
2010年9月第29卷第3期
内蒙古科技大学学报
Jou rnal of Inner M ongo lia U n i v ers it y o f Science and T echno l ogy
September,2010
V o.l29,N o.3
文章编号:1004-9762(2010)03-0254-04
基于随机数传送的动态帧时隙A l oha算法的研究*
李宝山,罗春青
(内蒙古科技大学信息工程学院,内蒙古包头014010)
关键词:随机数;时隙;A l oha;吞吐率
中图分类号:TP301.6文献标识码:A
摘要:在动态帧时隙A l oha算法的基础上提出了基于随机数传送的动态帧时隙A l oha算法,算法通过增加一个与时隙随机数无关的随机数、双随机数共同定位标签的方法来减少碰掸,获得更高的识别效率.仿真结果显示此算法性能比动态帧时隙A l oha算法和基于分组的动态A l oha算法有明显改善.
Research of dyna m ic fra m ed slotte d Aloha
al gorit h m based on transferring rando m nu mber
LI B ao-shan,LUO Chun-q i n g
(Informa ti on Eng i neer i ng Schoo,l InnerM ongo li a U n i versity of Sc i ence and T echno logy,B ao tou014010,China)
K ey word s:rando m nu m ber;slot;A loha;throughput ra te
Abstrac t:The dyna m i c fra m ed slotted A l oha algorith m based on transferri ng random nu m ber was brought for w ard on the basi s o f dyna m-ic framed slotted A l oha algorith m.A random nu mber was added to tag unre l a ted to t he sl o t random nu m ber,w it h t wo rando m nu mbers positi on i ng the tag tog et her i n o rder t o decrease co lli s i on count and ga i n h i gher e fficiency o f recognition.S i m u lati on resu lts sho w that the proposed algor it h m is m ore effec tive than the dyna m ic fra m ed slotted A l oha a l go rith m and the a l go rith m based on g rouped dy m a m ic fra m ed sl o tted A loha.
无线射频识别(RFI D)是一种非接触式的自动识别技术,其基本原理是利用射频信号和空间耦合(电感或电磁耦合)的传输特性,实现对特定物体的自动识别[1].RFI D系统主要由读写器和标签两部分组成.当在读写器的天线作用范围内有多个电子标签时,面对读写器发出的指令,每个电子标签都会响应,如果它们同时发送信号,信号互相干扰,就会产生信道冲突,即出现了数据碰撞,针对这一问题需要利用防碰撞算法[2].
目前,主要的防碰撞算法有两类:A loha算法和二进制树搜索算法.A l o ha算法是一种基于概率的算法,它的防碰撞原理为标签进入读写器的作用范围就向读写器发送其自身的信息,如果没有冲突则直接读取标签信息,如果有冲突(部分冲突或完全冲突),读卡器发送命令让标签停止发送,标签则延迟一段随机时间后再发送,它的吞吐率为18.4%.为了防止部分冲突的出现,后来有人提出了时隙A l o ha 算法,它要求每个标签都有用于多标签同步的数字时钟,其吞吐率提高到36.8%.二进制搜索算法是利用逐步细化分组的方式来减少碰撞标签数,当遇到有冲突发生就进行分枝,生成两个子集,这些分枝越来越细,直到最后分枝下面只有一个标签或无剩余标签[3].
1动态帧时隙A l oha算法和基于分组的动态帧时隙A l oha算法
动态帧时隙A loha算法,简称DFSA算法,它的帧
*收稿日期:2010-05-04
作者简介:李宝山(1965-),男,河北唐山人,内蒙古科技大学教授.
李宝山等:基于随机数传送的动态帧时隙A loha 算法的研究
是由多个时隙组成的,但每一帧的时隙数是变化的,通过上一帧识别的情况估计出未读的标签数,从而确定下一帧所需的时隙数,帧的时隙数通常为4,8,16,
32,64,128,256[4]
,在实际标签数小于帧时隙数时会出现很多空时隙,而在标签数远远大于帧时隙时则会出现大量的碰撞,标签数在大于256时,随着标签数的增加,识读出所有标签所需要的总时隙数呈指数增
长,它的识别性能下降非常快.因此,后来有人提出了基于分组的动态帧时隙A loha 算法,简称EDFSA 算法[5]
,此算法就是针对DFSA 算法处理较多标签数量性能急剧下降提出来的改进算法,算法中规定标签小于355时分成1组,355~622时分成2组,623~883时分成3组,884~1141时分成4组,随时标签数的增加分成更多组,但组数不能超过8组
[6]
.
