
本文档尝试解答如下问题:
如何使用OpenCV函数CvSVM::train训练一个SVM分类器,以及用CvSVM::predict测试训练结果。
支持向量机(SVM) 是一个类分类器,正式的定义是一个能够将不同类样本在样本空间分隔的超平面。换句话说,给定一些标记(label)好的训练样本(监督式学习), SVM算法输出一个最优化的分隔超平面。
如何来界定一个超平面是不是最优的呢? 考虑如下问题:
假设给定一些分属于两类的2维点,这些点可以通过直线分割,我们要找到一条最优的分割线.
Note
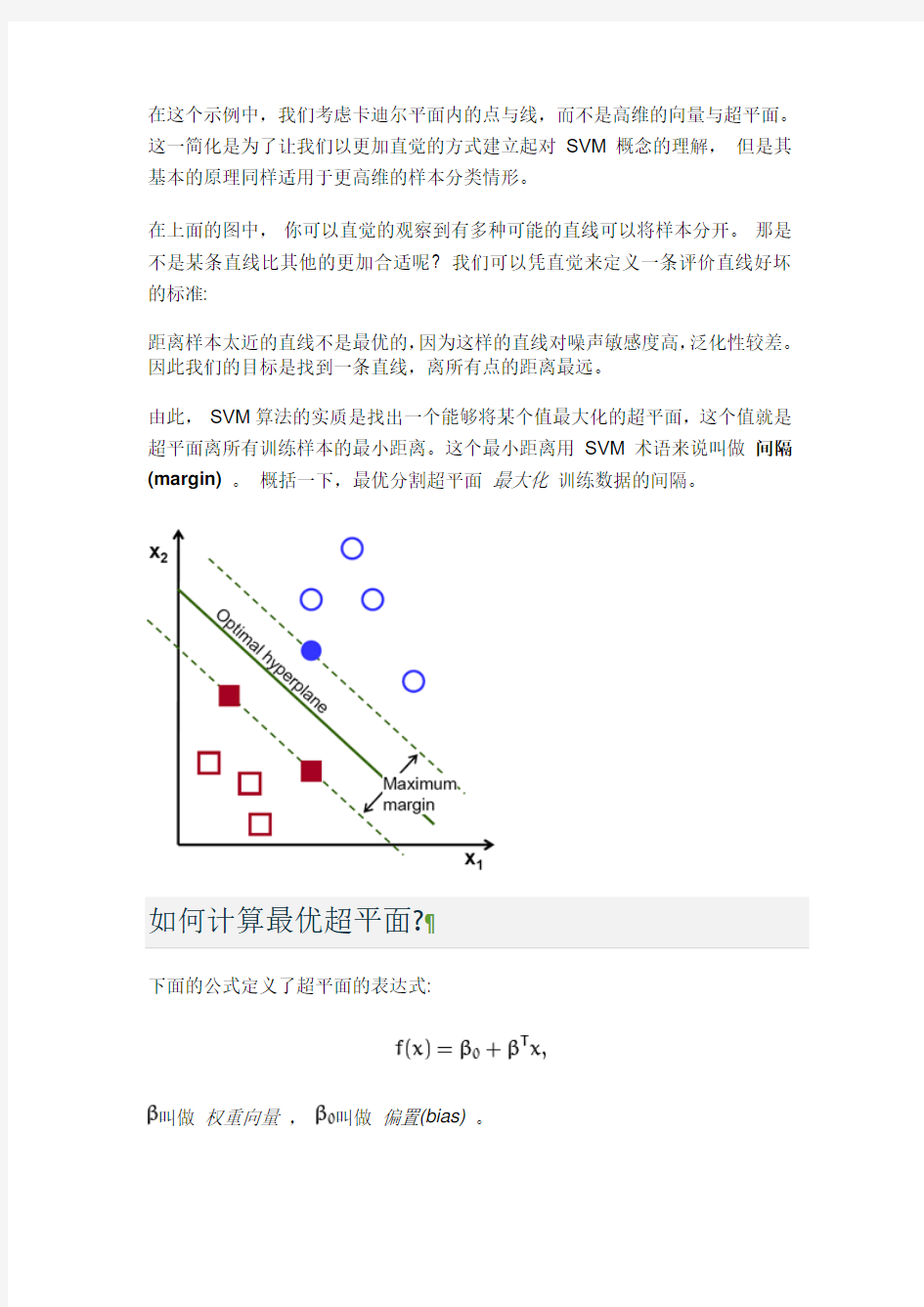
在这个示例中,我们考虑卡迪尔平面内的点与线,而不是高维的向量与超平面。这一简化是为了让我们以更加直觉的方式建立起对SVM概念的理解,但是其基本的原理同样适用于更高维的样本分类情形。
在上面的图中,你可以直觉的观察到有多种可能的直线可以将样本分开。那是不是某条直线比其他的更加合适呢? 我们可以凭直觉来定义一条评价直线好坏的标准:
距离样本太近的直线不是最优的,因为这样的直线对噪声敏感度高,泛化性较差。因此我们的目标是找到一条直线,离所有点的距离最远。
由此,SVM算法的实质是找出一个能够将某个值最大化的超平面,这个值就是超平面离所有训练样本的最小距离。这个最小距离用SVM术语来说叫做间隔(margin)。概括一下,最优分割超平面最大化训练数据的间隔。
下面的公式定义了超平面的表达式:
叫做权重向量,叫做偏置(bias)。
See also
关于超平面的更加详细的说明可以参考T. Hastie, R. Tibshirani 和J. H. Friedman的书籍Elements of Statistical Learning,section 4.5 (Seperating Hyperplanes)。
最优超平面可以有无数种表达方式,即通过任意的缩放和。习惯上我们使用以下方式来表达最优超平面
式中表示离超平面最近的那些点。这些点被称为支持向量**。该超平面也称为**canonical 超平面.
通过几何学的知识,我们知道点到超平面的距离为:
特别的,对于canonical 超平面, 表达式中的分子为1,因此支持向量到canonical 超平面的距离是
刚才我们介绍了间隔(margin),这里表示为, 它的取值是最近距离的2倍:
最后最大化转化为在附加限制条件下最小化函数。限制条件隐含超平面将所有训练样本正确分类的条件,
式中 表示样本的类别标记。
这是一个拉格朗日优化问题,
可以通过拉格朗日乘数法得到最优超平面的权重向量 和偏置
。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29 #include
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66 CvSVM SVM;
SVM.train(trainingDataMat, labelsMat, Mat(), Mat(), params);
Vec3b green(0,255,0), blue (255,0,0);
// Show the decision regions given by the SVM
for (int i =0; i < image.rows; ++i)
