
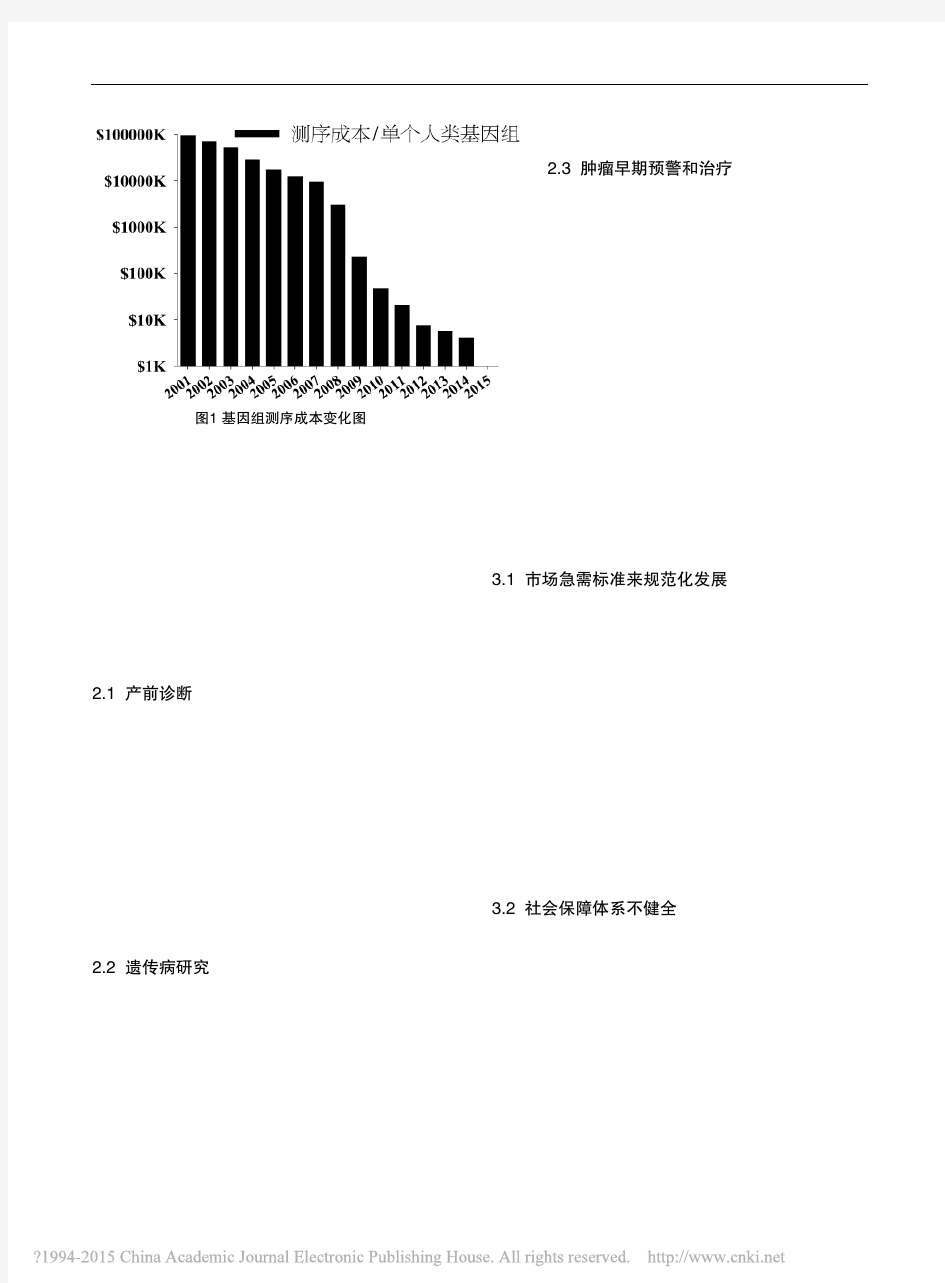
高通量测序基础知识简介 陆桂 什么是高通量测序? 高通量测序技术(High-throughput sequencing,HTS)是对传统Sanger测序(称为一代测序技术)革命性的改变,一次对几十万到几百万条核酸分子进行序列测定, 因此在有些文献中称其为下一代测序技术(next generation sequencing,NGS )足见其划时代的改变, 同时高通量测序使得对一个物种的转录组和基因组进行细致全貌的分析成为可能, 所以又被称为深度测序(Deep sequencing)。 什么是Sanger法测序(一代测序) Sanger法测序利用一种DNA聚合酶来延伸结合在待定序列模板上的引物。直到掺入一种链终止核苷酸为止。每一次序列测定由一套四个单独的反应构成,每个反应含有所有四种脱氧核苷酸三磷酸(dNTP),并混入限量的一种不同的双脱氧核苷三磷酸(ddNTP)。由于ddNTP缺乏延伸所需要的3-OH基团,使延长的寡聚核苷酸选择性地在G、A、T或C处终止。终止点由反应中相应的双脱氧而定。每一种dNTPs和ddNTPs的相对浓度可以调整,使反应得到一组长几百至几千碱基的链终止产物。它们具有共同的起始点,但终止在不同的的核苷酸上,可通过高分辨率变性凝胶电泳分离大小不同的片段,凝胶处理后可用X-光胶片放射自显影或非同位素标记进行检测。 什么是基因组重测序(Genome Re-sequencing) 全基因组重测序是对基因组序列已知的个体进行基因组测序,并在个体或群体水平上进行差异性分析的方法。随着基因组测序成本的不断降低,人类疾病的致病突变研究由外显子区域扩大到全基因组范围。通过构建不同长度的插入片段文库和短序列、双末端测序相结合的策略进行高通量测序,实现在全基因组水平上检测疾病关联的常见、低频、甚至是罕见的突变位点,以及结构变异等,具有重大的科研和产业价值。 什么是de novo测序 de novo测序也称为从头测序:其不需要任何现有的序列资料就可以对某个物种进行测序,利用生物信息学分析手段对序列进行拼接,组装,从而获得该物种的基因组图谱。获得一个物种的全基因组序列是加快对此物种了解的重要捷径。随着新一代测序技术的飞速发展,基因组测序所需的成本和时间较传统技术都大大降低,大规模基因组测序渐入佳境,基因组学研究也迎来新的发展契机和革命性突破。利用新一代高通量、高效率测序技术以及强大的生物信息分析能力,可以高效、低成本地测定并分析所有生物的基因组序列。 什么是外显子测序(whole exon sequencing) 外显子组测序是指利用序列捕获技术将全基因组外显子区域DNA捕捉并富集后进行高通量测序的基因组分析方法。外显子测序相对于基因组重测序成本较低,对研究已知基因的SNP、Indel等具有较大的优势,但无法研究基因组结构变异如染色体断裂重组等。
学习 通常一份测序结果图由红、黑、绿和蓝色测序峰组成,代表不同的碱基序列。测序图的两端(本图原图的后半段被剪切掉了)大约50个碱基的测序图部分通常杂质的干扰较大,无法判读,这是正常现象。这也提醒我们在做引物设计时,要避免将所研究的位点离PCR序列的两端太近(通常要大于50个碱基距离),以免测序后难以分析比对。 我的课题是研究基因多态性的,因此下面要介绍的内容也主要以判读测序图中的等位基因突变位点为主。 实际上,要在一份测序图中找到真正确实的等位基因多态位点并不是一件容易的事情。由于临床专业的研究生,这些东西是没人带的,只好自己研究。开始时大概的知道等位基因位点在假如在测序图上出现像套叠的两个峰,就是杂合子位点。实际比对了数千份序列后才知道,情况并非那么简单,下面测序图中标出的两
个套峰均不是杂合子位点,如图并说明如下: 说明:第一组套峰,两峰的轴线并不在同一位置,左侧的T峰是干扰峰;第二组套峰,虽两峰轴线位置相同,但两峰的位置太靠近了,不是杂合子峰,蓝色的C峰是干扰峰通常的杂合子峰由一高一略低的两个轴线相同的峰组成,此处的序列被机器误判为“C”,实际的序列应为“A”,通常一个高大碱基峰的前面1~2个位点很容易产生一个相同碱基的干扰峰,峰的高度大约是高大碱基峰的1/2,离得越近受干扰越大。一个摸索出来的规律是:主峰通常在干扰峰的右侧,干扰峰并不一定比主峰低。最关键的一点是一定要拿疑似为杂合子峰的测序图位点与测序结果的文本序列和基因库中的比对结果相比较;一个位点的多个样本相比较;你得出的该位点的突变率与权威文献或数据库中的突变率相比较。通常,对于一个疑似突变位点来说,即使是国际上权威组织大样本的测序结果中都没有报道的话,那么单纯通过测序结果就判定它是突变点,是并不严谨的,因一份PCR产物中各个碱基的实际含量并不相同,很难避免不产生误差的。对于一个未知