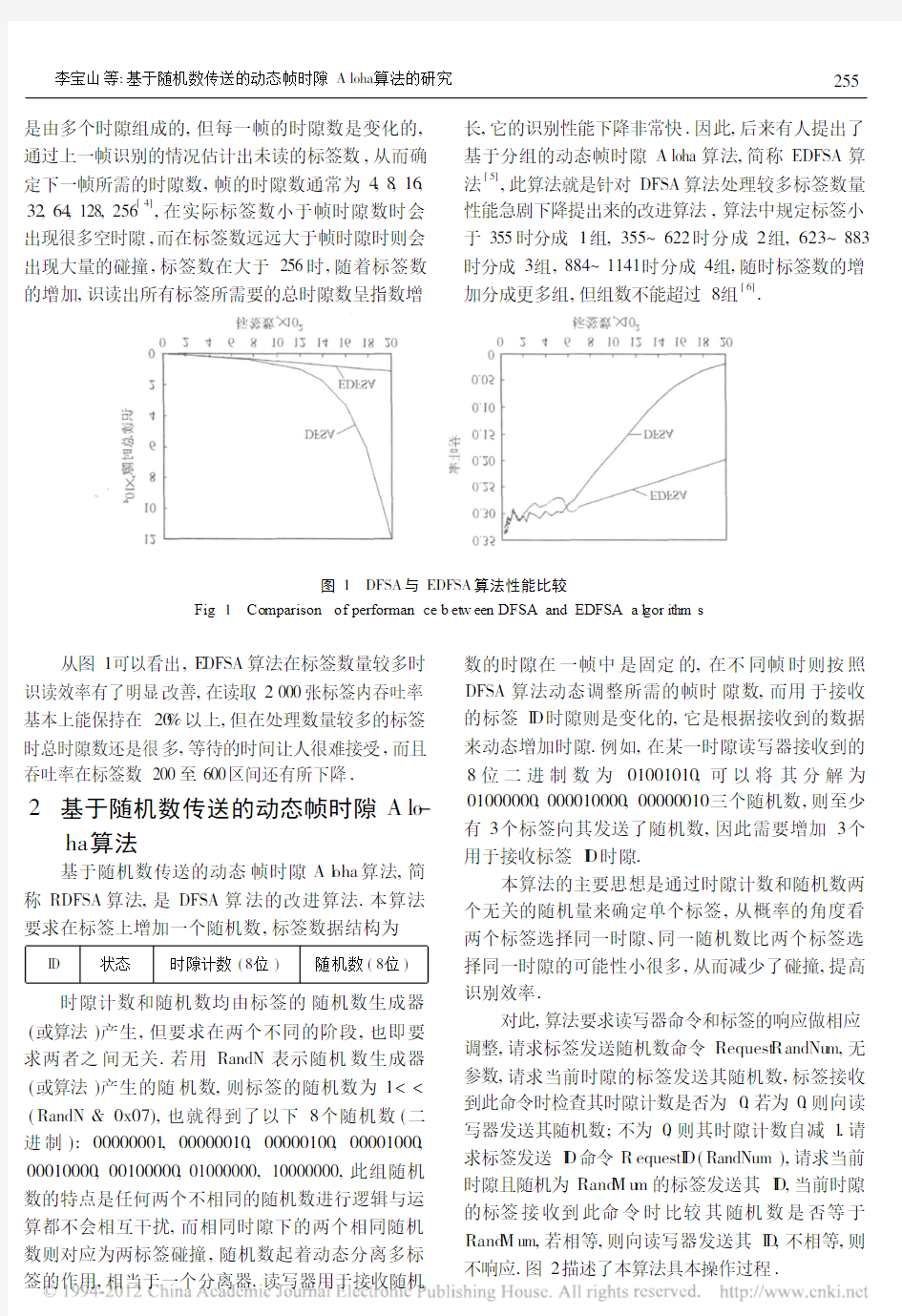
图1 DFSA 与EDFSA 算法性能比较
Fig .1 Co mparison of performan ce b et w een DFSA and EDFSA a l gor ithm s
从图1可以看出,E DFSA 算法在标签数量较多时识读效率有了明显改善,在读取2000张标签内吞吐率基本上能保持在20%以上,但在处理数量较多的标签时总时隙数还是很多,等待的时间让人很难接受,而且吞吐率在标签数200至600区间还有所下降.