for (int j =0; j < image.cols; ++j)
{
Mat sampleMat = (Mat_
float response = SVM.predict(sampleMat);
if (response ==1)
image.at
else if (response ==-1)
image.at
}
// Show the training data
int thickness =-1;
int lineType =8;
circle( image, Point(501, 10), 5, Scalar( 0, 0, 0), thickness, lineType);
circle( image, Point(255, 10), 5, Scalar(255, 255, 255), thickness, lineType);
circle( image, Point(501, 255), 5, Scalar(255, 255, 255), thickness, lineType);
circle( image, Point( 10, 501), 5, Scalar(255, 255, 255), thickness, lineType);
// Show support vectors
thickness =2;
lineType =8;
int c = SVM.get_support_vector_count();
for (int i =0; i < c; ++i)
{
const float* v = SVM.get_support_vector(i);
67
68 circle( image, Point( (int) v[0], (int) v[1]), 6, Scalar(128, 128, 128), thickness, lineType);
}
imwrite("result.png", image); // save the image
imshow("SVM Simple Example", image); // show it to the user waitKey(0);
}
建立训练样本
本例中的训练样本由分属于两个类别的2维点组成,其中一类包含一个样本点,另一类包含三个点。
函数CvSVM::train要求训练数据储存于float类型的Mat结构中,因此我们定义了以下矩阵:
Mat trainingDataMat(3, 2, CV_32FC1, trainingData);
Mat labelsMat (3, 1, CV_32FC1, labels);
设置SVM参数
此教程中,我们以可线性分割的分属两类的训练样本简单讲解了SVM的基本原理。然而,SVM的实际应用情形可能复杂得多(比如非线性分割数据问题,SVM 核函数的选择问题等等)。总而言之,我们需要在训练之前对SVM做一些参数设定。这些参数保存在类CvSVMParams中。
params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6); SVM类型. 这里我们选择了CvSVM::C_SVC类型,该类型可以用于n-类分类问题(n 2)。这个参数定义在CvSVMParams.svm_type属性中.
