
ODI 11G初探—数据传输
Start:2011.01.21
Updated:2011.01.24
王凡
wangfan
wf141732@https://www.doczj.com/doc/0615198624.html,
woshiwangfan@https://www.doczj.com/doc/0615198624.html,
1.简介
ODI是oracle的数据抽取工具,11G融合了wls和jdev,与10G相比出现了教大幅度的
变化。
1.1.环境信息
OS:WINDOWSXP -32bit
ORACLE-DB:XE10G
WLS:10.3.3
ODI:11.1.1.3
RCU:11.1.1.3
PostgreSQL:9.0.2
1.2.相关文档
2.软件准备
2.1.软件下载
Oracle相关页面下载
Postgresql-jdbc:https://www.doczj.com/doc/0615198624.html,/download/postgresql-9.0-
801.jdbc4.jar
3.安装
很郁闷开始等了很久才出现安装对话框,windows安装直接下一步!
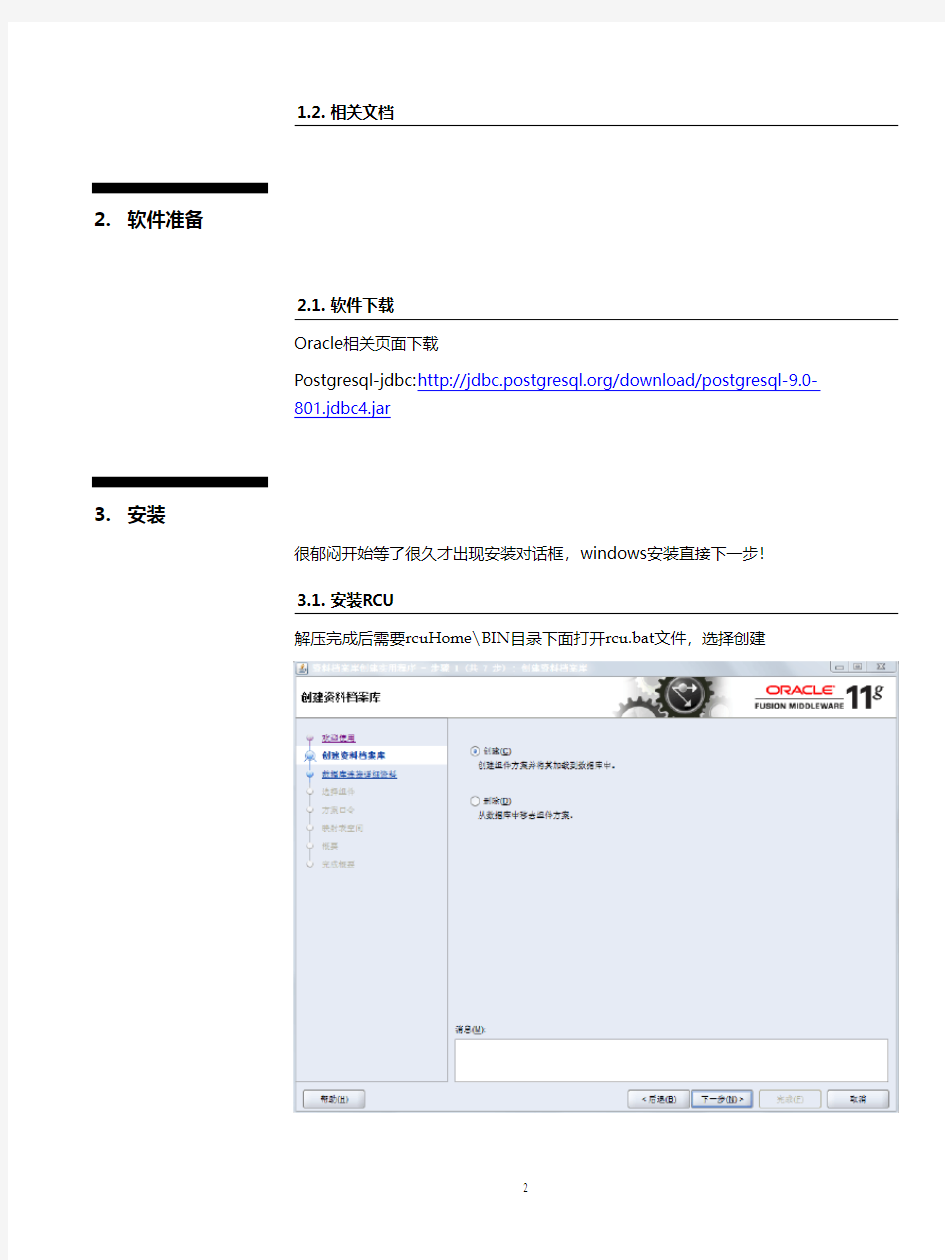
3.1.安装RCU
解压完成后需要rcuHome\BIN目录下面打开rcu.bat文件,选择创建
填写数据库连接信息
作校验
选择需要安装的数据库对象
填写ODI数据库用户口令
填写ODI相关对象信息,主资料库ID,口令,可以填写默认
创建表空间
开始创建
表空间创建完毕后作创建对象前确实
开始创建主资料库和工作资料库
3.2.安装wls
直接下一步,步骤略!
3.3.安装odi
解压后到disk1中点击setup,选择需要按照的ODI对象,本机上安装服务器和编辑器!
作检查
选择安装目录
数据库连接信息
ODI应用超级用户口令
选择创建的工作资料库
代理名称和代理端口
操作系统会确认使用端口,可以关闭防火墙!
确认安装信息
开始安装
开始配置!
安装完毕!
