5.2 判别分析
判别分析的方法有参数方法和非参数方法。参数方法假定每个类的观测来自(多元)正态分布总体,各类的分布的均值(中心)可以不同。非参数方法不要求知道各类所来自总体的分布,它对每一类使用非参数方法估计该类的分布密度,然后据此建立判别规则。
1.DISCRIM过程的语句说明
SAS/STAT的DISCRIM过程可以进行参数判别分析和非参数判别分析,其一般格式如下:
PROC DISCRIM DATA=输入数据集:
CLASS 分类变量:
VAR 判别用自变量集合:
RUN;
其中,PROC DISCRIM语句的选项中"输入数据集"为训练数据的数据集,包括一个分类变量(在CLASS语句中说明)和用来建立判别公式的自变量集合(在VAR 语句中说明)。可以用"TESTDATA=数据集"选项指定一个检验数据集,检验数据集必须包含与训练数据集相同的自变量集合,用训练数据集产生判别规则后将对检验数据集中的每一个观测给出分类值,如果这个检验数据集中有表示真实分类的变量可以在过程中用"TESTCLASS分类变量"语句指定,这样可以检验判别的效果如何。
用"OUTSTAT=数据集"指定输出判别函数的数据集,后面可以再次用DISCRIM过程把这样输出的判别函数作为输入数据集(DATA=)读入并用它来判别检验数据(TESTDATA=)。用"OUT=数据集"指定存放训练样本及后验概率、交叉确认分类的数据集。用"OUTD=数据集"指定存放训练样本及分组的密度估计的数掘集。用"TESTOUT=数据集"指定存放检验数据的后验概率及分类结果的数据集。用"TESTOUTD=数据集"输出检验数据及分组密度估计。
PROC DISCRIM语句还有一些指定判别分析方法的选项。METHOD=NORMAL或NPAR 选择参数方法或非参数方法。用POOL=NO或TEST或YES表示不用合并协方差阵、通过检验决定是否使用合并协方差阵、用合并协方差阵。如果使用非参数方法,需要指定"R=核估计半径"选项来规定核估计方法或者指定"k=最近邻个数"来规定最近邻估计方法。
PROC DISCRIM语句有一些规定显示结果的选项。用LISTERR显示训练样本错判的观测。用CROSLISTERR显示用交叉核实方法对训练样本判别错判的观测。用LIST对每一观测显示结果。用NOCLASSIFY取消对训练样本的分类检验。用CROSSLIST显示对训练样本的交叉核实的判别结果。用CROSSVALIDATE要求进行交叉核实。当有用"TESTDATA="指定的检验数据集时用TESTLIST选项显示检验数据集的检验结果,当有TESTCLASS语句时用TESTLISTERR可以列出检验样本判错
的观测,用POSTERR选项可以打印基于分类结果的分类准则的后验概率错误率估计。用NOPRINT选项可以取消结果的显示。
在DISCRIM过程中还可以使用PRIORS语句指定先验概率qt的取法。"PRIORS EQUAL"指定等先验概率。"PRIORS PROPORTIONAL"指定先验概率与各类个数成正比。"PRIORS概率值表"可以直接指定各组的先验概率值。
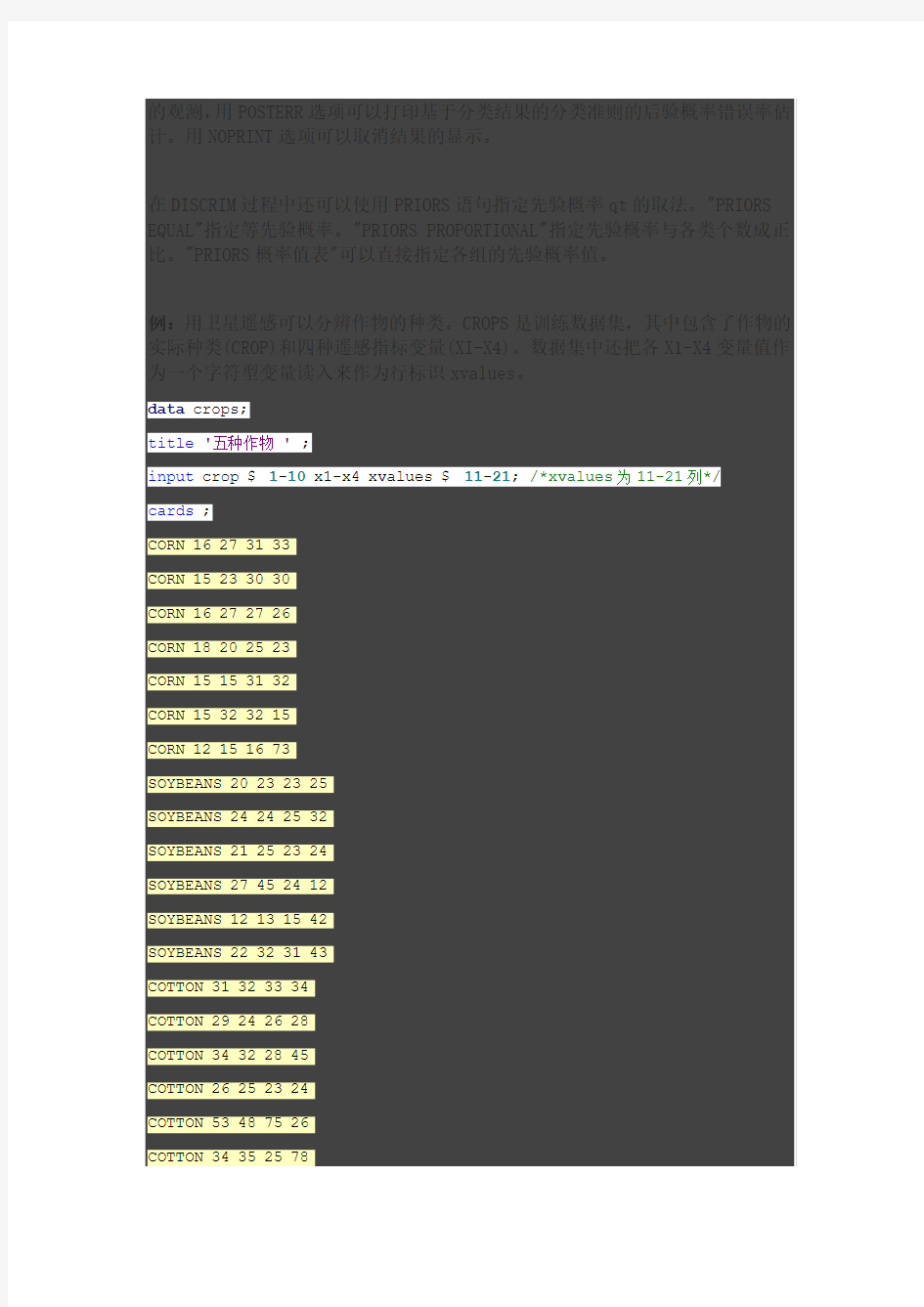
例:用卫星遥感可以分辨作物的种类。CROPS是训练数据集,其中包含了作物的实际种类(CROP)和四种遥感指标变量(XI-X4)。数据集中还把各X1-X4变量值作为一个字符型变量读入来作为行标识xvalues。
data crops;
title'五种作物 ' ;
input crop $ 1-10 x1-x4 xvalues $ 11-21; /*xvalues为11-21列*/
cards ;
CORN 16 27 31 33
CORN 15 23 30 30
CORN 16 27 27 26
CORN 18 20 25 23
CORN 15 15 31 32
CORN 15 32 32 15
CORN 12 15 16 73
SOYBEANS 20 23 23 25
SOYBEANS 24 24 25 32
SOYBEANS 21 25 23 24
SOYBEANS 27 45 24 12
SOYBEANS 12 13 15 42
SOYBEANS 22 32 31 43
COTTON 31 32 33 34
COTTON 29 24 26 28
COTTON 34 32 28 45
COTTON 26 25 23 24
COTTON 53 48 75 26
COTTON 34 35 25 78
SUGARBEETS22 23 25 42
SUGARBEETS25 25 24 26
SUGARBEETS34 25 16 52
SUGARBEETS54 23 21 54
SUGARBEETS25 43 32 15
SUGARBEETS26 54 2 54
CLOVER 12 45 32 54
CLOVER 24 58 25 34
CLOVER 87 54 61 21
;
run;
用下列DISCRIM过程可以产生线性判别函数(METHOD=NORMAL规定使用参数方法,POOL=YES选项规定使用合并协方差阵,这样产生的判别函数是线性函数)。用OUTSTAT=选项指定了判别函数的输出数据集为CROPSTAT,这个数据集可以作为后续的DISCRIM过程输入用来判别检验数据集。选项LIST要求列出每个观测的结果,CROSSVALIDATE要求交叉核实。"PRIORS PROPORTIONAL"即按各种类出现的比例计算各类的先验概率,ID语句指定列出各观测时以什么变量值作为标识。