Note
CvSVM::C_SVC类型的重要特征是它可以处理非完美分类的问题(及训练数据不可以完全的线性分割)。在本例中这一特征的意义并不大,因为我们的数据是可以线性分割的,我们这里选择它是因为它是最常被使用的SVM类型。
SVM 核类型. 我们没有讨论核函数,因为对于本例的样本,核函数的讨论没有必要。然而,有必要简单说一下核函数背后的主要思想,核函数的目的是为了将训练样本映射到更有利于可线性分割的样本集。映射的结果是增加了样本向量的维度,这一过程通过核函数完成。此处我们选择的核函数类型是CvSVM::LINEAR表示不需要进行映射。该参数由CvSVMParams.kernel_type属性定义。
算法终止条件. SVM训练的过程就是一个通过迭代方式解决约束条件下的二次优化问题,这里我们指定一个最大迭代次数和容许误差,以允许算法在适当的条件下停止计算。该参数定义在cvTermCriteria结构中。
训练支持向量机
调用函数CvSVM::train来建立SVM模型。
CvSVM SVM;
SVM.train(trainingDataMat, labelsMat, Mat(), Mat(), params);
SVM区域分割
函数CvSVM::predict通过重建训练完毕的支持向量机来将输入的样本分类。本例中我们通过该函数给向量空间着色,及将图像中的每个像素当作卡迪尔平面上的一点,每一点的着色取决于SVM对该点的分类类别:绿色表示标记为1的点,蓝色表示标记为-1的点。
for (int i =0; i < image.rows; ++i)
for (int j =0; j < image.cols; ++j)
{
Mat sampleMat = (Mat_
float response = SVM.predict(sampleMat);
if (response ==1)
image.at
else
if (response ==-1)
image.at
}
支持向量
这里用了几个函数来获取支持向量的信息。函数CvSVM::get_support_vector_count输出支持向量的数量,函数CvSVM::get_support_vector根据输入支持向量的索引来获取指定位置的支持向量。通过这一方法我们找到训练样本的支持向量并突出显示它们。
int c = SVM.get_support_vector_count();
for (int i =0; i < c; ++i)
{
const float*v =SVM.get_support_vector(i); // get and then highlight with grayscale
circle( image, Point( (int) v[0], (int) v[1]), 6, Scalar(128, 128, 128), thickness, lineType);
}
程序创建了一张图像,在其中显示了训练样本,其中一个类显示为白色圆圈,另一个类显示为黑色圆圈。
训练得到SVM,并将图像的每一个像素分类。分类的结果将图像分为蓝绿两部分,中间线就是最优分割超平面。
最后支持向量通过灰色边框加重显示。
支持向量机(SVM )原理及应用 一、SVM 的产生与发展 自1995年Vapnik (瓦普尼克)在统计学习理论的基础上提出SVM 作为模式识别的新方法之后,SVM 一直倍受关注。同年,Vapnik 和Cortes 提出软间隔(soft margin)SVM ,通过引进松弛变量i ξ度量数据i x 的误分类(分类出现错误时i ξ大于0),同时在目标函数中增加一个分量用来惩罚非零松弛变量(即代价函数),SVM 的寻优过程即是大的分隔间距和小的误差补偿之间的平衡过程;1996年,Vapnik 等人又提出支持向量回归 (Support Vector Regression ,SVR)的方法用于解决拟合问题。SVR 同SVM 的出发点都是寻找最优超平面(注:一维空间为点;二维空间为线;三维空间为面;高维空间为超平面。),但SVR 的目的不是找到两种数据的分割平面,而是找到能准确预测数据分布的平面,两者最终都转换为最优化问题的求解;1998年,Weston 等人根据SVM 原理提出了用于解决多类分类的SVM 方法(Multi-Class Support Vector Machines ,Multi-SVM),通过将多类分类转化成二类分类,将SVM 应用于多分类问题的判断:此外,在SVM 算法的基本框架下,研究者针对不同的方面提出了很多相关的改进算法。例如,Suykens 提出的最小二乘支持向量机 (Least Square Support Vector Machine ,LS —SVM)算法,Joachims 等人提出的SVM-1ight ,张学工提出的中心支持向量机 (Central Support Vector Machine ,CSVM),Scholkoph 和Smola 基于二次规划提出的v-SVM 等。