DNA测序技术的发展及其最新进展 摘要:自从诺贝尔奖得主桑格于1977年发明了第一代DN测序技术以来,DNA测序技术已经作为重要的实验技术广泛的应用于现代生物学研究当中。经过了几十年的发展,DNA测序技术日臻成熟,并且以单分子测序为特点的第三代测序技术也已经诞生。本文主要就每一代测序技术原理和特点及其最新进展做简要介绍。 关键词:DNA测序技术;第三代DNA测序技术;最新进展 The Development and New Progress of DNA Sequencing Technology Abstract: Since Nobel Prize Winner Sanger have founded the first generation of DNA Sequence technology in 1977, DNA sequencing technology has been widely used in modern biological researches as an important experimental. Over decades of year’s development, DNA sequence technology mature gradually and the third generation sequencing technologies characterized by single-molecule sequencing have also emerged. The mechanisms and features of each generation of sequencing technology and their latest progress will be discussed here. Key Words: DNA Sequence technology ; third generation DNA sequencing ;latest development 1.引言 DNA测序技术是分子生物学研究中最常用的技术,它的出现极大地推动了生物学的发展。自从1953年Watson和Crick发现DNA双螺旋结构后[1],人类就开始了对DNA序列的探索,在世界各地掀起了DNA测序技术的热潮。1977年Maxam和Gilbert报道了通过化学降解测定DNA序列的方法[2]。同一时期,Sanger发明了双脱氧链终止法[3]。20世纪90年代初出现的荧光自动测序技术将DNA测序带入自动化测序的时代。这些技术统称为第一代DNA测序技术。最近几年发展起来的第二代DNA测序技术则使得DNA测序进入了高通量、低成本的时代。目前,基于单分子读取技术的第三代测序技术已经出现,该技术测定DNA序列更快,并有望进一步降低测序成本,推进相关领域生物学研究。本文主要介绍DNA测序技术的发展历史及不同发展阶段各种主要测序技术的特点,并针对目前新一代DNA测序技术及目前国际DNA测序最新进展做简要综述。
基因组测序基础知识 ㈠De Novo测序也叫从头测序,是首次对一个物种的基因组进行测序,用生物信息学的分析方法对测序所得序列进行组装,从而获得该物种的基因组序列图谱。 目前国际上通用的基因组De Novo测序方法有三种: 1. 用Illumina Solexa GA IIx 测序仪直接测序; 2. 用Roche GS FLX Titanium直接完成全基因组测序; 3. 用ABI 3730 或Roche GS FLX Titanium测序,搭建骨架,再用Illumina Solexa GA IIx 进行深度测序,完成基因组拼接。 采用De Novo测序有助于研究者了解未知物种的个体全基因组序列、鉴定新基因组中全部的结构和功能元件,并且将这些信息在基因组水平上进行集成和展示、可以预测新的功能基因及进行比较基因组学研究,为后续的相关研究奠定基础。 实验流程: 公司服务内容 1.基本服务:DNA样品检测;测序文库构建;高通量测序;数据基本分析(Base calling,去接头, 去污染);序列组装达到精细图标准 2.定制服务:基因组注释及功能注释;比较基因组及分子进化分析,数据库搭建;基因组信息展 示平台搭建 1.基因组De Novo测序对DNA样品有什么要求?