proc discrim data=crops outstat=cropstat
method=normal pool=yes
list crossvalidate;
class crop;
priors proportional;/*指定先验概率*/
id xvalues;
var x1-x4;
run;
部分结果如下:
以上为各组的基本情况,并列出了各组先验概率值。因为指定了"PRIORS PROPORTIONAL"所以各组的先验概率按实际数据中各组比例计算。
上面具体列出了各类的线性判别函数的各常数项及系数值。比如,观测了X1-X4后棉花类的线性判别函数
-11.46537+0.02462x1+0.017596x2+0.15880x3+0.18362X4。
上面就是每个观测的判别情况,包括原来为哪一类(From CROP),分入了哪一类(Classified into CROP),属于各类的后验概率值(Posterior Probability of Membership in CROP),有星号的为错判的观测。
现在假设我们有若干遥感数据放在了数据集TEST中,实际是己知作物类型的(在变量CROP中),但是我们假装不知道然后用上面建立的线性判别函数(己保存在CROPSTAT数据集中)对这些遥感数据进行判别,这样可以得到比较客观的判别效果的评价。下面程序中用DATA=指定了判别函数数据集(由上一次的DISCRIM 过程产生),用TESTDATA=选项指定了检验数据集名,用TESTOUT=选项指定了检验数据集判别结果的输出数据集,用TESTLIST要求列出检验结果。TESTID语句指定检验数据集的各观测用什么变量的值来标识。
data test;
input crop $ 1-10 x1-x4 xvalues $ 11-21;
cards;
corn 16 27 31 33
soybeans 21 25 23 24
cotton 29 24 26 28
sugarbeets54 23 21 54
clover 32 32 62 16
;
run;
proc discrim data=cropstat
testdata=test testout=tout testlist;
class crop;
testclass crop;
testid xvalues;
var x1-x4;
run;
结果列出了每个观测的判别结果和判入每类的后验概率,因为我们知道真实类,所以结果中有一项是"From CROP",如果不知道真实类则只能给出判入的类(Classified into CROPP)
数据分析 实验指导书 理学院实验中心数学专业实验室编写
实验一SAS系统的使用 【实验类型】(验证性) 【实验学时】2学时 【实验目的】使学生了解SAS系统,熟练掌握SAS数据集的建立及一些必要的SAS语句。 【实验内容】 1. 启动SAS系统,熟悉各个菜单的内容;在编辑窗口、日志窗口、输出窗口之间切换。 2. 建立数据集 表1 Name Sex Math Chinese English Alice f908591 Tom m958784 Jenny f939083 Mike m808580 Fred m848589 Kate f978382 Alex m929091 Cook m757876 Bennie f827984 Hellen f857484 Wincelet f908287 Butt m778179 Geoge m868582 Tod m898484 Chris f898487 Janet f866587 1)通过编辑程序将表1读入数据集sasuser.score; 2)将下面记事本中的数据读入SAS数据集,变量名为code name scale share price: 000096 广聚能源8500 0.059 1000 13.27 000099 中信海直6000 0.028 2000 14.2 000150 ST麦科特12600 -0.003 1500 7.12 000151 中成股份10500 0.026 1300 10.08 000153 新力药业2500 0.056 2000 22.75
3)将下面Excel表格中的数据导入SAS数据集work.gnp; name x1 x2 x3 x4 x5 x6 北京190.33 43.77 7.93 60.54 49.01 90.4 天津135.2 36.4 10.47 44.16 36.49 3.94 河北95.21 22.83 9.3 22.44 22.81 2.8 山西104.78 25.11 6.46 9.89 18.17 3.25 内蒙古128.41 27.63 8.94 12.58 23.99 3.27 辽宁145.68 32.83 17.79 27.29 39.09 3.47 吉林159.37 33.38 18.37 11.81 25.29 5.22 黑龙江116.22 29.57 13.24 13.76 21.75 6.04 上海221.11 38.64 12.53 115.65 50.82 5.89 江苏144.98 29.12 11.67 42.6 27.3 5.74 浙江169.92 32.75 21.72 47.12 34.35 5 安徽153.11 23.09 15.62 23.54 18.18 6.39 福建144.92 21.26 16.96 19.52 