此后,台湾大学林智仁(Lin Chih-Jen)教授等对SVM 的典型应用进行总结,并设计开发出较为完善的SVM 工具包,也就是LIBSVM(A Library for Support Vector Machines)。LIBSVM 是一个通用的SVM 软件包,可以解决分类、回归以及分布估计等问题。 二、支持向量机原理 SVM 方法是20世纪90年代初Vapnik 等人根据统计学习理论提出的一种新的机器学习方法,它以结构风险最小化原则为理论基础,通过适当地选择函数子集及该子集中的判别函数,使学习机器的实际风险达到最小,保证了通过有限训练样本得到的小误差分类器,对独立测试集的测试误差仍然较小。 支持向量机的基本思想:首先,在线性可分情况下,在原空间寻找两类样本的最优分类超平面。在线性不可分的情况下,加入了松弛变量进行分析,通过使用非线性映射将低维输
1.文件中数据格式 label index1:value1 index2:value2 ... Label在分类中表示类别标识,在预测中表示对应的目标值 Index表示特征的序号,一般从1开始,依次增大 Value表示每个特征的值 例如: 3 1:0.122000 2:0.792000 3 1:0.144000 2:0.750000 3 1:0.194000 2:0.658000 3 1:0.244000 2:0.540000 3 1:0.328000 2:0.404000 3 1:0.402000 2:0.356000 3 1:0.490000 2:0.384000 3 1:0.548000 2:0.436000 数据文件准备好后,可以用一个python程序检查格式是否正确,这个程序在下载的libsvm文件夹的子文件夹tools下,叫checkdata.py,用法:在windows命令行中先移动到checkdata.py所在文件夹下,输入:checkdata.py 你要检查的文件完整路径(包含文件名) 回车后会提示是否正确。
2.对数据进行归一化。 该过程要用到libsvm软件包中的svm-scale.exe Svm-scale用法: 用法:svmscale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename (缺省值: lower = -1,upper = 1,没有对y进行缩放) 其中, -l:数据下限标记;lower:缩放后数据下限; -u:数据上限标记;upper:缩放后数据上限; -y:是否对目标值同时进行缩放;y_lower为下限值,y_upper 为上限值;(回归需要对目标进行缩放,因此该参数可以设定为–y -1 1 ) -s save_filename:表示将缩放的规则保存为文件save_filename; -r restore_filename:表示将缩放规则文件restore_filename载入后按此缩放; filename:待缩放的数据文件(要求满足前面所述的格式)。 数据集的缩放结果在此情况下通过DOS窗口输出,当然也可以通过DOS的文件重定向符号“>”将结果另存为指定的文件。该文件中的参数可用于最后面对目标值的反归一化。反归一化的公式为:
clear all; clc; N=35; %样本个数 NN1=4; %预测样本数 %********************随机选择初始训练样本及确定预测样本******************************* x=[]; y=[]; index=randperm(N); %随机排序N个序列 index=sort(index); gama=23.411; %正则化参数 deita=0.0698; %核参数值 %thita=; %核参数值 %*********构造感知机核函数************************************* %for i=1:N % x1=x(:,index(i)); % for j=1:N % x2=x(:,index(j)); % K(i,j)=tanh(deita*(x1'*x2)+thita); % end %end %*********构造径向基核函数************************************** for i=1:N x1=x(:,index(i)); for j=1:N x2=x(:,index(j)); x12=x1-x2; K(i,j)=exp(-(x12'*x12)/2/(deita*deita)); End End %*********构造多项式核函数**************************************** %for i=1:N % x1=x(:,index(i)); % for j=1:N % x2=x(:,index(j)); % K(i,j)=(1+x1'*x2)^(deita); % end %end %*********构造核矩阵************************************ for i=1:N-NN1 for j=1:N-NN1 omeiga1(i,j)=K(i,j); end end