(1) 对于细菌真菌,样品来源一定要单一菌落无污染,否则会严重影响测序结果的质量。基因组完整无降解(23 kb以上), OD值在1.8~2.0 之间;样品浓度大于30 ng/μl;每次样品制备需要10 μg样品,如果需要多次制备样品,则需要样品总量=制备样品次数*10 μg。 (2) 对于植物,样品来源要求是黑暗无菌条件下培养的黄化苗或组培样品,最好为纯合或单倍体。基因组完整无降解(23 kb以上),OD值在1.8~2.0 之间;样品浓度大于30 ng/μl;样品总量不小于500 μg,详细要求参见项目合同附件。 (3) 对于动物,样品来源应选用肌肉,血等脂肪含量少的部位,同一个体取样,最好为纯合。基因组完整无降解(23 kb以上),OD值在1.8~2.0 之间;样品浓度大于30 ng/μl;样品总量不小于500 μg,详细要求参见项目合同附件。 (4) 基因组De Novo组装完毕后需要构建BAC或Fosmid文库进行测序验证,用于BAC 或Fosmid文库构建的样品需要保证跟De Novo测序样本同一来源。 2. De Novo有几种测序方式 目前3种测序技术 Roche 454,Solexa和ABI SOLID均有单端测序和双端测序两种方式。在基因组De Novo测序过程中,Roche 454的单端测序读长可以达到400 bp,经常用于基因组骨架的组装,而Solexa和ABI SOLID双端测序可以用于组装scaffolds和填补gap。下面以solexa 为例,对单端测序(Single-read)和双端测序(Paired-end和Mate-pair)进行介绍。Single-read、Paired-end和Mate-pair主要区别在测序文库的构建方法上。 单端测序(Single-read)首先将DNA样本进行片段化处理形成200-500bp的片段,引物序列连接到DNA片段的一端,然后末端加上接头,将片段固定在flow cell上生成DNA簇,上机测序单端读取序列(图1)。 Paired-end方法是指在构建待测DNA文库时在两端的接头上都加上测序引物结合位点,在第一轮测序完成后,去除第一轮测序的模板链,用对读测序模块(Paired-End Module)引导互补链在原位置再生和扩增,以达到第二轮测序所用的模板量,进行第二轮互补链的合成测序(图2)。 图1 Single-read文库构建方法图2 Paired-end文库构建方法
Roche 454(GS FLX Titanium System)超高通量测序技术原理 2005年底,454公司推出了革命性的基于焦磷酸测序法的超高通量基因组测序系统——Genome Sequencer 20 System,被《Nature》杂志以里程碑事件报道,开创了边合成边测序(sequencing-by-synthesis)的先河。之后,454公司被罗氏诊断公司以1.55亿美元收购。2007年,他们又推出了性能更优的第二代基因组测序系统—— Genome Sequencer FLX System (GS FLX)。2008年10月,454推出了全新的GS FLX Titanium系列试剂和软件,让GS FLX的通量一下子提高了5倍,准确性和读长也进一步提升。 想当年,GS 20的出现,揭开了测序历史上崭新的一页。Jonathan Rothberg博士就是大规模并行测序的发明者,同时也是454的创始人。上世纪90年代,很多学者也都想到了大规模并行测序,他们试图将Sanger测序移到芯片上,但都以失败告终,因为这项技术没有可扩展性。1999年,Rothberg的儿子出世,他放了两个星期的陪产假。小家伙出生后被送入婴儿特护病房,Rothberg非常担心,甚至想获取儿子的基因组信息。这段担惊受怕的经历给了他灵感,他突然意识到焦磷酸测序(pyrosequencing)不仅简单,而且具有可扩展性。两个星期之后,Rothberg就开始设计芯片和流动室,让测序在更小的反应室中进行,并同时进行几百万个反应。 硬件的设计和制造也只是成功的一半,在样品制备上还有同样漫长的路要走。Rothberg摒弃了传统的细菌克隆与挑选,将DNA打断成随机片段,并寻找一种方法来克隆每个片段。受到其他学者乳液实验的启发,他也想将DNA放入油包水的乳液中,这样就省去了反应管。一个好汉三个帮。在Joel Bader等人的帮助下,Rothberg验证了这些想法的可行性,并利用了炸药中的表面活性剂来维持乳液的热稳定性。就这样,乳液PCR终于诞生了。 对细菌的16S rDNA的V6/V3可变区进行测序分析,不需进行克隆筛选,测序的通量高,获得的数据量大,周期短,能更加全面的反映微生物群体的物种组成,真实的物种分布及丰度信息。 GS FLX 测序原理 GS FLX系统的测序原理和GS 20一样,也是一种依靠生物发光进行DNA序列分析的新技术;在DNA聚合酶,ATP硫酸化酶,荧光素酶和双磷酸酶的协同作用下,将引物上每一个dNTP 的聚合与一次荧光信号释放偶联起来(图 1)。通过检测荧光信号释放的有无和强度,就可以达到实时测定DNA序列的目的。此技术不需要荧光标记的引物或核酸探针,也不需要进行电泳;具有分析结果快速、准确、灵敏度高和自动化的特点。 Roche GS FLX System是一种基于焦磷酸测序原理而建立起来的高通量基因组测序系统。在测序时,使用了一种叫做“Pico TiterPlate”(PTP)的平板,它含有160多万个由光纤组成的孔,孔中载有化学发光反应所需的各种酶和底物。测序开始时,放置在四个单独的试剂瓶里的四种碱基,依照T、A、C、G的顺序依次循环进入PTP板,每次只进入一个碱基。如果发生碱基配对,就会释放一个焦磷酸。这个焦磷酸在各种酶的作用下,经过一个合成反应和一个化学发光反应,最终将荧光素氧化成氧化荧光素,同时释放出光信号。此反应释放出的光信号实时被仪器配置的高灵敏度CCD捕获到。有一个碱基和测序模板进行配对,就会捕获到一分子的光信号;由此一一对应,就可以准确、快速地确定待测模板的碱基序列。