21.75 6.73 江西140.54 21.59 17.64 19.19 15.97 4.94 山东115.84 30.76 12.2 33.1 33.77 3.85 河南101.18 23.26 8.46 20.2 20.5 4.3 湖北140.64 28.26 12.35 18.53 20.95 6.23 湖南164.02 24.74 13.63 22.2 18.06 6.04 广东182.55 20.52 18.32 42.4 36.97 11.68 广西139.08 18.47 14.68 13.41 20.66 3.85 四川137.8 20.74 11.07 17.74 16.49 4.39 贵州121.67 21.53 12.58 14.49 12.18 4.57 云南124.27 19.81 8.89 14.22 15.53 3.03 陕西106.02 20.56 10.94 10.11 18 3.29 甘肃95.65 16.82 5.7 6.03 12.36 4.49 青海107.12 16.45 8.98 5.4 8.78 5.93 宁夏113.74 24.11 6.46 9.61 22.92 2.53 新疆123.24 38 13.72 4.64 17.77 5.75 4)使用VIEWTABLE格式新建数据集earn,输入如表所示数据Year earn 1981 125000 1982 136000 1983 122350 1984 65200 1985 844600 1986 255000 1987 265000 1988 280000 1989 136000
《统计软件》报告 聚类分析和方差分析 在统计学成绩分析中的应用 班级:精算0801班 姓名:张倪 学号:2008111500 报告时间:2011年11月 指导老师:郝际贵 成绩:
目录 一、背景及数据来源 (1) 二、描述性统计分析 (2) 三、聚类分析 (4) 四、方差分析 (6) 五、结果分析与结论 (8)
聚类分析和方差分析在统计学成绩分析中的应用 一、背景及数据来源 SAS 系统全称为Statistics Analysis System,最早由北卡罗来纳大学的两位生物统计学研究生编制,并于1976年成立了SAS软件研究所,正式推出了SAS 软件。SAS是用于决策支持的大型集成信息系统,但该软件系统最早的功能限于统计分析,至今,统计分析功能也仍是它的重要组成部分和核心功能。 SAS 系统是一个组合软件系统,它由多个功能模块组合而成,其基本部分是BASE SAS模块。BASE SAS模块是SAS系统的核心,承担着主要的数据管理任务,并管理用户使用环境,进行用户语言的处理,调用其他SAS模块和产品。也就是说,SAS系统的运行,首先必须启动BASE SAS模块,它除了本身所具有数据管理、程序设计及描述统计计算功能以外,还是SAS系统的中央调度室。它除可单独存在外,也可与其他产品或模块共同构成一个完整的系统。各模块的安装及更新都可通过其安装程序非常方便地进行。 本文利用SAS软件进行描述性统计、聚类分析等统计分析方法,将学生按照多指标综合考虑进行聚类。 数据来源:选取2010—2011第一学期统计学选教课成绩单,选取性别系别等变量进行考察。将中文名称改为英文。 数据类型如下所示: 当输入字符型的变量时,需要加上符号$在该变量的后面,用于区分数值型变量,所以用$来作为后缀。删除缺考错误分数等异常值。命名为2010stat.xls
《SAS数据分析范例》数据集 目录 表1 sas.bd1 (3) 表2 sas.bd3 (4) 表3 sas.bd4 (5) 表4 sas.belts (6) 表5 sas.c1d2 (7) 表6 sas.c7d31 (8) 表7 sas.dead0 (9) 表8 sas.dqgy (10) 表9 sas.dqjyjf (11) 表10 sas.dqnlmy3 (12) 表11 sas.dqnlmy (13) 表12 sas.dqrjsr (14) 表13 sas.dqrk (15) 表14 sas.gjxuexiao0 (16) 表15 sas.gnsczzgc (17) 表16 sas.gnsczzs (18) 表17 sas.gr08n01 (19) 表18 sas.iris (20) 表19 sas.jmcxck0 (21) 表20 sas.jmjt052 (22) 表21 sas.jmjt053 (23) 表22 sas.jmjt054 (24) 表23 sas.jmjt055 (25) 表24 sas.jmxfsps (26) 表25 sas.jmxfspzs0 (27) 表26 sas.jmxfzss (28) 表27 sas.jmxfzst (29) 表28 sas.kscj2 (30) 表29 sas.modeclu4 (31) 表30 sas.ms8d1 (32) 表31 sas.nlmyzzs (33) 表32 sas.plates (34) 表33 sas.poverty (35) 表34 sas.rjnycpcl0 (36) 表35 sas.rjsrs (37) 表36 sas.sanmao (38) 表37 sas.sczz1 (39) 表38 sas.sczz06s (40) 表39 sas.sczz (41) 表40 sas.sczzgc1 (42)
实验课程:数据分析 信息与计算科学 业: 专 级: 班 号:学 姓名: 中北大学理学院.
