并在 D: 盘上建立新的“ MASM”文件夹,最后将上面的3个文件全部复制到该文件夹中。(注意实验所有的文件都放在该文件夹内) 4、用文本编辑软件UltraEdit-32、WINDOWS 中的记事本或其它的文本编辑器输入汇编语言程序, 注意在最后一行的 END输入完后要按一次回车键,保存的源 文件的扩展各一定要是“.asm”如: example.asm 。(建议用记事本输入源程序,另存时,保持类型选择“所有文件”如图所示) 5、进入MS-DOS方式 ( 从开始>程序>附件>命令提示符) 或者(从程序 > 运行输入“cmd”回车,进入MS-DOS环境。
6、进入D:>MASM文件夹 7、显示MASM文件夹内所有文件“dir”命令 8、在 DOS 提示符下进行汇编、连接、动态调试等操作。 例如: 对源文件 example.asm 进行的操作
D:\MASM\MASM example.asm;汇编源程序操作 D:\MASM\LINK example.dbj;连接并生成扩展名为 .EXE 的可执行文件 D:\MASM\DEBUG example.exe;对可执行文件进行调试 9、要求掌握的调试命令(在 DEBUG 中使用的命令) a: U - 反汇编命令 用法: -U 代码段地址:起始偏移地址如:-U CS:100 b: D - 显示内存中的数据命令 用法: -D 数据段地址:存放数据的偏移地址如:-D DS:00 20 c: T - 单步执行程序命令 用法: -T 要执行的指令条数如:-T 3 d: G - 连续执行程序命令 用法: -G=代码段地址:指令的起始偏移地址指令的结束偏移地址如: -G=CS:100 106 注意: 结束地址一定要是操作码的所在地址 e: R - 查看和修改寄存器数据命令 用法: -R 回车如:-R AX f: F - 对内存单元填充数据命令 用法: -F 数据段地址:偏移首地址偏移未地址填入的数据 如: -F DS:100 120 ff g: Q - 退出”DEBUG“应用程序命令 10、应用例子 ;二进制到BCD转换(a.asm) ;将给定的一个二进制数,转换成二十进制(BCD)码 DATA SEGMENT RESULT DB 3 DUP(?) DATA ENDS CODE SEGMENT
《汇编语言》实验指导书
目录 实验一Debug命令的使用 (3) 实验二基本汇编指令的使用 (9) 实验三汇编语言程序的调试与运行 (13) 实验四系统功能调用程序的调试与运行………………错误!未定义书签。 实验五分支程序设计……………………………………错误!未定义书签。 实验六循环程序设计……………………………………错误!未定义书签。 实验七子程序设计………………………………………错误!未定义书签。 实验八高级汇编语言程序设计…………………………错误!未定义书签。 实验九I/O程序设计……………………………………错误!未定义书签。 实验十中断程序设计……………………………………错误!未定义书签。 实验十一综合程序设计 (38)
实验一Debug命令的使用 一、知识点 1、DEBUG简介 DEBUG.EXE是DOS提供的用于调试可执行程序的一个工具软件。在汇编语言程序调试中很常用。 DEBUG的提示符是“-”,所有DEBUG调试命令军在此提示符下输入。 DEBUG命令都是一个字母,后跟一个或多个参数,也可使用默认参数。 DEBUG命令的使用注意问题: (1)字母不分大小写 (2)只使用十六进制数,但没有带后缀字母“H” (3)命令如果不符合DEBUG的规则,则将以“error”提示,并以“^”指示出错位置。 (4)每个命令只有按下回车键后才有效,可以用Ctrl+Break终止命令的执行。 2、Debug的调入和退出 以WIN7环境为例,点击“开始/运行…”,在“运行”对话框中输入命令:cmd,然后点击“确定”,进入DOS命令行状态: C:\Documents and Settings\lfy> 然后输入命令: >Debug 进入Debug调试状态,出现Debug命令提示府“-”,在此提示符下可运行所需要的Debug 命令了。 退出Debug的命令:Q 3、Debug常用命令 (1)汇编命令A,格式为: - A [地址] 功能:从指定地址开始允许输入汇编指令,并将该指令汇编成机器指令代码从指定地址开始存放。若不指定地址,则系统从默认的地址开始存放。按回车键退出汇编状态 应用:用于调试一条指令或几条指令组成的一个程序段。