转录组测序技术的应用及发展综述 摘要:转录组测序(RNA-Seq)作为一种新的高效、快捷的转录组研究手段正在改变着人们对转录组的认识。RNA-Seq利用高通量测序技术对组织或细胞中所有RNA 反转录而成cDNA文库进行测序,通过统计相关读段(reads)数计算出不同RNA的表达量,发现新的转录本;如果有基因组参考序列,可以把转录本映射回基因组,确定转录本位置、剪切情况等更为全面的遗传信息,已广泛应用于生物学研究、医学研究、临床研究和药物研发等。文章主要比较近年来转录组研究的几种方法和几种RNA-Seq的研究平台,着重介绍RNA-Seq的原理、用途、步骤和生物信息学分析,并就RNA-Seq技术面临的挑战和未来发展前景进行了讨论及在相关领域的应用等内容,为今后该技术的研究与应用提供参考。 关键词: RNA-Seq;原理应用;方法;挑战;发展前景 Abstract:Transcriptome sequencing (RNA-Seq) is a kind of high efficiency, quick transcriptome research methods are changing our understanding of transcriptome. RNA-Seq to use high-throughput sequencing of tissues or cells of all RNA reverse transcription into cDNA library were sequenced, through statistical correlation read paragraph (reads) numbers were calculated from the expression of different RNA transcripts, find new; if the genome reference sequence, the transcripts mapped to genomic, determine the position of the transcription shear condition, more genetic information, has been widely used in biological research, medical research, clinical research and drug development. This paper compared several methods of platform transcriptome studies and several kinds of RNA-Seq in recent years, RNA-Seq focuses on the principle, purpose, steps and bioinformatics analysis, and discusses the RNA-Seq technology challenges and future development prospect and the application in related field and other content, provide the reference for the research and application of the technology future. Key word:RNA-Seq ;application; principle; method; challenge; development prospects
案例一 虽然RNA-seq早已被大家所熟知,特别是在高通量测序越来越便宜的今天,但是RNA-seq数据的分析仍令多数小菜抓狂。多个软件的使用,参数设置,参考基因组准备,输出结果的解读等等,都让很多初次接触测序数据或者非生物信息专业的人头疼不已。 哈哈,不用怕,有云生信,这都不是事儿!今天我就向大家简单介绍一下如何用云生信做RNA-seq数据的常规分析。不过在此之前,我要稍稍啰嗦一下RNA-seq的常规分析流程,请不要拍砖头。图1是RNA-seq数据从产生到分析的常规分析流程:根据实验设计,提取细胞RNA,并将RNA提交给测序公司,就可以坐等测序数据了。测序公司会根据客户提供的RNA进行建库,上机测序。拿到测序数据后,就到了我们大显身手的时候了。首先,我们要对测序结果做个简单的质量评估,剔除低质量的数据。然后,根据基因组数据(这里我们讲的是基因组数据已知的物种,基因组未知的有套独立的流程,这里不讲),将测序数据组装。根据组装结果,计算基因或转录本的表达量。最后,同芯片数据一样,我们可以根据表达量数据做很多分析,如差异表达分析,网络分析(包括蛋白互作网络,共表达网络等),也可以结合临床数据做分析(如预后,亚型分类、关联,药效等)。 图1. RNA-seq常规分析流程