实验一 SAS系统的使用 【实验目的】 了解SAS系统,熟练掌握SAS数据集的建立及一些必要的SAS语句。 【实验内容】 1. 将SCORE数据集的内容复制到一个临时数据集test。 SCORE数据集 English Math Sex Chinese Name 91 90 f 85 Alice 95 Tom m 87 84 93 90 Jenny f 83 80 85 80 Mike m 84 85 89 m Fred 97 83 f 82 Kate 92 Alex 90 m 91 75 Cook m 78 76 82 f Bennie 79 84 85 Hellen f 74 84 90 82 Wincelet f 87 77 Butt m 81 79 86 85 Geoge m 82 89 Tod m 84 84 89 Chris f 84 87 86 65 f 87 Janet math的高低拆分到3个不同的数据集:SCORE2.将数据集中的记录按照math大于等于90的到good数据集,math在80到89之间的到normal数据集,math 在80以下的到bad数据集。 3.将3题中得到的good,normal,bad数据集合并。 【实验所使用的仪器设备与软件平台】SAS 【实验方法与步骤】 1: DATA SCORE; INPUT NAME $ Sex $ Math Chinese English; CARDS; 2
91 85 Alice f 90 84 Tom m 95 87 83 f 93 90 Jenny 80 80 85 Mike m 89 85 m Fred 84 82 83 Kate f 97 91 Alex m 92 90 76 Cook m 78 75 84 82 79 f Bennie 84 74 Hellen f 85 87 82 Wincelet f 90 79 Butt m 77 81 82 m 86 85 Geoge 84 89 84 Tod m 87 84 f Chris 89 87 Janet f 86 65 ; ; Run PROC PRINT DATA=SCORE; DATA test; SET SCORE; :2 good normal bad; DATA SCORE; SET; SELECT) output good; 90when(math>=) output normal; 80when(math>=&math<90) output bad; when(math<80; end; Run=good; DATA PRINT PROC=normal; DATA PRINT PROC=bad; DATA PRINT PROC :3 All; DATA good normal bad; SET=All; DATA PROC PRINT;Run 3 【实验结果】 结果一:
实验一数据的描述性统计分析 一、选择题 1、以下( B )语句对变量进行分组,在使用前需按分组变量进行排序? 以下( C )语句可对变量进行分类,在使用前不必按分类变量进行排序? 用( A )语句可以选择输入数据集的一个行子集来进行分析? (A)WHERE语句(B)BY语句(C)CLASS语句(D)FREQ语句2、排序过程步中必须用什么语句对变量进行排序?( A ) (A)BY语句(B)CLASS语句(C)WHERE语句 3、如果要对数据集中的数据进行正态性检验,需要使用哪个过程?( B )(A)MEANS (B)UNIV ARIATE (C)FREQ 4、用UNIV ARIATE过程进行数据分析,要求此过程输出茎叶图、正态概率图等,应在语句中加上什么选项?(plot ) 5、用UNIV ARIATE过程进行数据分析,在输出结果中哪个统计量是对样本均值 为零的T检验的概率值?( A ) (A)T: Mean (B)Prob>|S| (C)Sgn Rank (D)Prob>|T| 二、假设某校100名女生的血清总蛋白含量(g/L)服从均值为75,标准差为3的正态分布,试产生样本数据,并利用SAS软件解决下面问题: 1、计算样本均值、方差、标准差、极差、四分位极差、变异系数、偏度、峰度; 2、画出直方图(垂直条形图); 3、画出茎叶图、盒形图和正态概率图; 4、试进行正态性检验。 Data N; DO i=1to100; x=75+3*normal(12345); output; end; proc print; run; proc univariate data=N; var x; run; proc gchart data=N; block x; run; proc univariate data=N plot; var x;
实验一分析太阳黑子数序列 一、实验目的:了解时间序列分析的基本步骤,熟悉SAS/ETS软件使用方法。 二、实验内容:分析太阳黑子数序列。 三、实验要求:了解时间序列分析的基本步骤,注意各种语句的输出结果。 四、实验时间:2小时。 五、实验软件:SAS系统。 六、实验步骤 1、开机进入SAS系统。 2、创建名为exp1的SAS数据集,即在窗中输入下列语句: 3、保存此步骤中的程序,供以后分析使用(只需按工具条上的保存按钮然后填写完提问 后就可以把这段程序保存下来即可)。 4、绘数据与时间的关系图,初步识别序列,输入下列程序: ods html; ods listing close; 5、run;提交程序,在graph窗口中观察序列,可以看出此序列是均值平稳序列。
6、识别模型,输入如下程序。 7、提交程序,观察输出结果。初步识别序列为AR(2)模型。 8、估计和诊断。输入如下程序: 9、提交程序,观察输出结果。假设通过了白噪声检验,且模型合理,则进行预测。 10、进行预测,输入如下程序: 11、提交程序,观察输出结果。
12、退出SAS系统,关闭计算机。总程序: data exp1; infile "D:\"; input a1 @@;
year=intnx('year','1jan1742'd,_n_-1); format year year4.; ; proc print;run; ods html; ods listing close; proc gplot data=exp1 ; symbol i=spline v=dot h=1 cv=red ci=green w=1; plot a1*year/autovref lvref=2 cframe=yellow cvref=black ; title "太阳黑子数序列"; run; proc arima data=exp1; identify var=a1 nlag=24 minic p=(0:5) q=(0:5); estimate p=3; forecast lead=6 interval=year id=year out=out; run; proc print data=out; run; 选取拟合模型的规则: 1.模型显著有效(残差检验为白噪声)