3.4.创建DOMAIN
进入$ODI_HOME$\common\bin\运行config.cmd来创建domain
填写domain的名称
Weblogic域管理员口令
选择java sdk
填写数据库连接信息
作数据库连接信息验证
选择domain功能配置
管理服务器信息配置
受管理server
计算机配置
下一步到集群,由于不作集群,直接到下一步分配server
服务安装
配置概要
开始创建域
2.5数据仓库模型的设计 数据仓库模型的设计大体上可以分为以下三个层面的设计151: .概念模型设计; .逻辑模型设计; .物理模型设计; 下面就从这三个层面分别介绍数据仓库模型的设计。 2.5.1概念模型设计 进行概念模型设计所要完成的工作是: <1>界定系统边界 <2>确定主要的主题域及其内容 概念模型设计的成果是,在原有的数据库的基础上建立了一个较为稳固的概念模型。因为数据仓库是对原有数据库系统中的数据进行集成和重组而形成的数据集合,所以数据仓库的概念模型设计,首先要对原有数据库系统加以分析理解,看在原有的数据库系统中“有什么”、“怎样组织的”和“如何分布的”等,然后再来考虑应当如何建立数据仓库系统的概念模型。一方面,通过原有的数据库的设计文档以及在数据字典中的数据库关系模式,可以对企业现有的数据库中的内容有一个完整而清晰的认识;另一方面,数据仓库的概念模型是面向企业全局建立的,它为集成来自各个面向应用的数据库的数据提供了统一的概念视图。 概念模型的设计是在较高的抽象层次上的设计,因此建立概念模型时不用考虑具体技术条件的限制。 1.界定系统的边界 数据仓库是面向决策分析的数据库,我们无法在数据仓库设计的最初就得到详细而明确的需求,但是一些基本的方向性的需求还是摆在了设计人员的面前: . 要做的决策类型有哪些? . 决策者感兴趣的是什么问题? . 这些问题需要什么样的信息? . 要得到这些信息需要包含原有数据库系统的哪些部分的数据? 这样,我们可以划定一个当前的大致的系统边界,集中精力进行最需要的部分的开发。因而,从某种意义上讲,界定系统边界的工作也可以看作是数据仓库系统设计的需求分析,因为它将决策者的数据分析的需求用系统边界的定义形式反映出来。 2,确定主要的主题域 在这一步中,要确定系统所包含的主题域,然后对每个主题域的内
在科学技术飞速发展的今天,科研功能日益凸显,鉴于如今的科学研究已远非单兵作战所能完成,大量地需要团队的联合攻关,因此科研创新团队这种组织形式应运而生并日益引起人们的高度关注。“创新”是科学研究的灵魂, 是一个科研院所获取研究成果不竭的动力。当今科学技术的发展趋势是学科间不断交叉、彼此渗透,使一些新的学科、新的领域不断产生, 出现了许多交叉学科、边缘学科和横断学科。这些新的学科领域正是创新的前沿阵地, 往往需要多学科、跨学科合作, 需要团队联合攻关。科研创新团队是孕育科研创新的一个重要摇篮, 确定具有前瞻性的研究方向, 构建和谐的研究梯队以及培养能够激发灵感的学术 文化氛围, 是科研创新的三大基本要素。要创造出更多的原创性科研成果, 就必须抓住机遇, 建设强有力的科研创新团队, 不断开发创新能力。 中科院南海海洋研究所海洋天然药物化学学科组成立于2006年1月,从成立之初,“百人计划”刘永宏研究员孤身一人,到现在由杨献文副研究员,周雪峰助理研究员,李云秋,柴兴云博士后, 4名博士生,硕士生1人,以及和华南理工大学联合培养的博士一名,组成的研究团队,形成有百人计划研究员-副研究员-助理研究员-博士后-客座研究人员-研究生的合理的人才链条,既有稳定的人才队伍,又有合理的人才流动,随时注入新鲜的血液,保证科学研究的“鲶鱼效应”。 一、创新团队科研目标的凝练 一个共同、远大、可实现的研究目标是科研创新团队的灵魂, 是关系到科研创新团队建设成功与否的重要问题。远大、明确可行的共同目标可以使创新团队始终围绕既定目标而不偏离这个轨道, 减少资源浪费。团队目标的实现还可以使成员精神振奋并获得成就感, 明白自己的角色和任务, 从而使工作上相互联系、相互合作的成员更加团结, 真正组成一个高效、稳定的科研创新团队。 海洋天然药物化学学科组研究创新团队的目标主要包括以下三个方面: 一是围绕海洋生物活性物质的研究方向进行基础研究和应用基础研究, 以高水平的原创性知识为目标, 争创国际一流科技成果; 二是培养和造就具有突出创新能力的人才和群体; 三是成为所在 天然产物学科领域的领头羊, 创造巨大的无形资产价值。 海洋天然药物化学学科组的主要研究领域为海洋生物活性物质的研究,以海洋天然产物化学研究为基础,以海洋生物中防治重要疾病创新药物先导结构的发现与优化为主要研究方向。主要研究内容包括:综合运用现代分离、分析技术与活性追踪相结合的方法,研究发现海洋生物中用于防治严重危害人类健康的重要疾病创新药物先导结构或目标分子;对发现的重要活性先导化合物进行系统的结构修饰或合成研究,探讨相关衍生物的结构与活性的关系,发现结构简单、活性强、毒性小的新药研究目标分子。近年来,开展了一些海洋化学生态学研究,旨在通过海洋生物学,生态学和海洋天然产物化学等多学科的配合,从仿生学的观点,以抗污损生物附着活性筛选为导向,结合现代色谱学,现代波谱学,现代色谱-波谱联机技术,快速分离并结构确定海洋生物中的抗藤壶幼虫附着靶向化学防御物质,改构活性成分,发现生产新的抗附着先导结构,研究抗附着活性与结构关系,总结出显效基团,在此基础上进行抗其它污损生物附着活性的研究,探讨海洋生物抗附着化合物与环境竞争适应机