叨叨完毕,进入正题。 进入尔云后,打开“测序数据处理”模块,我们会看到图2的结果。在这一模块,我们可以完成RNA-seq数据分析的前两步:1、数据质控和过滤低质量数据;2、基因组组装,计算基因表达量。对于上面两部,尔云又根据是双端测序还是单端测序,分了两块。以edgeR 为例,输出的DEGs.txt就是根据我们设定的参数得到的差异表达基因的列表,有geneSymbol, logCPM, PVlue信息。 图2. 测序数据处理模块 质控结束后,尔云会给出全部的质控结果。图3是以demo数据为例的双端测序的质控结果,好多好多呀,可以下了慢慢看。建议主要关注一下xxx_qc_TABLE,该表格是对质控前后的数据统计,反应了测序的好坏。Clean_xxx.fq是质控后的干净的fastq数据,是第2步组装的输入文件。 图3.质控结果 组装完成后,会返回一个expression.txt的表达矩阵文件,该文件是下一步差异表达分析的输入分析。 得到表达矩阵后,我们就可以进入到第3步差异表达数据分析。进入尔云的“差异分析”模块(如下图所示),它针对芯片和测序两种检测技术提供了不同的分析方案。对于RNA-seq
附件三生物信息学分析 一、基础生物信息学分析 1.有效测序序列结果统计 有效测序序列:所有含样品barcode(标签序列)的测序序列。 统计该部分序列的长度分布情况。 注:合同中约定测序序列条数以有效测序序列为准。 图形示例为: 2.优质序列统计 优质序列:有效测序序列中含有特异性扩增引物、不含模糊碱基、长度大于可供分析标准的序列。 统计该部分序列的长度分布情况。 图形示例为:
3.各样本序列数目统计: 统计各个样本所含有效测序序列和优质序列数目。 结果示例为: 4.OTU生成: 根据序列的相似性,将序列归为多个OTU(操作分类单元),以便后续分析。 5.稀释曲线(rarefaction 分析) 根据第4条中获得的OTU数据,做出每个样品的Rarefaction曲线。本合同默认生成OTU相似水平为0.03的rarefaction曲线。 rarefaction曲线结果示例:
6.指数分析 计算各个样品的相关分析指数,包括: ?丰度指数:ace\chao ?多样性指数:shannon\simpson ?本合同默认生成OTU相似水平为0.03的上述指数值。 多样性指数分析结果示例: 注:默认分析以上所列指数,如有特殊需要请说明。 7.Shannon-Wiener曲线 利用各样品的测序量在不同测序深度时的微生物多样性指数构建曲线,反映各样本在不同测序数量时的微生物多样性。当曲线趋向平坦时,说明测序数据量足够大,可以反映样品中绝大多数的微生物信息。绘制默认水平为:0.03。 例图:
8.Rank_Abuance 曲线 根据各样品的OTU丰度大小排序作丰度分布曲线图。结果文件默认为PDF格式(其它格式请注明)。 例图: 9.Specaccum物种累积曲线(大于10个样品) 物种累积曲线( species accumulation curves) 用于描述随着抽样量的加大物种增加的状况,是理解调查样地物种组成和预测物种丰富度的有效工具,在生物多样性和群落调查中,被广泛用于抽样量充分性的判断以及物种丰富度( species richness) 的估计。因此,通过物种累积曲线不仅可以判断抽样量是否充分,在抽样量充分的前提下,运用物种累积曲线还可以对物种丰富度进行预测。
导读从1977年第一代DNA测序技术(Sanger法)1,发展至今三十多年时间,测序技术已取得了相当大的发展,从第一代到第三代乃至第四代,测序读长从长到短,再从短到长。 摘要:从1977年第一代DNA测序技术(Sanger法)1,发展至今三十多年时间,测序 技术已取得了相当大的发展,从第一代到第三代乃至第四代,测序读长从长到短,再从短到长。虽然就当前形势看来第二代短读长测序技术在全球测序市场上仍然占有着绝对的优势位置,但第三和第四代测序技术也已在这一两年的时间中快速发展着。测序技术的每一次变革,也都对基因组研究,疾病医疗研究,药物研发,育种等领域产生巨大的推动作用。在这里我主要对当前的测序技术以及它们的测序原理做一个简单的小结。 图1:测序技术的发展历程 生命体遗传信息的快速获得对于生命科学的研究有着十分重要的意义。以上(图1)所描述的是自沃森和克里克在1953年建立DNA双螺旋结构以来,整个测序技术的发展历程。 第一代测序技术 第一代DNA测序技术用的是1975年由桑格(Sanger)和考尔森(Coulson)开创的链终止法或者是1976-1977年由马克西姆(Maxam)和吉尔伯特(Gilbert)发明的化学法(链降解). 并在1977年,桑格测定了第一个基因组序列,是噬菌体X174的,全长5375个碱基1。自此,人类获得了窥探生命遗传差异本质的能力,并以此为开端步入基因组学时代。研究人员在Sanger法的多年实践之中不断对其进行改进。在2001年,完成的首个人类基因组图谱就是以改进了的Sanger法为其测序基础,Sanger法核心原理是:由于ddNTP的2’和3’都不含羟基,其在DNA的合成过程中不能形成磷酸二酯键,因此可以用来中断DNA 合成反应,在4个DNA合成反应体系中分别加入一定比例带有放射性同位素标记的ddNTP(分为:ddATP,ddCTP,ddGTP和ddTTP),通过凝胶电泳和放射自显影后可以根据电泳带的位置确定待测分子的DNA序列(图2)。这个网址为 sanger测序法制作了一个小短片,形象而生动。 值得注意的是,就在测序技术起步发展的这一时期中,除了Sanger法之外还出现了一些其他的测序技术,如焦磷酸测序法、链接酶法等。其中,焦磷酸测序法是后来Roche公司454技术所使用的测序方法2–4,而连接酶测序法是后来ABI公司SOLID技术使用的测序方法2,4,但他们的共同核心手段都是利用了Sanger1中的可中断DNA合成反应的dNTP。