一、数据集的建立 1.导入Excel数据表的步骤如下: 1) 在SAS应用工作空间中,选择菜单“文件”→“导入数据”,打开导 入向导“Import Wizard”第一步:选择导入类型(Select import type)。 2) 在第二步的“Select file”对话框中,单击“Browse”按钮,在 “打开”对话框中选择所需要的Excel文件,返回。然后,单击“Option” 按钮,选择所需的工作表。(注意Excel文件要是2003的!!) 3) 在第三步的“Select library and member”对话框中,选择导入数据集所存放的逻辑库以及数据集的名称。 4 ) 在第四步的“Create SAS Statements”对话框中,可以选择将系统生成的程序代码存放的位置,完成导入过程。 2.用INSIGHT创建数据集 1)启动SAS INSIGHT模块,在“SAS INSIGHT:Open”对话框的”逻辑库“列表框中,选定库逻辑名 2)单击“新建”按钮,在行列交汇处的数据区输入数据值 (注意列名型变量和区间型变量,这在后面方差分析相关性分析等都要注意!!) 3)数据集的保存: ?“文件”→“保存”→“数据”; ?选择保存的逻辑库名,并输入数据集名; ?单击“确定”按钮。即可保存新建的数据集。 3.用VIEWTABLE窗口建立数据集 1)打开VIEWTABLE窗口 2)单击表头顶端单元格,输入变量名 3)在变量名下方单元格中输入数据
4)变量类型的定义:右击变量名/column attributes… 4.用编程方法建立数据集 DATA 语句; /*DATA步的开始,给出数据集名*/ Input 语句;/*描述输入的数据,给出变量名及数据类型和格式等*/ (用于DATA步的其它语句) Cards; /*数据行的开始*/ [数据行] ; /*数据块的结束*/ RUN; /*提交并执行*/ 例子:data=数据集名字; input name$ phone room height; ($符号代表该列为列名型,就是这一列是文字!! 比如名字,性别,科目等等) cards; rebeccah 424 112 (中间是数据集,中间每一行末尾不要加逗号,但是carol 450 112 数据集最后要加一个分号!!) louise 409 110 gina 474 110 mimi 410 106 alice 411 106 brenda 414 106 brenda 414 105 david 438 141 betty 464 141 holly 466 140 ; proc print data=; (这一过程步是打印出数据集,可要可不要!) run;
90-08年人民消费能力分析 一、问题提出 改革开放以来中国经济飞速发展,GDP连续超过德国、日本,现以成为世界上第二大经济体,人民生活水平不断提高,但受金融危机的影响,近几年来物价持续上涨,本月CPI创历史新高,人民的消费能力是否随着GDP的增加而增加呢?本文以中国经济年鉴中的“人民消费支出构成”的数据为依据利用统计软件SAS 进行了相关分析。数据如下 食品衣着居住家庭设备用品及服务交通通讯文教娱乐用品及服务医疗保健其他商品及服务 1990 58.8000 7.7700 17.3400 5.2900 1.4400 5.3700 3.2500 0.7400 1995 58.6200 6.8500 13.9100 5.2300 2.5800 7.8100 3.2400 1.7600 2000 49.1300 5.7500 15.4700 4.5200 5.5800 11.1800 5.2400 3.1400 2005 45.4800 5.8100 14.4900 4.3600 9.5900 11.5600 6.5800 2.1300 2007 43.0800 6.0000 17.8000 4.6300 10.1900 9.4800 6.5200 2.3000 2008 43.6700 5.7900 18.5400 4.7500 9.8400 8.5900 6.7200 2.0900 二、问题分析 1、通过对消费种类进行主成分分析判断人民的消费情况。 2、对主成分标准化后在分析各年的消费能力排名。 三、解决问题 3.1 SAS程序: data examp4_4; input id x1-x8; cards; 1990 58.8000 7.7700 17.3400 5.2900 1.4400 5.3700 3.2500 0.7400 1995 58.6200 6.8500 13.9100 5.2300 2.5800 7.8100 3.2400 1.7600 2000 49.1300 5.7500 15.4700 4.5200 5.5800 11.1800 5.2400 3.1400 2005 45.4800 5.8100 14.4900 4.3600 9.5900 11.5600 6.5800 2.1300 2007 43.0800 6.0000 17.8000 4.6300 10.1900 9.4800 6.5200 2.3000 2008 43.6700 5.7900 18.5400 4.7500 9.8400 8.5900 6.7200 2.0900 ; run; proc corr cov nosimple data=examp4_4; var x1-x8; run; proc princomp data=examp4_4 out=bb; var x1-x8; run; data score1; /*以下程序是对各年按第一主成分得分进行排名并打印结果*/ set bb; keep id prin1;
院系:数学与统计学学院 专业:__统计学 年级:2009 级 课程名称:统计分析 ____ 学号:____________ 姓名:_________________ 指导教师:____________ 2012年4月28日 (一)实验名称 1. 编程计算样本协方差矩阵和相关系数矩阵;
2. 多元方差分析MANOVA。 (二)实验目的 1. 学习编制sas程序计算样本协方差矩阵和相关系数矩阵; 2. 对数据进行多元方差分析。 (三)实验数据 第一题: 第二题:
(四)实验内容 1. 打开SAS软件并导入数据; 2. 编制程序计算样本协方差矩阵和相关系数矩阵; 3. 编制sas程序对数据进行多元方差分析; 4. 根据实验结果解决问题,并撰写实验报告; (五)实验体会(结论、评价与建议等) 第一题: 程序如下: proc corr data=sasuser.sha n cov; proc corr data=sasuser.sha n no simple cov; with x3 x4; partial x1 x2; run; 结果如下: (1)协方差矩阵 $AS亲坯 曲;15 Friday, Apr: I SB,沙DO COUR过程 x4 目由度=30 Xi x2x3x4x5X? -10.I9B4944-0.45E2GJ5I.3347097-G.1193E48-£0.e75?GS