统计学(课程自学指导书) 课程名称:统计学原理 自学学时:64课时 推荐教材:《统计学》(修订版本),杜欢政等.科学,2010.2 参考资料:《统计学原理》,洁明,祁新娥著,复旦大学2007年第四版 《统计学》袁卫等.高等教育,2000 《统计学》,贾俊平等.中国人民大学,2000 《统计学》,[美]David Freedman 等.中国统计,1998 考核方式:平时作业成绩×30%+笔试(闭卷)成绩×70% 课程的性质、目的、任务 《统计学》是经管类各专业的核心课程之一。本课程是以定量分析为主的方法论科学。设置本课程的目的在于培养学生有关统计知识方面的基本技能,培养学生应用统计方法分析问题和解决问题的实际能力。教学应达到的总体目标是:使学生能系统地掌握各种统计方法,并理解各种统计方法中所包含的统计思想;使学生掌握各种统计方法的不同特点、应用条件及适用场合。 第一章绪论学时:9学时(面授3学时,自学6学时) 一、本章自学容及要求 1、了解统计学的产生与发展 2、重点掌握统计一词的三种含义及其它们之间的关系、统计学的特点 3、了解统计工作任务、掌握统计工作的过程 4、重点掌握统计学中的基本概念 二、重点与难点 1、统计一词的三种含义及其它们之间的关系 2、统计学的特点 3、统计学中的基本概念 三、学习方法指导 1、本章主要介绍统计学中的一些理论问题,但是一些理论贯穿于本课程的始终,因此希望学员认真阅读本章的重点与难点。 2、特别强调统计学中的几个基本概念是本章的重点和难点,要求学员必须做到熟练掌握每一个概念、它们之间的关系。为学好以后各章打下扎实的理论基础。 3、学员可以通过认真阅读教材,然后做章后的练习来检验自己掌握知识的程度。 四、典型例题介绍
第一步:编写程序 用记事本编写汇编语言程序,保存为.ASM 文件,保存时,保存类型选择“所有文件”。注意,应将汇编语言程序保存在包含MASM.EXE 及LINK.EXE 的目录下(本例中假定在C盘的MASM目录下,即“C:\MASM”)。 第二步:编译 进入DOS命令提示符环境。该环境的访问方法一:windows “开始”->“运行”,输入“cmd”),如下图: 访问方法二:windows “开始”->“程序”->“附件”->“命令提示符”,如下图所示:
进入DOS命令提示符方式: 用CD 命令进入MASM目录,如下图所示: (若个人的MASM目录在D盘下,可如下操作:)
回车后即进入存放有MASM.EXE LINK.EXE EX11.ASM 的目录D:\MASM : 现在开始用汇编程序MASM.EXE 编译汇编语言源程序EX11.ASM: 回车后开始编译:
若编译出现0处错误(如上图椭圆框内),则表示编译通过,正确生成EX11.OBJ文件: 接下来转入第四步。否则,若出现如下类似界面: 表示出现一处错误,该错误在EX11.ASM的第七行,错误为“出现未定义的符号AS”,则转入第三步。 第三步:编辑程序 用 EDIT.EXE 编辑出现错误的程序 EX11.ASM:
回车后,出现如下界面: 找到第7行,并修改相应错误。修改完成后,点击菜单“File”或用“ALT”回车打开“File”菜单,首先选择“Save”保存修改,然后选择“Exit”退出编辑状态: 重复如下编译过程,重新编译修改过的EX11.ASM,直至全部错误修改完成:
10 Excel在统计学中的应用 10.1 用Excel搜集与整理数据 10.1.1 用Excel搜集数据 统计数据的收集是统计工作过程的基础性环节,方法有多种多样,其中以抽样调查最有代表性。在抽样调查中,为保证抽样的随机性,需要取得随机数字,所以我们在这里介绍一下如何用Excel生成随机数字并进行抽样的方法。需要提醒的是,在使用Excel进行实习前,电脑中的Excel需要完全安装,所以部分同学电脑中的office软件需要重新安装,否则实习无法正常进行。本书中例题全部用Excel2007完成。 使用Excel进行抽样,首先要对各个总体单位进行编号,编号可以按随机原则,也可以按有关标志或无关标志,具体可参见本书有关抽样的章节,编号后,将编号输入工作表。 【例10-1】我们假定统计总体有200个总体单位,总体单位的编号从1到200,输入工作表后如图10-1所示: 图10-1 总体各单位编号表 各总体单位的编号输入完成后,可按以下步骤进行操作: 第一步:选择数据分析选项(如果你使用的是Excel2003,单击工具菜单,若无数据分析选项,可在工具菜单下选择加载宏,在弹出的对话框中选择分析工具库,便可出现数据分