基因测序技术的优缺点及应用 随着人类基因组计划的完成,人类对自身遗传信息的了解和掌握有了前所未有的进步。与此同时,分子水平的基因检测技术平台不断发展和完善,使得基因检测技术得到了迅猛发展,基因检测效率不断提高。从最初第一代以 Sanger 测序为代表的直接检测技术和以连锁分析为代表的间接测序技术,到 2005 年,以Illumina 公司的 Solexa技术和 ABI 公司的 SOLiD 技术为标志的新一代测序 (next-generation sequencing,NGS) 的相继出现,测序效率明显提升,时间明显缩短,费用明显降低,基因检测手段有了革命性的变化。其技术正向着大规模、工业化的方向发展,极大地提高了基因检测的检出率,并扩展了疾病在基因水平的研究范围。2009 年 3 月,约翰霍普金斯大学的研究人员在《Science》杂志上发表了通过 NGS外显子测序技术,发现了一个新的遗传性胰腺癌的致病基因PALB2,标志着 NGS 测序技术成功应用于致病基因的鉴定研究。同年,《Nature》发表了采用 NGS 技术发现罕见弗里曼谢尔登综合征MYH3 致病基因突变和《Nat Genet》发表了遗传疾病米勒综合征致病基因。此后,通过 NGS 技术,与遗传相关的致病基因不断被发现,NGS 技术已成为里程碑式的进步。2010 年,《Science》杂志将这一技术评选为当年“十大科学进展”。 近两年,基因检测成为临床诊断和科学研究的热点,得到了突飞猛进和日新月异的发展,越来越多的临床和科研成果不断涌现出来。同时,基因检测已经从单一的遗传疾病专业范畴扩展到复杂疾病和个体化应用更加广阔的领域,其临床检测范围包括高危疾病的新生儿筛查、遗传疾病的诊断和基因携带的检测以及基因药物检测用于指导个体化用药剂量、选择和药物反应等诸多方面的研究。目前,基因检测在临床诊断和医学研究的应用正越来越受到医生的普遍重视和引起研究人员的极大的兴趣。 本文介绍了几种 DNA 水平基因检测常见的方法,比较其优缺点和在临床诊断和科学研究中的应用,对指导研究生和临床医生课外学习,推进临床科研工作和提升科研教学水平有着指导意义。 1、第一代测序 1.1 Sanger 测序采用的是直接测序法。1977年,Frederick Sanger 等发明了双脱氧链末端终止法,这一技术随后成为最为常用的基因测序技术。2001 年,Allan Maxam 和 Walter Gibert 发明了 Sanger 测序法,并在此后的 10 年里成为基因检测的金标准。其基本原理即双脱氧核苷三磷酸(dideoxyribonucleoside triphosphate,ddNTP) 缺乏PCR 延伸所需的 3'-OH,因此每当 DNA 链加入分子 ddNTP,延伸便终止。每一次 DNA 测序是由 4个独立的反应组成,将模板、引物和 4 种含有不同的放射性同位素标记的核苷酸的ddNTP 分别与DNA 聚合酶混合形成长短不一的片段,大量起始点相同、终止点不同的 DNA 片段存在于反应体系中,具有单个碱基差别的 DNA 序列可以被聚丙烯酰胺变性凝胶电泳分离出来,得到放射性同位素自显影条带。依据电泳条带读取DNA 双链的碱基序列。 人类基因组的测序正是基于该技术完成的。Sanger 测序这种直接测序方法具有高度的准确性和简单、快捷等特点。目前,依然对于一些临床上小样本遗传疾病基因的鉴定具有很高的实用价值。例如,临床上采用 Sanger 直接测序 FGFR 2 基因证实单基因 Apert 综合征和直接测序 TCOF1 基因可以检出多达 90% 的
高通量测序与功能分析 微生物群落测序是指对微生物群体进行高通量测序,通过分析测序序列的构成分析特定环境中微生物群体的构成情况或基因的组成以及功能。借助不同环境下微生物群落的构成差异分析我们可以分析微生物与环境因素或宿主之间的关系,寻找标志性菌群或特定功能的基因。对微生物群落进行测序包括两类,一类是通过16s rDNA,18s rDNA,ITS区域进行扩增测序分析微生物的群体构成和多样性;还有一类是宏基因组测序,是不经过分离培养微生物,而对所有微生物DNA进行测序,从而分析微生物群落构成,基因构成,挖掘有应用价值的基因资源。 以16s rDNA扩增进行测序分析主要用于微生物群落多样性和构成的分析,目前的生物信息学分析也可以基于16s rDNA的测序对微生物群落的基因构成和代谢途径进行预测分析,大大拓展了我们对于环境微生物的微生态认知。 目前我们根据16s的测序数据可以将微生物群落分类到种(species)(一般只能对部分菌进行种的鉴定),甚至对亚种级别进行分析, 几个概念: 16S rDNA(或16S rRNA):16S rRNA基因是编码原核生物核糖体小亚基的基因,长度约为1542bp,其分子大小适中,突变率小,是细菌系统分类学研究中最常用和最有用的标志。16S rRNA基因序列包括9个可变区和10个保守区,保守区序列反映了物种间的亲缘关系,而可变区序列则能体现物种间的差异。16S rRNA基因测序以细菌16S rRNA基因测序为主,核心是研究样品中的物种分类、物种丰度以及系统进化。 OTU:operational taxonomic units (OTUs)在微生物的免培养分析中经常用到,通过提取样品的总基因组DNA,利用16S rRNA或ITS的通用引物进行PCR 扩增,通过测序以后就可以分析样品中的微生物多样性,那怎么区分这些不同的序列呢,这个时候就需要引入operational taxonomic units,一般情况下,如