-ID. 188494669,36&Q3?9-7.22IO&OS1J5692043I5.49ee^91S.Oa97SM -8.45S2645■7,221050829.S78&S46-6.372E47I-15.3084183-21.7352376-11.5674785 1.3841097 1.G5S2M7t.3726171IJ24?17B 4.e093011 4.4C12473 2.B747CM -G. I1S3S49 1.GS92043-is.soul aa 4.B09B01I68.7978495劣』S670971S.57ai1B3 -IH.05l6l?a15.43S6569-J1.73S2376孔耶124TB27.0387097105.103225&S7.3505S7E: -2D K5752??319-11337204-1L55M7S52r9747?3i19,573118337.3S0&87E33.3SQ6452 (2) 相关系数矩阵 Pearson相关系数” N =引 当HO: Rho=0 时.Prob > |r| Xi Xi xl 1.QQ000 x2 -C.23954 0.2061 x3 -0,30459 0.0957 x4 0.18975 Q.3092 x5 '0.14157 0.4475 x6 -0.83787 0.0630 -0.49292 0.0150 x2-0.23354 1.00000-0.162750.143510.022700.181520.24438 x20.20C10.31:1?0.441?0.90350.32640.1761 x3-0.30459-0.16275 1.00000-0.06219-0.34641-0.^797-0.23674 x30.095?0.381?<.00010.0563o.oses0 JS97 x40.1S8760.14351-0.86219L000000.400540,313650.22610 x40.30920.4412<.0001 D.02EG Q.085S0.2213 x5-0J 41570.02270-0.946410.40054 1.000000.317370.26750 x50.4J750.90350.0G68Q.025&0.08130 + 1620 x6-0.33?e?0.1S162-0.397970.813650.31787LOOOOO0.82976 x60.0S300.32840.02660.08580.0813C0001辺-0.432920.24938-0.288740.22810 D.267600.92976 1.00000 x70,01500J7610.19970.22130JG20<.0001 第二题: 程序如下: proc anova data=sasuser.hua ng; class kind; model x1-x4=k ind; manova h=k ind; run; 结果如下: (1)分组水平信息 The ANNA Procedure Cla^s Level Informat ion Class Level?Values kind 3 123 Number of observatIons CO (2) x1、x2、x3、x4的方差分析
SAS系统简介 一、SAS系统 1.SAS系统的功能 SAS系统是大型集成应用软件系统,具有完备的以下四大功能: ●数据访问 ●数据管理 ●数据分析 ●数据呈现 它是美国软件研究所(SAS Institute Inc.)经多年的研制于1976年推出。目前已被许多国家和地区的机构所采用。SAS系统广泛应用于金融、医疗卫生、生产、运输、通信、政府、科研和教育等领域。它运用统计分析、时间序列分析、运筹决策等科学方法进行质量管理、财务管理、生产优化、风险管理、市场调查和预测等等业务,并可将各种数据以灵活多样的各种报表、图形和三维透视的形式直观地表现出来。在数据处理和统计分析领域,SAS系统一直被誉为国际上的标准软件系统。 2.SAS系统的支持技术 在当今的信息时代中,如何有效地利用业务高度自动化所产生的巨量宝贵数据,挖掘出对预测和决策有用的信息,就成为掌握竞争主导权的关键因素。因此,SAS系统始终致力于应用先进的信息技术和计算机技术对业务和历史数据进行更深层次的加工。经过二十多年的发展,SAS系统现在是以下三种技术的主要提供者: ●数据仓库技术(Data Warehouse) 数据仓库是用于支持管理决策过程的面向主题的、集成的、随时间而变化的、持久的(非易失的)数据集合。通俗地说,可以将数据仓库理解为“将多个生产数据源中的数据按一定规则统一集中起来,并提供灵活的观察分析数据手段,从而为企业制定决策提供事实数据的支持”。 数据仓库最大的用途是能够提供给用户一种全新的方式从宏观或微观的角度来观察多年积累的数据,从而使用户可以迅速地掌握自己企业的经营运转状况、运营成本、利润分布、市场占有率、发展趋势等对企业发展和决策有重要意义的信息,使用户能制定更加准确科学的决策迅速对市场做出反应。利用数据仓库技术可以使大企业运作的像小企业一样灵活,也可以使小企业像大企业一样规范。从目前情况来看,许多企业和机构已经建立了相对完善的生产数据库系统。随着时间的推移,这些系统中积累了大量的历史数据,其中蕴含了许多重要的信息。利用数据仓库技术对这些历史数据进行分析和综合处理,可以找到那些对企业发展至关重要的业务信息,从而帮助有关主管和业务部门做出更加合理的决策。 当今世界充满了剧烈竞争,正确及时的决策是企业生存和发展的最重要环节。现在,愈来愈多的企业认识到,企业要想在竞争中取胜,获得更大的收益,至关重要的是,必须利用计算机和网络技术、数据仓