实时计算,流数据处理系统简介与简单分析 发表于2014-06-12 14:19| 4350次阅读| 来源CSDN博客| 8条评论| 作者va_key 大数据实时计算流计算 摘要:实时计算一般都是针对海量数据进行的,一般要求为秒级。实时计算主要分为两块:数据的实时入库、数据的实时计算。今天这篇文章详细介绍了实时计算,流数据处理系统简介与简单分析。 编者按:互联网领域的实时计算一般都是针对海量数据进行的,除了像非实时计算的需求(如计算结果准确)以外,实时计算最重要的一个需求是能够实时响应计算结果,一般要求为秒级。实时计算的今天,业界都没有一个准确的定义,什么叫实时计算?什么不是?今天这篇文章详细介绍了实时计算,流数据处理系统简介与简单分析。 以下为作者原文: 一.实时计算的概念 实时计算一般都是针对海量数据进行的,一般要求为秒级。实时计算主要分为两块:数据的实时入库、数据的实时计算。 主要应用的场景: 1) 数据源是实时的不间断的,要求用户的响应时间也是实时的(比如对于大型网站的流式数据:网站的访问PV/UV、用户访问了什么内容、搜索了什么内容等,实时的数据计算和分析可以动态实时地刷新用户访问数据,展示网站实时流量的变化情况,分析每天各小时的流量和用户分布情况) 2) 数据量大且无法或没必要预算,但要求对用户的响应时间是实时的。比如说: 昨天来自每个省份不同性别的访问量分布,昨天来自每个省份不同性别不同年龄不同职业不同名族的访问量分布。 二.实时计算的相关技术 主要分为三个阶段(大多是日志流): 数据的产生与收集阶段、传输与分析处理阶段、存储对对外提供服务阶段
下面具体针对上面三个阶段详细介绍下 1)数据实时采集: 需求:功能上保证可以完整的收集到所有日志数据,为实时应用提供实时数据;响应时间上要保证实时性、低延迟在1秒左右;配置简单,部署容易;系统稳定可靠等。 目前的产品:Facebook的Scribe、LinkedIn的Kafka、Cloudera的Flume,淘宝开源的TimeTunnel、Hadoop的Chukwa等,均可以满足每秒数百MB的日志数据采集和传输需求。他们都是开源项目。 2)数据实时计算 在流数据不断变化的运动过程中实时地进行分析,捕捉到可能对用户有用的信息,并把结果发送出去。 实时计算目前的主流产品:
数据分析平台 分析平台 实时加载 & 查询 高级库内分析 数据设计 & 管理工具 列式存储 & 执行 强劲的数据压缩 扩展的MPP架构 自动的高可用性 优化器, 执行引擎 & 负载管理 内在的 BI, ETL, & Hadoop/MapReduce 集成 Vertica的分析平台为特定目的建造的,以使公司从他们的数据中提取价值,他们需要在今天的经济环境中茁壮成长的速度和规模。不像大多数其它的数据仓库供应商正试图改造21世纪的技术,几十年的老基础设施,Vertica的设计和建造自成立以来,为当今最苛刻的分析工作负载。此外,每一个的Vertica的成分是由设计,能够充分利用其他。
Vertica分析平台关键特性 实时查询 & 加载 ?通过不断加载的信息,获取数据的时间 价值,同时允许立即进行丰富的分析。 高级的库内分析 ?不断增长的特点和功能库,展示和处理 更多和CPU内核紧密结合的数据,而无需解压。 数据设计 & 管理工具 ?强大的设置,调整和控制以达到使 用最小的管理工作,就可以进行持续改进,而系统仍然保 持在线。 列式存储 & 执行 ?执行查询快50 - 1000倍,消除了昂贵的 磁盘I / O,没有的索引和物化视图的麻烦和开销。 强劲的数据压缩 ?我们的引擎,以较少的资本性支出完成 更多的压缩数据,同时提供卓越的性能。 可扩展的MPP架构 ?Vertica的自动和无限线性扩展,只需 在网格中添加行业标准x86服务器 自动的高可用性 ?不间断地运行与优化,提供卓越的查询 性能,良好的自动冗余,故障切换和恢复。 优化器执行引擎 & 负载管理 ?获得最大的性能,而无需担 心它如何工作的细节。用户只思考有关的问题,我们快速 地提供答案。 内在的 BI, ETL, & Hadoop/MapReduce 集成 ?一个强大和 不断增长的生态系统的分析解决方案的无缝集成。 今天,世界各地的信息是连续产生的。因此,隔夜批量加载 数据已经成为奢侈的过去。组织必须能够不停顿地加载到信 息到他们的分析平台,同时允许进行数据丰富的分析。 信息的时间价值是非常重要的,在数据产生后,用户越早处理就越有价值。对于零售商来说,这可能意味着即时的 促销和库存的摆放。对于金融公司,这会影响到及时的交易 决策。对于网络游戏公司,这提供了更加个性化和引人入胜 的游戏体验。这个最小延迟的量是不容易的壮举。因为从网 络源,用户鼠标点击,金融交易,传感器网络和越来越多的 其他来源的信息量是压倒性的挑战。
提升数据保护:Oracle数据仓库的实时数据采集在使用数据仓库软件时,最常见的约束之一是源系统数据批量提取处理时的可用时间窗口。通常,极其耗费资源的提取流程必须在非工作时间进行,而且仅限于访问关键的源系统。 低影响实时数据整合软件可以释放系统的批处理时间。当提取组件使用非侵入式方法时,如通过读取数据库事务日志,只会捕捉发生变化的数据,不会对源系统产生影响。因此,数据提取流程可以在任意时段全天候执行,即使用户在线也可以。 当以实时方式提取数据时,虽然必须改变数据采集流程中各个元素支持实时数据的方式,但是这些数据可以带来不一般的业务价值。而且,这些数据必须得到有效的保护,同时也很难针对这些不停变化的数据应用灾难恢复和备份技术。 但是,在数据仓库中应用实时数据整合的技术也可以进一步保护数据。毕竟,实时移动数据的技术也可以实时操作数据,从而形成一个数据保护技术入口。但是,变化数据的速度和效率可能会受制于数据保护流程的延迟。
这意味着,在转到整合数据仓库的主动数据采集模式时,首要考虑的问题之一是数据经过IT系统的流程和可能产生的延迟。换而言之,实时数据整合要求理解变化的数据,以及促进或妨碍这种变化的组件。 显然,企业希望保护他们的数据。然而,随着数据容量需求的增长,存储技术也成为业务持续性依赖的重要业务资产。而且,随着实时分析成为业务流程的一部分,它也归入到业务持续性的范畴之中。实现数据安全性和持续性的最基本方法是硬件或软件复制,它会自动保存第二个关键数据副本。此外,自行创建或基于开源软件创建的备份方法也不存在。 企业级数据管理应用主要涉及5个重要领域:灾难恢复、高可用性、备份、数据处理性能和更高级数据库移植。这促使IT不停地追寻先进技术,如实现数据整合及其相关基础架构元素。此外,这些战略投资能够提供符合预算的资源,在加快实时技术应用的同时,提高投资回报和修正实时数据整合项目的商业提案。