DNA测序结果分析比对(实例) 关键词:dna测序结果2013-08-22 11:59来源:互联网点击次数:14423 从测序公司得到的一份DNA测序结果通常包含.seq格式的测序结果序列文本和.ab1格式的测序图两个文件,下面是一份测序结果的实例: CYP3A4-E1-1-1(E1B).ab1 CYP3A4-E1-1-1(E1B).seq .seq文件可以用系统自带的记事本程序打开,.ab1文件需要用专门的软件打开。软件名称:Chromas 软件Chromas下载 .seq文件打开后如下图: .ab1文件打开后如下图: 通常一份测序结果图由红、黑、绿和蓝色测序峰组成,代表不同的碱基序列。测序图的两端(下图原图的后半段被剪切掉了)大约50个碱
基的测序图部分通常杂质的干扰较大,无法判读,这是正常现象。这也提醒我们在做引物设计时,要避免将所研究的位点离PCR序列的两端太近(通常要大于50个碱基距离),以免测序后难以分析比对。 我的课题是研究基因多态性的,因此下面要介绍的内容也主要以判读测序图中的等位基因突变位点为主。 实际上,要在一份测序图中找到真正确实的等位基因多态位点并不是一件容易的事情。一般认为等位基因位点假如在测序图上出现像套叠的两个峰,就是杂合子位点。实际比对后才知道,情况并非那么简单,下面测序图中标出的两个套峰均不是杂合子位点,如图并说明如下:
说明: 第一组套峰,两峰的轴线并不在同一位置,左侧的T峰是干扰峰;第二组套峰,虽两峰轴线位置相同,但两峰的位置太靠近了,不是杂合子峰,蓝色的C峰是干扰峰通常的杂合子峰由一高一略低的两个轴线相同的峰组成,此处的序列被机器误判为“C”,实际的序列应为“A”,通常一个高大碱基峰的前面 1~2个位点很容易产生一个相同碱基的干扰峰,峰的高度大约是高大碱基峰的1/2,离得越近受干扰越大。 一个摸索出来的规律是:主峰通常在干扰峰的右侧,干扰峰并不一定比主峰低。最关键的一点是一定要拿疑似为杂合子峰的测序图位点与测序结果的文本序列和基因库中的比对结果相比较;一个位点的多个样本相比较;你得出的该位点的突变率与权威文献或数据库中的突变率相比较。 通常,对于一个疑似突变位点来说,即使是国际上权威组织大样本的测序结果中都没有报道的话,那么单纯通过测序结果就判定它是突变点,是并不严谨的,因一份 PCR产物中各个碱基的实际含量并不相同,很难避免不产生误差的。对于一个未知突变位点的发现,通常还需要用到更精确的酶切技术。 (责任编辑:大汉昆仑王)
Pyrosequencing技术的原理 Pyrosequencing是一项全新的DNA测序技术,可以快速、准确地测定一段较短的目标片段。其基本原理如下: 第1步:1个特异性的测序引物和单链DNA模板结合,然后加入酶混合物(包括DNA Polymerase、ATP Sulfurylase、Luciferase和Apyrase)和底物混合物(包括APS和Luciferin)。 第2步:向反应体系中加入1种dNTP,如果它刚好能和DNA模板的下一个碱基配对,则会在DNA 聚合酶的作用下,添加到测序引物的3‘末端,同时释放出一个分子的焦磷酸(PPi)。 第2步图示(图片来自互联网) 第3步:在ATP硫酸化酶的作用下,生成的PPi可以和APS结合形成ATP;在荧光素酶的催化下,生成的ATP又可以和荧光素结合形成氧化荧光素,同时产生可见光。通过CCD光学系统即可获得一个特异的检测峰,峰值的高低则和相匹配的碱基数成正比。 第3步图示(图片来自互联网) 第4步:反应体系中剩余的dNTP和残留的少量ATP在Apyrase的作用下发生降解。 第4步图示(图片来自互联网) 第5步:加入另一种dNTP,使第2-4步反应重复进行,根据获得的峰值图即可读取准确的DNA序列信息。
第4步图示(图片来自互联网) Pyrosequecing技术操作简单,结果准确可靠,可应用于SNP位点检测、等位基因频率测定、细菌和病毒分型等领域。 →如果您认为本词条还有待完善,请编辑词条 上一篇SNP(单核苷酸多态性)下一篇阅读质粒图谱 具体事例 【摘要】建立了一种将序列标记反转录聚合酶链反应(PCR)与焦磷酸测序技术结合的相对基因表达量测定法(简称“SRPP”)。先用来源特异性引物对不同来源的同一基因通过反转录标记上特异性标签,PCR后用焦磷酸测序法对扩增产物进行序列解码,使得测序结果中的序列代表基因的来源,峰高代表基因在不同来源中的相对表达量。用实时荧光定量PCR法对本方法的准确性进行了验证,结果表明,SRPP可以同时准确测定同一基因在3个不同来源中的表达量,并实际测定了Egr1基因在糖尿病、肥胖和正常小鼠肝中的表达量差异。 【关键词】序列标记反转录, 聚合物链反应,焦磷酸测序,基因表达 1 引言 差异表达基因与疾病密切相关,深入研究可在基因水平揭示疾病的发病机制。目前,用于检测基因表达水平的技术主要有SAGE法[1]、实时荧光定量PCR法[2,3]和基因芯片法[4]等。但这些方法存在仪器设备昂贵、定量性能差以及同时测定基因表达量的来源数目受限等缺点。 焦磷酸测序技术是新近发展起来的一种基于酶催化化学反应的测序技术[5~8],不需要使用荧光标记,定量性能好。目前,焦磷酸测序技术多用于单核苷酸多态性(SNP)分析、微生物分型和基因甲基化分析等。本研究将焦磷酸测序技术用于基因表达量差异的比较分析,考察了其可行性和准确性,并将其应用于检测Egr1基因在糖尿病、肥胖症和正常小鼠中的差异表达。 2 实验部分 仪器、试剂与材料