第二十二课三维图形 SAS系统除了可以绘制二维平面图形外,还可以绘制三维立体图形。使用PROC G3D过程能对在PLOT或SCATTER语句中指定的变量值绘制三维图形。PROC G3D过程产生的三维图形分为两种:三维曲面图和三维散布图。三维曲面图是通过在PLOT语句中指定三个图形变量来产生,三维散布图是在SCATTER语句中必需指定三个图形变量才能产生,同样还可以对三维散布图进行大小、形状、颜色的修改。 一、PROC G3D过程说明 PROC G3D过程产生三维高分辨率立体图形,一般由下列语句控制: Proc G3D DATA=数据集; PLOT Y*X=Z ; SCATTER Y*X=Z ; TITLE n‘字符串’; FOOTNOTE n‘字符串’; By 变量列表; Run ; 在PROC G3D过程中至少要有一条PLOT或SCATTER语句,如果两条语句同时存在,将在一页中产生一个三维曲面图,下一页中产生一个三维散布图。语句中的Y*X=Z指定三个图形变量X、Y、Z,三维空间中的图形点由三个变量的值共同决定,X和Y为水平变量,Z 为垂直变量。PLOT语句是将X、Y、Z三个变量值确定的空间图形点相互连成曲面,而SCA TTER语句是将X、Y、Z三个变量值确定的空间图形点用符号表示或画出图形点向XY 平面的垂直线(采用NEEDLE选项)。一个PROC G3D过程中可以有多条SCA TTER语句。 1.PLOT语句的选项 用在PLOT语句中的选项按功能可以分为三类:外观选项、轴选项和描述性选项。主要选项如下: ●ROTATE=角度列表——指定三维图形Z轴的一个或多个旋转角度,缺省值为70 度。如果有多个旋转角度,将画出对应多个不同旋转角度的三维图形。 ●TILT=角度列表——指定三维图形Y轴的一个或多个倾斜角度,缺省值为70度。 如果有多个倾斜角度,将画出对应多个不同倾斜角度的三维图形。 ●GRID——在所有坐标轴的每一个刻度线上画出网格线。 ●SIDE——在三维曲面图形中画出侧面墙。 ●XTICKNUM=n YTICKNUM=n ZTICKNUM=n——指定X、Y、Z坐标轴上的刻 度线数目n,缺省值为4。
抑郁自评量表(SDS)实验报告 一、实验目的 通过实验了解受试抑郁的主观感受、轻重程度及其在治疗中的变化,掌握个别施测的使用方法。掌握抑郁自评量表的原理、实施、记分与结果解释方法。 二、实验材料 大学生心理测验系统 三、实验步骤 3.1 进入大学生心理测验系统后再点击进入人格特点测评项目。 3.2 点击测试项目名称即抑郁自评量表(SDS),进入抑郁自评量表界面。 3.3 输入被试信息,确定后桌面弹出测验指导与窗口,认真阅读指导语: ①在这个问卷测试当中有20个问题,请你依次回答这些问题,答案选项包括“没有或很少时间”、“少部分时间”、“相当多时间”和“绝大部分或全部时间”四个选项,每一测题只能选择一个答案; ②该问卷测试评定的是最近一周的实际感觉; ③本测验不计时间,但应凭自己的直觉反应进行作答,不要迟疑不决,拖延时间; ④有些题目你可能从未思考过,或者感到不太容易回答。对于这样的题目,同样要求你做出一种倾向性的选择。 确定阅读完毕后开始测试。 3.4 按照出现题目的先后顺序作答,直至答题完毕。 四、实验结果 4.1 受试信息 姓名:XXX性别:女年龄: 2 0 文化程度:本科测验耗时:00:00:43 4.2 受试结果 总粗分65 标准总分81.25 参考诊断:有(重度)抑郁症状 重点提示: 抑郁精神性,因子得分:6 抑郁躯体障碍,因子得分:27 抑郁精神运动性障碍,因子得分:6 抑郁心理障碍,因子得分:26 五、实验结果分析 该测试结果提示受试有重度抑郁的倾向,主要表现为: 情绪非常低落,感觉毫无生气,没有愉快的感觉,经常产生无助感或者绝望感,自怨自责。经常有活着太累,想解脱、出现消极的念头,还常哭泣或者整日愁眉苦脸,话语明显少,活动也少,兴趣缺乏,睡眠障碍明显,入睡困难或者早醒,性欲功能基本没有。 六、讨论或思考
对定量结果进行差异性分析 1.单因素设计一元定量资料差异性分析 1.1.单因素设计一元定量资料t检验与符号秩和检验 T检验前提条件:定量资料满足独立性和正态分布,若不满足则进行单因素设计一元定量资料符号秩和检验。 1.2.配对设计一元定量资料t检验与符号秩和检验 配对设计:整个资料涉及一个试验因素的两个水平,并且在这两个水平作用下获得的相同指标是成对出现的,每一对中的两个数据来自于同一个个体或条件相近的两个个体。 1.3.成组设计一元定量资料t检验 成组设计定义: 设试验因素A有A1,A2个水平,将全部n(n最好是偶数)个受试对象随机地均分成2组,分别接受A1,A2,2种处理。再设每种处理下观测的定量指标数为k,当k=1时,属于一元分析的问题;当k≥2时,属于多元分析的问题。 在成组设计中,因2组受试对象之间未按重要的非处理因素进行两两配对,无法消除个体差异对观测结果的影响,因此,其试验效率低于配对设计。 T检验分析前提条件:
独立性、正态性和方差齐性。 1.4.成组设计一元定量资料Wil coxon秩和检验 不符合参数检验的前提条件,故选用非参数检验法,即秩和检验。1.5.单因素k(k>=3)水平设计定量资料一元方差分析 方差分析是用来研究一个控制变量的不同水平是否对观测变量产生了显著影响。这里,由于仅研究单个因素对观测变量的影响,因此称为单因素方差分析。 方差分析的假定条件为: (1)各处理条件下的样本是随机的。 (2)各处理条件下的样本是相互独立的,否则可能出现无法解析的输出结果。 (3)各处理条件下的样本分别来自正态分布总体,否则使用非参数分析。(4)各处理条件下的样本方差相同,即具有齐效性。 1.6.单因素k(k>=3)水平设计定量资料一元协方差分析 协方差分析(Analysis of Covariance)是将回归分析与方差分析结合起来使用的一种分析方法。在这种分析中,先将定量的影响因素(即难以控制的因素)看作自变量,或称为协变量(Covariate),建立因变量随自变量变化的回归方程,这样就可以利用回归方程把因变量的变化中受不易控制的定量因素的影响扣除掉,从而,能够较合理地比较定性的影响因素处在不同水平下,经过回归分析手段修正以后的因变量的样本均数之间的差别是否有统计学意义,这就是协方差分析解决问题的基本计算原理。
第十六课用在PROC步中的通用语句 当我们用DATA步创建好SAS数据集后,可以用SAS的一些PROC过程步来进一步的分析和处理它们。在DATA步中用户可以使用SAS的语句来编写自己的程序,以便能通过读入、处理和描述数据,创建符合自己特殊要求的SAS数据集。而后由一组组PROC步组成的程序进行后续分析和处理。 一、PROC程序的主要作用 ●读出已创建好的SAS数据集 ●用数据集中的数据计算统计量 ●将统计的结果按一定形式输出 在SAS系统中,计算统计量时,对于许多常用的和标准的统计计算方法,并不需要用户自己编写这些复杂的程序,而是通过过程的名字来调用一个已经为用户编写好的程序。用户通常只要编写调用统计过程前的准备处理程序和输出统计结果后的分析和管理程序。只有用户自己非常特殊的统计计算方法才需要用户自己编写相应的计算程序。 二、PROC过程语句 PROC语句用在PROC步的开始,并通过过程名来规定我们所要使用的SAS过程,对于更进一步的分析,用户还可以在PROC语句中使用一些任选项,或者附加其他语句及它们的任选项(如BY语句)来对PROC步规定用户所需要分析的更多细节。PROC语句的格式为: PROC 过程名<选项>; 过程名规定用户想使用的SAS过程的名字。例如,我们在前面常使用的打印过程名PRINT,对数值变量计算简单描述统计量的过程名MEANS。 选项规定这个过程的一个或几个选项。不同的过程规定的选项是不同的,因此,只有知道具体的过程才能确定具体的选项是什么。但是,在各个不同过程中使用选项时,下面三种选项的使用格式是共同的: ●Keyword ●Keyword=数值 ●Keyword=数据集 Keyword是关键字,第一种选项格式是某个具体过程进一步要求某个关键字;第二种选项格式是某个具体过程要求某个关键字的值,值可能是数值或字符串;第三种选项格式是某个具体过程要求输入或输出数据集。例如: PROC Print Data=class ; 过程Print,作用为打印输出数据集中的数据。选项为Data=class,关键字是Data,进一步说明要打印输出的数据集名为class。如果省略这个选项,将用最近产生的SAS数据集。