科研团队建设方案 如果建设一个科研团队的话应该怎么筹备呢?以下是本人收集的相关资料,仅供大家阅读参考! 科研团队建设方案一“科研立校、科研兴校、科研强校”是我们一直都非常重视的一项工作。为进一步深化新一轮基础教育课程改革,大力开展素质教育,全面提高我校教科研水平,打造一支优秀的教科研团队,助推教师专业成长,促学校发展,今结合我校实际,制订本方案。 以科学发展观为指导,以大力提升我校教科研水平为目标,树立“以科研促教研,以教研促教学,以教学促质量”的教育科研理念,坚持“以教育科研为先导,以科研课题研究为载体,以常规教学研究为基础,以课堂教学改革为突破口”的科研导向,组建学校教科研团队,发挥科研团队的辐射、指导作用,以点带面,努力提升团队教科研水准,力争使学校教师“全员、全过程”扎实开展教科研活动,从而提高学校教科研工作的整体水平,真正让教科研成为提升教师个人专业成长、提高教育教学质量,促进学校发展的助推器。 通过系统培训、自主学习、互动实践、课题研究等多种方式实现下列目标: 1、培养一批研究型教师,使其成为学校教科研的积极参与者、活动者,营造良好的科研氛围。 2、打造一支乐于奉献,勇于创新,善于合作的科研团
队,使其成为我校能够依靠的教育科研基本力量。 3、充分发挥科研团队的辐射和引领作用,以课题研究为载体全程参与,使学校教科研工作在不同的研究领域、不同的研究层次得到均衡,持久的发展。 4.确定相对稳定的学校主攻研究方向,制定相关的工作职责及管理制度,使科研团队成员在制度的管理下,在权益的保障下,循序渐进履行职责,凝聚团队合作力量,打造具有“创新意识、时代特色、学校本色”的学校科研文化。 1、组建科研团队 学校科研团队成员在个人申请,教科室审核,学校领导小组商议,经校务公开栏公示后,即为资格的获得。 2、确定研究方向 参考学校历年来的课题研究内容,结合近期学校教育教学发展实际情况,暂将研究方向确定为以下三大类:有关学校新办学思路方向的研究。 原有的有特色课题继续深化研究。 体现教师个人特色的课题研究。 3、明确相关职责 团队职责: 教科研团队要认真制定活动计划,做到定人员、定地点、定时间、定内容,学年末要认真总结。 教科研团队每月至少活动一次,活动内容要遵循理论学
毕业设计(论文) 题 目: 语音播报实时数据处理系统的设计与实现 学生姓名: 学 号: 所在学院: 专业班级: 届 别: 指导教师:
本科毕业设计(论文)创作诚信承诺书 1.本人郑重承诺:所提交的毕业设计(论文),题目《基于单片机的实验室环境检测》是本人在指导教师指导下独立完成的,没有弄虚作假,没有抄袭、剽窃别人的内容; 2.毕业设计(论文)所使用的相关资料、数据、观点等均真实可靠,文中所有引用的他人观点、材料、数据、图表均已标注说明来源; 3. 毕业设计(论文)中无抄袭、剽窃或不正当引用他人学术观点、思想和学术成果,伪造、篡改数据的情况; 4.本人已被告知并清楚:学校对毕业设计(论文)中的抄袭、业设计(论文)成绩不合格,无法正常毕业、取消学士学位资格或注销并追回已发放的毕业证书、学士学位证书等严重后果; 5.若在省教育厅、学校组织的毕业设计(论文)检查、评比中,被发现有抄袭、剽窃、弄虚作假等违反学术规范的行为,本人愿意接受学校按有关规定给予的处理,并承担相应责任。 学生(签名): 日期:年月日 目录
1绪论 (2) 2系统设计 (3) 2.1设计需求 (3) 2.2系统原理 (3) 3系统硬件设计 (4) 3.1电源模块 (4) 3.2微控制器模块 (5) 3.3非特定人声语音模块 (5) 3.4 DHT11数字温\湿度传感器 (7) 3.5 ENC28J60以太网模块 (9) 4系统软件设计 (10) 4.1整体流程 (10) 4.2以太网模块软件方案 (12) 4.3语音模块软件方案 (13) 5 系统调试 (14) 5.1硬件电路故障及解决方法 (15) 5.2硬件调试方法 (15) 6结束语 (15) 参考文献: (17)
数据仓库生产环境操作手册 一.运维概述 “数据仓库生产系统”的运行维护责任在于保障系统运行,运维方式主要是操作员通过工作机远程登陆到系统中的相关主机,对主机进行操作,包括automation 调度系统、数据库、磁盘、软件环境、数据情况等,查看批出理的运行情况,一 旦运行出现问题作相应的记录并通知相关的技术人员,作出相应的处理。 所有运维项目成员严格按照《数据仓库系统运维守则.doc》文档来进行运维检查工作,否则出现事故由值班人员和当日值班负责人承担事故责任。 二.运维内容 1.每日维护 1.1数据检查 每日批处理运行前运行完成后都需要对源头的数据和生产出的数据进行检查,确保当日批处理程序正常从事生产。检查工作在每日9:00-9:30之间完成,且必须在启动程序(批处理程序)前执行。具体规定如下: 1.1.1 转定长数据的检查 每天上午9:00--9:45之间,运维值班人员进行这项工作具体执行步骤如下: 1.在本地工作机上使用telnet远程登录工具登录到168.7.6.163服务器上,输入用户名sjtq,密码:cib2009edw, 2.输入命令cd EDW/sh/log 3.输入命令more yyyymmdd当天的日志,是否有错误信息,最后数据是否都上传结束。 4.以下错误属于正常情况: 03:00:03 : 1.检查20091031标志文件失败~~~~~~~~~ 03:00:03 : 1.数据标志检查失败,等待5分钟(06001/dta_varied) 正常等待情况 5.检查点如下: 1)每个大任务开始的初始化操作 03:00:00 : ================ 0.环境变量设置完毕================