析选项;如果你使用的是Excel2007,点击左上角Office标志图标,Excel选项,加载项,在下面的管理下拉列表中选择“Excel加载项”,转到,勾选“分析工具库”,确定。),打开数据分析对话框,从中选择抽样。如图10-2所示。 图10-2数据分析对话框 第二步:单击抽样选项,确定后弹出抽样对话框。如图10-3: 图10-3 抽样对话框 第三步:在输入区域框中输入总体单位编号所在的单元格区域,在本例是$A$1:$J$20,系统将从A列开始抽取样本,然后按顺序抽取B列至J列。如果输入区域的第一行或第一列为标志项(横行标题或纵列标题),可单击标志复选框。 第四步:选择“随机模式”,样本数为10。 在抽样方法项下,有周期和随机两种抽样模式。 “周期”模式即所谓的等距抽样(或机械抽样),采用这种抽样方法,需将总体单位数除以要抽取的样本单位数,求得取样的周期间隔。如我们要在200个总体单位中抽取10个,则在“间隔”框中输入20;如果在200个总体单位中抽取24个,则在“间隔”框中输入8
汇编语言程序设计的实验环境及实验步骤 知识提要: 1、汇编语言源程序编写好以后,必须经过下列几个步骤才能在机器上运行: (1) 编辑源程序(生成.ASM文件) (2) 汇编源程序(.ASM → .OBJ) (3) 连接目标程序(.OBJ → .EXE ) (4) 调试可执行程序(使用调试程序Debug调试生成的.EXE文件) (5) 运行程序输出结果。 2、Windows环境下的汇编语言集成编程环境的使用 实验一汇编语言上机实验(一) 一、实验要求和目的 1、掌握汇编语言程序设计的基本方法和技能; 2、熟练掌握使用全屏幕编辑程序EDIT编辑汇编语言源程序; 3、熟练掌握宏汇编程序MASM的使用; 4、熟练掌握连接程序LINK的使用。 二、软硬件环境 1、硬件环境:微机CPU 486以上,500MB以上硬盘,32M以上内存; 2、软件环境:装有MASM、DEBUG、LINK等应用程序。 三、实验内容与步骤 1、实验内容 编写程序,判断一个年份是否是闰年。 2、实验步骤 汇编语言程序设计上机过程如图1.1所示。 图1.1 汇编语言程序上机过程 (一)用编辑程序EDIT建立汇编语言源程序文件(ASM文件)
建议源程序存放的目录名为MASM中,MASM子目录在D盘的根目录下。 可以在DOS模式下用编辑程序EDIT.EXE建立汇编语言源程序文件ABC.ASM,注意文件名的扩展名必须是.ASM。也可以在Windows 2000或者在Windows XP环境下鼠标单击“开始”→“运行”,在“运行”中输入“CMD”进入DOS模式,运行EDIT软件,例如:C:\documents and settings\administrator>cd\ *进入C盘根目录 C:\>d: *进入D盘 D:\>md masm *在D盘创建MASM文件夹D:\>cd masm *进入MASM文件夹 D:\masm>edit run.asm *建立run源文件 进入EDIT的程序编辑画面时,编写程序,判断一个年份是否是闰年的汇编语言源程序,输入汇编语言源程序如下: DATA SEGMENT INFON DB 0DH,0AH,'Please input a year: $' Y DB 0DH,0AH,'This is a leap year! $' N DB 0DH,0AH,'This is not a leap year! $' W DW 0 BUF DB 8 DB ? DB 8 DUP(?) DATA ENDS STACK SEGMENT 'stack' DB 200 DUP(0) STACK ENDS CODE SEGMENT ASSUME DS:DATA,SS:STACK,CS:CODE START: MOV AX,DATA MOV DS,AX LEA DX,INFON MOV AH,9 INT 21H LEA DX,BUF MOV AH,10 INT 21H MOV CL, [BUF+1] LEA DI,BUF+2 CALL DATACATE CALL IFYEARS JC A1 LEA DX,N MOV AH,9 INT 21H JMP EXIT A1: LEA DX,Y MOV AH,9 INT 21H EXIT: MOV AH,4CH INT 21H DATACATE PROC NEAR