高通量测序技术(High-throughput sequencing)又称“下一代”测序技术 ("Next-generation" sequencing technology),以能一次并行对几十万到几百万条DNA分子进行序列测定和一般读长较短等为标志。 根据发展历史、影响力、测序原理和技术不同等,主要有以下几种:大规模平行签名测序(Massively Parallel Signature Sequencing, MPSS)、聚合酶克隆(Polony Sequencing)、454焦磷酸测序(454 pyrosequencing)、Illumina (Solexa) sequencing、ABI SOLiD sequencing、离子半导体测序(Ion semiconductor sequencing)、DNA 纳米球测序(DNA nanoball sequencing)等。 高通量测序技术是对传统测序一次革命性的改变,一次对几十万到几百万条DNA分子进行序列测定,因此在有些文献中称其为下一代测序技术(next generation sequencing)足见其划时代的改变,同时高通量测序使得对一个物种的转录组和基因组进行细致全貌的分析成为可能,所以又被称为深度测序(deep sequencing)。 实验过程 1.样本准备(sample fragmentation) 2.文库构建(library preparation) 3.测序反应(sequencing reaction) 4.数据分析(data analysis) 测序平台 自从2005年454 Life Sciences公司(2007年该公司被Roche正式收购)推出了454 FLX焦磷酸测序平台(454 FLX pyrosequencing platform)以来,因为他们的拳头产品毛细管阵列电泳测序仪系列(series capillary array electrophoresis sequencing machines)遇到了两个强有力的竞争对手,曾推出过3730xl DNA测序仪(3730xl DNA Analyzer)的Applied BioSystem(ABI)这家一直占据着测序市场最大份额的公司的领先地位就开始动摇了,一个就是罗氏公司(Roche)的454 测序仪(Roch GS FLX sequencer),,另一个就是2006年美国Illumina公司推出的Solexa基因组分析平台(Genome Analyzer platform),为此,2007年ABI公司推出了自主研发的SOLiD 测序仪(ABI SOLiD sequencer)。这三个测序平台即为目前高通量测序平台的代表。(见表一) 公司名称技术原理技术开发者 Apply Biosystems(ABI) 基于磁珠的大规模并行克隆连接 DNA测序法 美国Agencourt私人基因组学公司(APG) Illumina 合成测序法英国Solexa公司首席科学家David Bentley Roche 大规模并行焦磷酸合成测序法 美国454 Life Sciences公司的创始人Jonathan Rothberg Helicos 大规模并行单分子合成测序法美国斯坦福大学生物工程学家Stephen Quake Complete Genomics DNA纳米阵列与组合探针锚定连接 测序法 美国Complete Genomics公司首席科学家radoje drmanac 表一:主流测序平台一览 Roche 454焦磷酸测序 (pyrophosphate sequencing) Illumina Solexa 合成测序 (sequence by synthesize) Illumina Genome AnalyzerIIx测序原理 Illumina公司的新一代测序仪Hiseq 2000和Hiseq 2500具有高准确性,高通量,高灵敏度,和低运行成本等突出优势,可以同时完成传统基因组学研究(测序和注释)以及功能基因组学(基因表达及调控,基因功能,蛋白/核酸相互作用)研究。Hiseq是一种基于单分子簇的边合成边测序技术,基于专有的可逆终止化学反应原理。测序时将基因组DNA的随机片段附着到光学透明
测序技术的发展历程 随着1953年沃森和克里克发现了DNA的双螺旋结构,到2001年,首个人类基因组图谱的绘制完成,人们越来越多的认识到测序在生物医学中的重要作用。 测序技术的发展历史 Sanger测序技术 1975年由桑格和考尔森开创的链终止法测序技术标志着人类第一代DNA测序技术的诞生。1977年,人类历史上第一个基因组序列噬菌体X174由桑格团队测序完成。自此,人类获得了窥探生命遗传差异本质的能力,并以此为开端步入基因组学时代。 SangerJ.D. Waston、F.Crick
虽然第一代测序技术的测序读长可达1000bp,准确性高达99.999%,但其测序成本高,通量低等方面的缺点,严重影响了其真正大规模的应用。因而第一代测序技术并不是最理想的测序方法。从那时起人们开始了二代测序技术的探索。 第二代测序技术 第二代测序技术的核心思想是边合成边测序(Sequencing by Synthesis),在Sanger等测序方法的基础上,通过技术创新,用不同颜色的荧光标记四种不同的dNTP,当DNA聚合酶合成互补链时,每添加一种dNTP就会释放出不同的荧光,根据捕捉的荧光信号并经过特定的计算机软件处理,从而获得待测DNA的序列信息。 现有的技术平台主要包括Roche/454 FLX(已宣布停产)、Illumina Hiseq Miseq等系列和Applied Biosystems SOLID system。 Roche/454 FLX Illumina Hiseq 2500 AB SOLID 第三代测序技术 第二代测序技术虽然较Sanger测序有了巨大的突破,但是其测序的理论基础仍然建立在PCR扩增的基础之上。为了有效的避免测序过程中由于PCR扩增带来的偏差,科学家们积极投身到第三代单分子测序仪研究当中。目前最具代表性的包括Heliscope单分子实时合成测序法,纳米孔测序技术等。