浅谈高校科研团队组织建设 高校的科学研究工作在国家科研领域发挥着重要作用,深入挖掘高校科研潜力,对于推动国家科技进步和促进地方经济发展具有显著的现实意义。高校科研团队是以学术研究中心、课题和项目组等为代表的,由为数不多的技能互补的、愿意为共同的科研目的、科研目标和工作方法而相互承担责任的,为实现某个科研目标而明确分工协作,具有良好的互动性和凝聚力的正式群体。高校创新型科研团队的建设,有利于发挥团体优势,聚集学科优势,凝练特色研究方向。随着科技合作和科技共享更加紧密,每一项重大科技成果的背后都有一个或者多个团队的支撑,团队成了高校科研的基本单位。构建高校科研创新团队组织,能使团队内部和谐统一、通力协作,把在科学研究上相互联系、相互依存的科研人员通过团队的形式组织在一起,通过分工合作,分享与交换信息,来完成个人和一般团体所无法完成的更高层次的科研任务。 一、高校科研创新团队组织建设的重要性 创新团队是为了满足现代科学的交叉综合趋势而产生的一种科研组织形式,是在原有科研组织模式和运行机制上大胆创新的一种尝试。随着科学技术的飞速发展,科学研究已经决不是某个个体所能独立实现的,建设科研创新团队是新时期科学研究创新的必要前提,因此,在高校,建设科研创新团队已经变得非常重要。 1、科研创新团队建设能有效提升学科水平,支撑学科发展 科学技术发展已使得传统意义上科学家的个人奋斗无法适应科
研工作的要求,科学家之间需要合作,而团队的建设可以形成设备和人力资源的有效凝聚,共同完成重大项目的科技攻关,产生具有显示度的、前瞻性的研究成果。 2、科研创新团队的建设能更好地促进创新思想和创新成果的产生 高校的研究工作大多属于创新型研究,这就要求高校科研人员必须具有创新思维。创新团队的建设提供了相互交流信息,切磋思想,阐述见解的渠道,培育了不同学科知识交叉、互补、综合的土壤,容易形成相对完整的知识结构,从而不断完善自己的创新与成果。 3、创新团队所创造的氛围可以促使学者自身更快速、健康地成长 如果不参与团队工作,个人认识往往具有局限性,在学术探究、追求真理的认识过程中,也没有机会敞开胸怀,自觉容纳他人的指点批评,因而容易产生学术上的武断作风和片面性观点。创新团队建设能使大家在平等、民主、自由、活跃的学术气氛中,对学术问题尽心交流讨论、比较参考、批判创新和融化组合,进而去寻找和推敲真理,从而有力地推动学术研究的发展。 二、高校科研创新团队的组织构建 1、构建原则 (1)适时引导原则 不少科研团队是由于科研人员有相同的兴趣和爱好,在科研项目的合作中自发形成、自组织发展起来的。政府和高校政府管理部门应及时发现,适时引导和培育,营造有利于高校创新型科研团队成长和发展的环境,为其创造良好的发展氛围和环境,在政策上给予必要的
基于贝尔宾角色理论的教学团队建设研究与实践 摘要:教学团队建设是提高技工院校教师教育教学水平,促进师资队伍建设的有效途径之一。本文以贝尔宾团队角色理论为基础,分析目前教学团队建设现状,提出结合贝尔宾角色理论建设技工院校有效教学团队的方法。 关键词:贝尔宾团队角色理论教学团队 教学团队是指在教师队伍中形成的有一定知识技能,愿意为了共同的目标而由相互协作、技能互补、共同努力的个体所组成的群体。教学团队由于成员不同的个性特征,其评价标准又具有多维性。什么样的教学团队结构最为合理,如何根据团队成员的特点发挥成员间的优势互补作用,提升团队建设质量,就成为技工教育研究者们所关注的问题。而贝尔宾(Belbin)的角色理论正是具备多维度的判断标准和层次性理论体系,对技工院校教学团队建设有着积极的指导意义。 一、技工院校教学团队建设的现实意义 技工教育是以为企业提供技术工人为导向的教育,因此要提高学生的专业技术能力,师资队伍建设是关键。2014 年12月23日,人力资源和社会保障部下发的《关于推进技工院校改革创新的若干意见》指出:“技工院校办学实力和办
学水平逐步提高,培养了大批高素质技能人才,在促进就业和服务经济社会发展中发挥了重要作用。但同时也要看到,当前技工教育还不能完全适应经济社会发展的需要,办学条件薄弱,发展不均衡,培养能力和质量有待提高。”要提高技工院校的培养能力,师资队伍建设是关键所在。技工院校从传统的教育模式向校企合作的一体化教学模式转型,让技工院校的专业教学特征发生了根本性的变化,而要适应这一变化,必须对师资资源进行有效整合,建设教学团队,提高师资队伍整体素质,增强技工院校的核心竞争力。 二、贝尔宾团队角色理论简介 团队角色理论之父――英国剑桥产业培训研究部前主任梅雷迪斯?贝尔宾博士经过九年的研究,把团队成员定义为九种不同的角色,它们是:协调者、智多星、外交家、推进者、监督员、凝聚者、执行者、完美主义者和专家。这九种角色具有不同的角色特征,在团队中擅长不同的工作,见表1。建设一个优秀团队,其成员一是要具备九种角色特征,二是要根据成员特征合理分配团队成员工作,形成优势互补,促进团队健康、平稳发展。 三、目前技工院校教学团队现状分析 笔者对相关学校的教学团队成员就年龄、学历、职称、教龄、职务等方面形成因素做了如下调查统计,见表2。 从上表调查数据不难发现,教学团队成员的年龄构成、
第1章数据仓库建设 1.1 数据仓库总体架构 专家系统接收增购项目车辆TCMS或其他子系统通过车地通信传输的实时或离线数据,经过一系列综合诊断分析,以各种报表图形或信息推送的形式向用户展示分析结果。针对诊断出的车辆故障将给出专家建议处理措施,为车辆的故障根因修复提供必要的支持。 根据专家系统数据仓库建设目标,结合系统数据业务规范,包括数据采集频率、数据采集量等相关因素,设计专家系统数据仓库架构如下: 数据仓库架构从层次结构上分为数据采集、数据存、数据分析、数据服务等几个方面的内容: 数据采集:负责从各业务自系统中汇集信息数据,系统支撑Kafka、Stor
m、Flume及传统的ETL采集工具。 数据存储:本系统提供Hdfs、Hbase及RDBMS相结合的存储模式,支持海量数据的分布式存储。 数据分析:数据仓库体系支持传统的OLAP分析及基于Spark常规机器学习算法。 数据服务总线:数据系统提供数据服务总线服务,实现对数据资源的统一管理和调度,并对外提供数据服务。 1.2 数据采集 专家系统数据仓库数据采集包括两个部分内容:外部数据汇集、内部各层数据的提取与加载.外部数据汇集是指从TCMS、车载子系统等外部信息系统汇集数据到专家数据仓库的操作型存储层(ODS);内部各层数据的提取与加载是指数据仓库各存储层间的数据提取、转换与加载。 1.2.1外部数据汇集 专家数据仓库数据源包括列车监控与检测系统(TCMS)、车载子系统等相关子系统,数据采集的内容分为实时数据采集和定时数据采集两大类,实时数据采集主要对于各项检测指标数据;非实时采集包括日检修数据等。 根据项目信息汇集要求,列车指标信息采集具有采集数据量大,采集频率高的特点,考虑到系统后期的扩展,因此在数据数据采集方面,要求采集体系支持高吞吐量、高频率、海量数据采集,同时系统应该灵活可配置,可根据业务的需要进行灵活配置横向扩展。 本方案在数据采集架构采用Flume+Kafka+Storm的组合架构,采用Flume 和ETL工具作为Kafka的Producer,采用Storm作为Kafka的Consumer,Storm可实现对海量数据的实时处理,及时对问题指标进行预警。具体采集系统技术结构图如下:
团队角色测试 角色测试:认识你自己的角色类型 一个完整的团队是由众多的角色构成的,杜海滨博士通过对上千家企业、数千个团队数十年的研究得出一个结论:优秀的团队有以下各种角色: 图5-1 团队中的各种角色 每一个团队都需要这样一些角色,通过教材附带的团队角色自我测评问卷(见工具表单),可以得知每个员工最适合扮演的角色类型和最不擅长扮演的角色类型。 这个问卷共有七道题,每道题有ABCDEFGH八个描述,每题10分,可以根据最能体现个人平时行为的状况去判断哪一个描述更像自己。在这8个描述中你认为最像自己的描述,就给它高一点的分数。比方说A描述“我能够很快的发现并把握住新的机遇”比较像我,而且程度比较大,我给他4分或5分,分数的高低就取决于像你的程度。最极端的情况就是给其中一个描述10分,而其它7个描述没有分数。 这七道题每一题十分,总共是70分,这些分数必须分配完,不能不够70分。但也不能超过70分,也不能把第一题的10分分配到第二题。用10分钟的时间完成这个练习,每一道题都答完后,请把答案抄到最后的分析表格上,最后把这个表格中竖道的每一个得分相加,总共有8个结果,准确地算出每一项上的得分是多少。 测试三:团队角色测试 对下列问题的回答,可能在不同程度上描绘了您的行为。每题有8句话,请将10分分配给这8个句子。分配的原则是:最能体现您行为的句子分最高,依此类推。最极端的情况也可能是10分全部分配给其中的某一句话。请根据您的实际情况把分数填入后面的答题纸中。 1.我认为我能为团队做出的贡献是: a.我能很快地发现并把握住新的机遇。 b.我能与各种类型的人一起台作共事。 c.我生来就爱出主意。 d.我的能力在于,一旦发现某些对实现集体目标很有价值的人,我就及时把他们推荐出来。 e.我能把事情办成,这主要靠我个人的实力。 f.如果最终能导致有益的结果,我愿面对暂时的冷遇。 g.我通常能意识到什么是现实的,什么是可能的。 h.在选择行动方案时,我能不带倾向性,也不带偏见地提出一个合理的替代方案。 2.在团队中,我可能有的弱点是: a.如果会议没有得到很好的组织、控制和主持,我会感到不痛快。 b.我容易对那些有高见而又没有适当地发表出来的人表现得过于宽容。 c.只要集体在讨论新的观点,我总是说的太多。 d.我的客观看法,使我很难与同事们打成一片。 e.在一定要把事情办成的情况下,我有时使人感到特别强硬以至专断。 f.可能由于我过分重视集体的气氛,我发现自己很难与众不同。 g.我易于陷入突发的想象之中,而忘了正在进行的事情。 h.我的同事认为我过分注意细节,总有不必要的担心,怕把事情搞糟。
网络工程(物联网技术) 课程设计报告 题目:基于温湿度传感器物联网应用实时数据处理系统开发 院(系)别:数学与信息工程学院 专业:网络工程(物联网技术)班级 1 班 学号:2006099914 姓名:小明 指导教师:职称博士 填表日期:2012 年 5 月11 日
前言 一、选题的依据及意义 1.依据 物联网是一种新概念和新技术,它使新一代IT技术更加充分地应用于各行各业之中。它的问世打破了过去将基础设施与IT设施分开的传统观念,将建筑物、公路、铁路和网站、网络、数据中心合为一体,是信息化和工业化融合的重要切入点。温湿度与人们的生活关系密切,所以物联网在温湿度实时数据处理系统的开发将有很大的前景。 2.意义 在我们的日常生活中无处不在,控制好温湿度可以使我们生活、生产的更好。温湿度传感器物联网应用实时数据处理系统开发可以帮我们实现对温湿度以实时数据让我们明了的知道。从而更好的控制温湿度、达到我们所需的标准。 二、本课程设计内容简介 1. 通过ubuntu连接传感器实验箱收集由传感器测得的实时数据存入sqlite3数据库。 2. 然后通过ubuntu发送到linux、接收并用动态网页显示代表数据变化的曲线。 三、要达到的目标 1.可以在ubuntu上实现自动接收由传感器取得、传来的实时数据。 2. 并ubuntu上能边接收边连续往linux发送从传感器取得的实时数据。 3.还要确保发送过的数据不会再次发送。 4. Linux能接收到ubuntu发过来的实时数据并通过动态网页曲线图实时显示接收过来的数据。实现方案 一、开发环境 1.硬件(详细介绍所涉及硬件的详细内容) Pc机、温湿度传感器、传感器实验箱、连接所需的各种线。 2.软件(详细介绍所涉及软件的详细内容) MDK414(arm平台编译烧录代码软件)、KeilC51v750a_Full(C51平台编译软件)、STC手动下载(C51烧录代码软件)、R340(串口线连接USB驱动)、ubuntu操作系统、linux操作系统。
图片简介: 本技术介绍了一种实时数据仓库平台,该实时数据仓库平台包括:业务数据采集系统、日志数据采集系统、分析系统;业务数据采集系统包括candu模块,candu模块对业务数据的变更日志进行同步解析,并将解析后的数据存储至分析系统的kudu存储模块中;日志数据采集系统,用于收集日志数据、对日志数据进行计算,并将计算结果存储至kudu存储模块中;kudu 存储模块根据存储的解析后的数据和计算结果进行实时的数据分析。本技术通过candu模块实时收集分布在各个业务系统上的业务数据的变更日志,实现了业务数据的实时同步。 技术要求 1.一种实时数据仓库平台,其特征在于,包括:业务数据采集系统、日志数据采集系统、分析系统; 所述业务数据采集系统包括candu模块,所述candu模块对业务数据的变更日志进行同步解析,并将解析后的数据存储至所述分析系统的kudu存储模块中; 所述日志数据采集系统,用于收集日志数据、对所述日志数据进行计算,并将计算结果 存储至kudu存储模块中; 所述kudu存储模块根据存储的所述解析后的数据和所述计算结果进行实时的数据分析。