支持向量机算法推导及其分类的算法实现 摘要:本文从线性分类问题开始逐步的叙述支持向量机思想的形成,并提供相应的推导过程。简述核函数的概念,以及kernel在SVM算法中的核心地位。介绍松弛变量引入的SVM算法原因,提出软间隔线性分类法。概括SVM分别在一对一和一对多分类问题中应用。基于SVM在一对多问题中的不足,提出SVM 的改进版本DAG SVM。 Abstract:This article begins with a linear classification problem, Gradually discuss formation of SVM, and their derivation. Description the concept of kernel function, and the core position in SVM algorithm. Describes the reasons for the introduction of slack variables, and propose soft-margin linear classification. Summary the application of SVM in one-to-one and one-to-many linear classification. Based on SVM shortage in one-to-many problems, an improved version which called DAG SVM was put forward. 关键字:SVM、线性分类、核函数、松弛变量、DAG SVM 1. SVM的简介 支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。支持向量机方法是建立在统计学习理论的VC 维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力。 对于SVM的基本特点,小样本,并不是样本的绝对数量少,而是与问题的复杂度比起来,SVM算法要求的样本数是相对比较少的。非线性,是指SVM擅长处理样本数据线性不可分的情况,主要通过松弛变量和核函数实现,是SVM 的精髓。高维模式识别是指样本维数很高,通过SVM建立的分类器却很简洁,只包含落在边界上的支持向量。
SVM 方法步骤 彭海娟 2010-1-29 看了一些文档和程序,大体总结出SVM 的步骤,了解了计算过程,再看相关文档就比较容易懂了。 1. 准备工作 1) 确立分类器个数 一般都事先确定分类器的个数,当然,如有必要,可在训练过程中增加分类器的个数。分类器指的是将样本中分几个类型,比如我们从样本中需要识别出:车辆、行人、非车并非人,则分类器的个数是3。 分类器的个数用k 2) 图像库建立 SVM 方法需要建立一个比较大的样本集,也就是图像库,这个样本集不仅仅包括正样本,还需要有一定数量的负样本。通常样本越多越好,但不是绝对的。 设样本数为S 3) ROI 提取 对所有样本中的可能包含目标的区域(比如车辆区域)手动或自动提取出来,此时包括正样本中的目标区域,也包括负样本中类似车辆特征的区域或者说干扰区域。 4) ROI 预处理 包括背景去除,图像滤波,或者是边缘增强,二值化等预处理。预处理的方法视特征的选取而定。 5) 特征向量确定 描述一个目标,打算用什么特征,用几个特征,给出每个特征的标示方法以及总的特征数,也就是常说的特征向量的维数。 对于车辆识别,可用的特征如:车辆区域的灰度均值、灰度方差、对称性、信息熵、傅里叶描述子等等。 设特征向量的维数是L 。 6) 特征提取 确定采取的特征向量之后,对样本集中所有经过预处理之后的ROI 区域进行特征提取,也就是说计算每个ROI 区域的所有特征值,并将其保存。 7) 特征向量的归一化 常用的归一化方法是:先对相同的特征(每个特征向量分别归一化)进行排序,然后根据特征的最大值和最小值重新计算特征值。 8) 核的选定 SVM 的构造主要依赖于核函数的选择,由于不适当的核函数可能会导致很差的分类结果,并且目前尚没有有效的学习使用何种核函数比较好,只能通过实验结果确定采用哪种核函数比较好。训练的目标不同,核函数也会不同。 核函数其实就是采用什么样的模型描述样本中目标特征向量之间的关系。如常用的核函数:Gauss 函数 2 1),(21x x x p e x x k --= 对样本的训练就是计算p 矩阵,然后得出描述目标的模板和代表元。 2. 训练 训练就是根据选定的核函数对样本集的所有特征向量进行计算,构造一个使样本可分的