第四课SAS数据库 一、SAS数据库(SAS data library)的成员 一个目录里的所有SAS文件都是一个SAS数据库(SAS data library)的成员。一个目录可以包含外部文件(非SAS文件)以及SAS文件,但只有这些SAS文件才是SAS数据库的成员。 SAS数据库是一个逻辑概念,没有物理实体。图4.1描述了SAS数据库、SAS文件和SAS 文件的元素之间的关系。注意,这个库对应于主机操作系统的一个目录,而SAS文件对应于目录内的一个文件。 图4.1 在SAS数据库中的成员类型 例如,我们前面定义的Study永久库就是一个SAS数据库,对应的目录为d:\sasdata\mydir,在此目录内有SAS数据集文件: ●Class.sd2(包含两种成员类型DATA和VIEW) ●索引文件Class.si2 其他SAS文件如用BASE SAS软件的存储程序功能产生的成员类型为: ●PROGRAM程序文件 SAS的目录是具有成员类型为: ●CATALOG的SAS文件 此文件用来存储许多称为目录条目(catalog entries)的不同类型的信息,用于SAS系统识别它的结构。典型地,像BASE SAS软件,如果存储目录条目信息对于处理是必要的话,就自动地存储SAS目录条目,而在其他SAS软件中,用户必须在各个过程中规定这个目录条目,用下面完整的四级名字形式来识别:libref.catalog.entry-name.entry-type(库标记.目录名.条目名.条目类型)。SAS系统有一些特性帮助你管理目录中的条目,一是CATALOG过程,它是BASE SAS软件中的一个过程;另一个是显示管理的CATALOG窗口。 SAS访问描述器是一个允许用户创建SAS/ACCESS视图的工具,访问描述器的成员类型为: ●ACCESS的一些文件 我们可以用SAS/ACCESS软件里的ACCESS过程创建它们。访问描述器描述存储在SAS 系统外部的数据,如一些公开的数据库管理系统(DBMS)中的数据,每个访问描述器保存我们想要访问的有关DBMS文件的必要信息,如它的名字、列名和列类型等。
第十三课PROC TRANSPOSE转置数据 集 一、转置数据集的概念 在对数据库的操作中,有时需要把数据库的行和列进行交换,也可称转置。SAS系统中TRANSPOSE过程能完成对SAS数据集的转置,即把观测(行)变为变量(列),变量变为观测。该过程从读入的一个数据集中创建一个新的数据集。新数据集中包含三类变量: ●一是由输入数据集中的观测转置后创建的新变量,又称转置变量,如_NAME_、 COL1、COL2、COL3…… ●二是从输入数据集中拷贝过来的变量,使用COPY语句定义这个变量,新数据集 中COPY过来的变量与输入数据集中的变量具有相同的名字和值 ●三是为了识别新数据集中每条观测的来源用ID语句定义的变量值作为新数据集创 建的新变量 二、使用PROC TRANSPOSE过程转置数据集 1.用于TRANSPOSE过程的常用语句 Proc Transpose
图13.1 由CLASS转置生成的新数据集NEWCLASS 3.设定新数据集中的转置变量名 新数据集中的转置变量名是可以由用户自己设定的。 ●通过PROC TRANSPOSE语句的选项NAME=COURSE,修改了省缺的新变量名 _NAME_为COURSE ●还可以通过选项PREFIX=NO,修改了省缺的新变量名COL1、COL2、COL3、 COL4、COL5为NO1、NO2、NO3、NO4、NO5 ●如果新变量名COL1、COL2、COL3、COL4、COL5想用输入数据集CLASS中 NAME变量中的对应值来替代,使用ID命令定义NAME即可。这样命名新变量的优点是通过新变量名就可以很容易地识别原数据集中的观察行 修改程序如下: Proc Transpose Data=CLASS Out=NEWCLASS Name=COURSE ; Var TEST1 TEST2 TEST3 ; Id Name ; Run ; 转置生成的新数据集NEWCLASS的结果如图13.2所示。
实验报告 实验项目名称典型相关分析 所属课程名称统计分析及SAS实现实验类型验证性实验 实验日期2016-12-11 班级数学与应用数学 学号 姓名 成绩
【实验方案设计】 一.理解典型相关分析的概念及步骤; 二.掌握典型相关分析的方法; 三.用INSIGHT、“分析家”计算统计量和编程实现实际问题中的典型相关分析; 【实验过程】(实验步骤、记录、数据、分析) 【练习7-1】对某高中一年级男生38人进行体力测试及运动能力测试,如表所示,试对两组指标作典型相关分析。
34 47 55 113 40 71.4 19 64 7.6 410 29 7 331 35 49 74 120 53 54.5 22 59 6.9 500 33 21 342 36 44 52 110 37 54.9 14 57 7.5 400 29 2 421 37 52 66 130 47 45.9 14 45 6.8 505 28 11 355 38 48 68 100 45 53.6 23 70 7.2 522 28 9 352 其中,体力测试指标为:X 1-------反复横向跳(次),X 2 -------纵跳(cm), X 3------背力(kg),X4------捏力(kg),X 5 -----台阶测试(指数),X 6 ------ 定向体前屈(cm),X 7 -------俯卧上提后仰(cm)。 运动能力测试的指标为y 1-50m跑(s),y 2 -跳远(cm),y 3 -投球(m),y 4 引体 向上(次),y 5 -耐力跑(s)。 【解答】 利用INSIGHT模块进行典型相关分析: 结果: 表7.1 Univariate Statistics Variable N Mean Std Dev Minimum Maximum y1 38 7.1316 0.3354 6.6000 8.0000 y2 38 441.8421 43.2138 362.0000 522.0000 y3 38 27.8158 2.7495 21.0000 33.0000 y4 38 7.5263 3.8326 2.0000 21.0000