2.根据权利要求1所述的实时数据仓库平台,其特征在于,所述日志数据采集系统包括: kafka模块,所述日志数据写入所述kafka模块中。 3.根据权利要求2所述的实时数据仓库平台,其特征在于,所述日志数据采集系统还包括: spark streaming模块,读取所述kafka模块中的所述日志数据、进行实时计算,并将所述计算结果存储至kudu存储模块中。 4.根据权利要求1所述的实时数据仓库平台,其特征在于,所述业务数据采集系统还包括: 业务数据库,用于记录业务数据的变更日志; canal模块,通过模拟与业务数据库的交互协议,使得所述业务数据库向所述canal模块推送所述变更日志。 5.根据权利要求1所述的实时数据仓库平台,其特征在于,所述分析系统还包括: impala分析引擎,利用所述impala分析引擎以实现实时的数据分析。 6.根据权利要求1所述的实时数据仓库平台,其特征在于,所述candu模块包括: Operation子模块,用于通过kudu原生api的异步写入模式,将所述解析后的数据存储至所述kudu存储模块中。 7.根据权利要求6所述的实时数据仓库平台,其特征在于,所述candu模块还包括: 读取子模块,用于从所述candu模块中存储的配置表; Exchange子模块,用于进行配置表数据的初始化同步。 8.根据权利要求6所述的实时数据仓库平台,其特征在于,所述candu模块还包括: Manager子模块,用于管理多个Task线程,所述Operation子模块在Task线程中将所述解析后的数据存储至所述kudu存储模块中。
170 ?电子技术与软件工程 Electronic Technology & Software Engineering 数据库技术 ? Data Base Technique 【关键词】大数据 实时计算 物联网 实践 物联网是在互联网应用的基础上进行了进一步拓展。其主要具有移动、智能、多节点的特点。而Spark 为大数据实时计算工作提供了一个优良的数据储存计算引擎,其在实际数据应用过程中,可利用自身优良的计算性能及多平台兼容特性,实现大数据混合计算处理。因此为了保证物联网数据处理效率,对大数据混合计算模式在物联网中的实践应用进行适当分析具有非常重要的意义。 1 基于Spark的大数据混合计算模型 基于Spark 的大数据混合计算模式在实际设计过程中,首先需要进行数据源的确定,经过逐步处理后将其进行计算储存,并通过实时查询数据库进行提前数据Web 接口的设置。在这个基础上,将不同数据源数据通过分布式处理模式进行移动、收集、分发。然后利用Spark 数据批处理工作,综合采用直接走流处理、程序批处理的方式,将实施应用数据调到已核算完毕的计算结果中间。最后基于物联网应用特点,将数据源数据内部数据移动、收集及分发批处理模块进行有机整合,并结合大数据域内数据处理需求,逐渐利用SparklShark 架构代替MapreducelHIve 结构。在这个基础上进行Spark 混合计算规则融入,最终形成完善的Spark 混合计算模型架构。 2 大数据实时计算在物联网中的实践 2.1 以流处理为基础的用量实时计算系统 以流处理为基础的用量实时计算系统在物联网中的实践应用,主要是利用开源分布式 物联网大数据处理中实时流计算系统的实践 文/吴海建1 吕军2 软件结构的架设,结合Flume 数据收集模块的 设置。同时将物联网中不同数据源进行接入差异化分析。在这个基础上利用消息缓存系统保障模块,将用量实时计算系统内部相关模块间进行解耦设置。同时结合流式计算框架的运行,保障系统并行计算性能拓展问题的有效处理。在具体基于流处理的用量实时计算系统设置过程中,主要包括数据收集、数据处理、数据存储、数据处理等几个模块。首先在数据收集模块设置环节,主要采用Flume 集群,结合海量日志采集、传输、集成等功能的处理,可从exec 、text 等多数据源进行数据收集。Flume 集群的处理核心为代理,即在完整数据收集中心的基础上,通过核心事件集合,分别采用话 单文件代理、计费消息代理等模式,对文件、消息进行收集处理。需要注意的是,在消息接收之后,需要将不同代理数据进行统一数据格式的处理,从而保证整体消息系统的核心统一。其次在实际应用过程中,以流处理为基础的大数据实时计算模型在数据接入环节,主要采用Kafka 集群,其在实际运行中具有较为优良的吞吐量。而且分布式订阅消息发布的新模式,也可以在较为活跃的流式数据处理中发挥优良的效用。在以流处理为基础的用量实时计算系统运行过程中,Kafka 集群主要针对O (1)磁盘数据,其主要通过对TB 级别的消息进行储存处理,并维持相应数据在对应磁盘数据结构中的平稳运行。同时在实际运行中,Kafka 集群还可以依据消息储存日期进行消息类别划分,如通过对消息生产者、消息消费者等相应类别的划分,可为元数据信息处理效率的提升提供依据。 数据处理框架主要采用Storm 集群,其主要具有容错率高、开源免费、分布式等优良特点。在基于Storm 集群的数据处理框架计算过程中,可通过实时计算图状结构的设计,进行拓扑集群提交。同时通过集群中主控节点分发代码设置,实现数据实时过滤处理。在实际运行过程中,基于Storm 集群的数据处理框架,具有Spout 、Bolt 两种形式。前者为数据信息发送,而后者为数据流转换。通过模块间数据传输,Storm 集群也可以进行流量区域分析、自动化阈值检查、流量区域分析等模块的集中处理。数据储存模块主要采用Redis 集群,其在实际处理过程中,主要采用开源式的内部储存结构,通过高速缓存消息队列的设置,可为多种数据类型处理提供依据,如有效集合、列表、字符串、散列表等。2.2 算例分析 在实际应用过程中,基于流处理的大数据实时计算模型需要对多种维度因素进行综合分析,如运营商区域组成维度、时间段储存方案、APN 、资费组处理等。以某个SIM 卡数据处理为例,若其ID 为12345678,则在实际处理中主要包括APN1、APN2两个APN 。若其为联通域内的SIM 卡,则其运营商代码为86。