汇编语言实验指导书纪平张雷编写 安徽工业大学计算机学院 二00四年三月 目录 实验一DEBUG的启动及其基本命令的使用 (2 实验二内存操作数及寻址方法 (6 实验三汇编语言程序的调试与运行 (8 实验四查表程序设计 (10 实验五系统功能调用 (12 实验六循环程序设计 (13 实验七分支程序设计 (15 实验八子程序设计 (18 实验九综合程序设计 (20 附录实验报告 (21 实验一DEBUG的启动及其基本命令的使用一.实验目的: 掌握DEBUG 的基本命令及其功能 二.实验内容:
DEBUG是专门为汇编语言设计的一种调试工具,它通过步进,设置断点等方式为汇编语言程序员提供了非常有效的调试手段。 1、DEBUG程序的启动 在DOS提示符下,可键入命令: C>DEBUG[d:][path][文件名][ 参数1][参数2] 其中文件名是被调试文件的名称,它须是执行文件(EXE,两个参数是运行被调试文件时所需要的命令参数,在DEBUG程序调入后,出现提示符“-”,此时,可键入所需 的DEBUG命令。 在启动DEBUG时,如果输入了文件名,则DEBUG程序把指定文件装入内存。用户可以通过DEBUG的命令对指定文件进行修改、显示和执行。如果没有文件名,则是以当前内存的内容工作,或者用命名命令和装入命令把需要的文件装入内存,然后再用DEBUG的命令进行修改、显示和执行。 2、DEBUG的主要命令 (1汇编命令A,格式为: -A[地址] 该命令从指定地址开始允许输入汇编语句,把它们汇编成机 器代码相继存放在从指定地址开始的存储器中。 (2反汇编命令U,有两种格式: 1-U[地址] 该命令从指定地址开始,反汇编32个字节,若地址省略,则从上 一个U命令的最后一条指令的下一个单元开始显示32个字节。
《统计学》实验指导书(3学分) 实验项目一:问卷数据的预处理 实验目的: 1. 掌握问卷在Excel中的录入方式; 2. 熟悉问卷数据的预处理。 实验要求和步骤: 一、学习问卷单选题、多选题以及开放题在Excel中的录入方法 1、单选题: 直接输入选择项A、B、C、D…等,或直接用1、2、3、4…数字表示选项,选中哪一项即在相应空格填上相应的字母或数字。 例:您的性别是(): 1 男 2 女 其中:Q1、Q2…表示问卷的问题编号,第一列的1、2、3…表示不同的问卷。 2、多选题: 每个选项占一列,被选中记为1,未被选中记为0,若存在需要填写的文字则在相 应位置填写相应文字。 例:3、您光临本地的目的是() A商务会议单独一列,选中填1,没有选中填0 B学术研讨同上 C团体旅游同上 D婚礼宴席同上 E亲朋好友相聚同上 F其他_______ 单独一列,没有选中填0,选中直接将填写内容录入相应表格 若某人选择了DE,则录入情况如下: Q3A Q3B Q3C Q3D Q3E Q3F 0 0 0 1 1 0 若某人选择了F,并填写内容为“工作调动”,则录入情况如下: Q3A Q3B Q3C Q3D Q3E Q3F 0 0 0 0 0 工作调动
其中:Q3表示问卷的问题编号,A、B…等表示该题的选项,如Q3C则表示“团体旅游” 3、开放题: 例:10、请谈一下您对本地的印象__________ 答案录入:在Q10 下方填写相应答案文字即可。 如:Q10 民风淳朴 二、学习对问卷数据进行检查 1、形式层面:录入的过程中及时进行数据有效性检查以防止问卷回答的非法值的出现例:您的性别是(): 1 男 2 女(Excel性别一列录入的答案只可能为1或2)选中B2单元格,点击数据→数据的有效性,如下图: 在数据有效性的对话框中的“允许”菜单中选择“序列”,“来源”中输入“1,2”(以逗号隔开。 ※“输入信息”选项中可以输入相关信息 ※“出错警告”中可以根据需要选择相应选项,“警告”中还可以输入文字提示