svm为什么需要核函数 本来自己想写这个内容,但是看到了一篇网上的文章,觉得写得很好,这样我就不自己写了,直接转载人家的。我在两处加粗红了,我觉得这两处理解了,就理解了svm中kernel的作用。 1.原来在二维空间中一个线性不可分的问题,映射到四维空间后,变成了线性可分的!因此这也形成了我们最初想解决线性不可分问题的基本思路——向高维空间转化,使其变得线性可分。 2.转化最关键的部分就在于找到x到y的映射方法。遗憾的是,如何找到这个映射,没有系统性的方法(也就是说,纯靠猜和凑)。 3.我们其实只关心那个高维空间里内积的值,那个值算出来了,分类结果就算出来了。 4.核函数的基本作用就是接受两个低维空间里的向量,能够计算出经过某个变换后在高维空间里的向量内积值。 列一下常用核函数: 线性核函数: 多项式核函数: 高斯核函数: 核函数: 下面便是转载的部分: 转载地址:https://www.doczj.com/doc/0817926193.html,/zhenandaci/archive/2009/03/06/258288.html 生存?还是毁灭?——哈姆雷特 可分?还是不可分?——支持向量机 之前一直在讨论的线性分类器,器如其名(汗,这是什么说法啊),只能对线性可分的样本做处理。如果提供的样本线性不可分,结果很简单,线性分类器的求解程序会无限循环,永远也解不出来。这必然使得它的适用范围大大缩小,而它的很多优点我们实在不原意放弃,怎么办呢?是否有某种方法,让线性不可分的数据变得线性可分呢? 有!其思想说来也简单,来用一个二维平面中的分类问题作例子,你一看就会明白。事先声明,下面这个例子是网络早就有的,我一时找不到原作者的正确信息,在此借用,并加进了我自己的解说而已。 例子是下面这张图: 我们把横轴上端点a和b之间红色部分里的所有点定为正类,两边的黑色部分里的点定为负类。试问能找到一个线性函数把两类正确分开么?不能,因为二维空间里的线性函数就是指直线,显然找不到符合条件的直线。
SVM(Support Vector Machine) 支持向量机相关理论介绍 基于数据的机器学习是现代智能技术中的重要方面,研究从观测数据(样本)出发寻找规律,利用这些规律对未来数据或无法观测的数据进行预测。迄今为止,关于机器学习还没有一种被共同接受的理论框架,关于其实现方法大致可以分为三种[3]: 第一种是经典的(参数)统计估计方法。包括模式识别、神经网络等在内,现有机器学习方法共同的重要理论基础之一是统计学。参数方法正是基于传统统计学的,在这种方法中,参数的相关形式是已知的,训练样本用来估计参数的值。这种方法有很大的局限性。 首先,它需要已知样本分布形式,这需要花费很大代价,还有,传统统计学研究的是样本数目趋于无穷大时的渐近理论,现有学习方法也多是基于此假设。但在实际问题中,样本数往往是有限的,因此一些理论上很优秀的学习方法实际中表现却可能不尽人意。 第二种方法是经验非线性方法,如人工神经网络(ANN)。这种方法利用已知样本建立非线性模型,克服了传统参数估计方法的困难。但是,这种方法缺乏一种统一的数学理论。与传统统计学相比,统计学习理论(Statistical Learning Theory或SLT)是一种专门研究小样本情况下机器学习规律的理论。该理论针对小样本统计问题建立了一套新的理论体系,在这种体系下的统计推理规则不仅考虑了对渐近性能的要求,而且追求在现有有限信息的条件下得到最优结果。V. Vapnik等人从六、七十年代开始致力于此方面研究,到九十年代中期,随着其理论的不断发展和成熟,也由于神经网络等学习方法在理论上缺乏实质性进展,统计学习理论开始受到越来越广泛的重视。 统计学习理论的一个核心概念就是VC维(VC Dimension)概念,它是描述函数集或学习机器的复杂性或者说是学习能力(Capacity of the machine)的一个重要指标,在此概念基础上发展出了一系列关于统计学习的一致性(Consistency)、收敛速度、推广性能(Generalization Performance)等的重要结论。 统计学习理论是建立在一套较坚实的理论基础之上的,为解决有限样本学习问题提供了一个统一的框架。它能将很多现有方法纳入其中,有望帮助解决许多原来难以解决的问题(比如神经网络结构选择问题、局部极小点问题等); 同时,这一理论基础上发展了一种新的通用学习方法──支持向量机(Support Vector Machine或SVM),已初步表现出很多优于已有方法的性能。一些学者认为,SLT和SVM正在成为继神经网络研究之后新的研究热点,并将推动机器学习理论和技术有重大的发展。 支持向量机方法是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力(Generalizatin Ability)。支持向量机方法的几个主要优点