这种情况下就可以对其进行高峰时段及非高峰时段进行合理处理,分为为0、1。而资费组就需要进行All 默认程度的处理,若当前流量话费总体使用量为1.6KB ,则APN1、APN2分别使用流量为1.1/0.4KB 。而在高峰时段、非高峰时段流量损耗为1.1/0.5KB 。这种情况下,就需要对整体区域维度及储存变动情况进行合理评估。在这一环节储存变动主要为Storm 集群,即为消息系统-流量区域分析-流量区域累积-自动化规则阈值检测/区域组合统计-缓存系统。 3 结束语 综上所述,从长期而言,基于Spark 的大数据混合计算模式具有良好的应用优势,其可以通过批处理、流计算、机器学习、图分析等模式的综合应用,满足物联网管理中的多个场景需要。而相较于以往物联网平台而已,基于流处理的大数据实时处理系统具有更为优良的数据压力处理性能。通过多种集群的整合,基于流处理的大数据实时处理系统在我国物联网平台将具有更加广阔的应用前景。 参考文献 [1]欧阳晨.海关应用大数据的实践与思考 [J].海关与经贸研究,2016,37(03):33-43. [2]余焯伟.物联网与大数据的新思考[J]. 通讯世界,2017(01):1-2. [3]孙学义.物联网与大数据的新思考[J]. 科研,2017(03):00200-00200. 作者简介 吴海建(1980-),男,浙江省衢州市人。硕士研究生,中级工程师。研究方向为人工智能。 作者单位 1.中电海康集团有限公司 浙江省杭州市 310012 2.中国电子科技集团第五十二研究所 浙江省杭州市 310012
52 高 师 理 科 学 刊 第32卷 参考文献: [1] 李椿.热学[M].北京:高等教育出版社,1978 [2] 北京大学物理系普通物理研究室.普通物理[M].北京:人民教育出版社,1961 [3] 熊咏涛.热力学[M].北京:人民教育出版社,1983 [4] 顾建中.热学教程[M].北京:人民教育出版社,1982 [5] 尹钊.热学选论[M].徐州:中国矿业大学出版社,2001 对科研团队建设的思考 韦寿莲,刘玲,刘艳清,汪洪武,刘永 科学研究是学科建设的先导.科研团队是以科学技术研究与开发为内容,以科研创新为目的,由为数不多的专业技能互补的科研人员组成的创新群体[1].学科建设与科研团队的关系密不可分,相辅相承.学科建设为科研团队建设提供煅炼的机遇和平台,科研团队为学科建设的发展提供保障[2].因此,要促进学科可持续发展,就要建设好科研团队.本文从项目攻关、青年学术带头人培养、科研创新平台建设、加强学术交流4方面来探索科研团队建设的对策. 1 以项目攻关为载体,促进科研团队的成长 肇庆学院受地域性及以教学为主的导向性影响,科研硬件和人才队伍相对薄弱,导致国家级、省级重点科研项目匮乏.为改变这一现状,近2年来,学校引导科研团队根据广东省“十二五”规划及广东省科技计划项目申报指南转变理念,以服务地方经济指导科学研究,重视产学研结合创新,促进了团队创新水平的提高,也积累了一些项目攻关的经验,高层次项目立项数不断增加.事实上,从项目选题到申请立项,开展科学研究、撰写论文、结题等,项目攻关的每一个过程都是对团队的考验,对团队成员的煅炼.由此可见,项目攻关、建设是提高团队科研创造力和凝聚力、促进团队成长的优良载体. 2 加强青年学术带头人培养 青年学术带头人是科研创新的主力军,但缺乏影响力和战略思维能力.以其为核心组建团队,往往缺乏团队目标和规划,不利于团队、学科建设的发展.因此,必须大力加强优秀青年学术带头人培养.对其培养可以通过内部培养和送出去深造2个途径进行.内部培养主要以学科带头人带领学术带头人,通过传、帮、带,提高其影响力和战略思维能力.深造主要是把青年科研骨干送到国内外一流大学攻读博士学位或进行高级访学,进一步提高其学术成就.此外,还可以通过争取学校经费支持,让学术带头人不断参加国内外学术交流以提高其国内外影响力. 3 营造浓厚的科研氛围,搭建科研创新平台 近年来,随着学校不断扩招,导致具有博士学位的青年教师教学工作量过大,教学负担过重,科研工作投入不足,严重影响其科研创新能力提高.缺乏浓厚的科研氛围,很难取得好的科研成果,更谈不上科研团队的建设和发展.因此,要适当引进一些教学能力强、有科研创新潜力的博士或教授,减轻本校青年博士教授的教学压力,营造浓厚的科研氛围.此外,要大力搭建科研创新平台,因为这是开展科学研究的基地,是科研团队的舞台,是学科建设发展的重要依托[3-4].只有建设好科研平台,才有可能形成开创性的研究工作,提高学科的整体研究水平. 4 加强学术交流 学术交流有交流信息、开阔视野、掌握新知的作用.在学术交流中,思想的碰撞、科学要素之间的相互作用、不同来源思想的相互作用可以激发出灵感,从而产生更多科学新成果.一个优秀的科研团队要积极融入整个学术界,要学会走出去,引进来[5].学术带头人要建立一套学术交流机制,每年规划并组织团队成员积极主动参加国内外学术交流活动,以保障团队能及时了解整个研究领域的最新进展.同时,团队带头人要为团队营造一个良好的学习、学术交流氛围,布置团队成员学习任务,定期开展学术交流活动.通过与团队内来自不同领域的队友相互学习、交流,促使各类知识交叉融合,形成本团队特有的知识体系,提高团队的科研创新能力. 参考文献: [1] 杨怀霞,刘艳菊,王霞.加强创新团队建设,促进学科健康发展[J].现代企业教育,2001(8):214-215 [2] 马二军.关于构建学术团队与提升科研水平的思考[J].北京印刷学院学报,2008,16(1):30-33 [3] 吴全华.《国家中长期教育改革和发展规划纲要(2010-2020年)》实施中需关注的几个问题[J].教学发展研究,2011(17):63-65 [4] 孙青,徐宏波.把握科研与学科建设的关系加快高校健康发展[J].成都理工大学学报:自然科学版,2003(11):182-183 [5] 李磊,张明光,孟丽华.基于重点建设平台的高校学术团队建设探讨[J].技术与创新管理,2010,31(5):544-548 (作者单位:肇庆学院 化学化工学院,广东 肇庆 526061) 基金项目:广东省高等教育本科教学改革基金资助项目; 肇庆学院本科教学质量与教学改革工程基金资助项目