2 基于随机数传送的动态帧时隙A lo -ha 算法
基于随机数传送的动态帧时隙A l o ha 算法,简称RDFSA 算法,是DFSA 算法的改进算法.本算法要求在标签上增加一个随机数,标签数据结构为
ID
状态
时隙计数(8位)
随机数(8位)
时隙计数和随机数均由标签的随机数生成器(或算法)产生,但要求在两个不同的阶段,也即要求两者之间无关.若用RandN 表示随机数生成器(或算法)产生的随机数,则标签的随机数为1<<(RandN &0x07),也就得到了以下8个随机数(二进制):00000001,00000010,00000100,00001000,00010000,00100000,01000000,10000000,此组随机数的特点是任何两个不相同的随机数进行逻辑与运算都不会相互干扰,而相同时隙下的两个相同随机数则对应为两标签碰撞,随机数起着动态分离多标
签的作用,相当于一个分离器.读写器用于接收随机
数的时隙在一帧中是固定的,在不同帧时则按照DFSA 算法动态调整所需的帧时隙数,而用于接收的标签I D 时隙则是变化的,它是根据接收到的数据来动态增加时隙.例如,在某一时隙读写器接收到的8位二进制数为01001010,可以将其分解为01000000,000010000,00000010三个随机数,则至少有3个标签向其发送了随机数,因此需要增加3个用于接收标签I D 时隙.
本算法的主要思想是通过时隙计数和随机数两个无关的随机量来确定单个标签,从概率的角度看两个标签选择同一时隙、同一随机数比两个标签选择同一时隙的可能性小很多,从而减少了碰撞,提高识别效率.
对此,算法要求读写器命令和标签的响应做相应调整,请求标签发送随机数命令Request R andNu m,无参数,请求当前时隙的标签发送其随机数,标签接收到此命令时检查其时隙计数是否为0,若为0,则向读写器发送其随机数;不为0,则其时隙计数自减1.请求标签发送I D 命令R equestI D (RandNum ),请求当前时隙且随机为Rand M u m 的标签发送其I D ,当前时隙的标签接收到此命令时比较其随机数是否等于Rand M um ,若相等,则向读写器发送其I D ,不相等,则不响应.图2描述了本算法具本操作过程.
255
内蒙古科技大学学报2010年9月 第29卷第3
期
图2 RDFSA 算法流程F i g .2 RDFSA algorith m 's p rocesses
3 仿真结果
图3给出了RDFSA 算法性能,图4给出了3种算法性能的比较.
由图3,4可以看出,RDFSA 算法的识读总时隙数均少于DFSA 和EDFSA 算法,随着标签数的增加几乎呈直线增长,吞吐率也保持在45%以上,在性能上比DFSA 和EDFSA 算法有很大的提高.
4 结束语
本文所提出的基于随机数传送的动态帧时隙A loha 算法通过增加标签随机数,与原时隙随机数共同定位标签,减少碰撞,从而提高识读速率.若要追求更高的效率,可以从两方面对此算法进行优化,一是改进标签估计算法,经测试,下一帧的帧时隙数等于上一帧碰撞数时能够达到较高的性能,但还不能确定这就是最优的;二是减少传输数据,从而减少
传输时间,可将随机位数设为4位.此算法非常适用于高速识别的场合,如不停车收费、物流等
.
图3 RDFSA 算法性能
F ig .3 RDFSA a l gor ithm 's perfor m
ance
图4 三种算法性能比较
Fig .4 Co m parison a m ong the perfor m ances of three a l gor ithm s
(下转第259页)
256
谢英娜等:对溴苯基偶氮基杯[4]
芳烃的合成及表征
图3 对溴苯基偶氮基杯[4]芳烃和对叔丁基杯[4]芳烃的核磁谱图
Fig .3
1
H MNR s p ectra of p -bro m ine ben zeneazo calix [4]aren es and ter t -butyl ca lix[4]aren es
参考文献:
[1] G utsche C D,Eds S t oddart J F .C ali xarenes R ev isited ,
M onog rophes i n Supramo l ecular Che m istry [M ].C a m -br i dge :The R oyal Society o f Chem i stry ,19981
[2] Y a m amo to H,U eda K,Sandanayake K,eta.l M o lecular
D esi gn of Chrom og en i c Ca li x [4]crowns W hich Show V ery H i gh N a+Se l ectiv it y [J].Che m L ett ,1995,(7):497-4991
[3] N omura E,T an i guche H,T a m ura S .Se l ective ion ex trac -ti on by a ca lix [6]arene derivati ve conta i ni ng azo groups [J].Che m L ett ,1989,(7):1125-11261
[4] Chaw la H M,S ri v is K.Synt hesis of ne w chro m ogen ic ca lix
(8)arenes [J].T etrahedron Le tt ,1994,35(18):2925-29281
[5] M a H M,Jarzak V,T hie m ann W.Syn t hesis and spectro -scop i c properti es of ne w l u m i no-l li nked ca lixarene der i va -tives[J].Ana l Chi m A cta ,1998,362(1-2):121-1291[6] 吕鉴泉,何锡文.新型主体分子噻唑偶氮基杯[n]芳烃
衍生物的合成及其对重金属离子的识别[J].高等学校化学学报,2002,23(2):191-1941
[7] G utsche C D,D ha w an B ,N o K H,M u t hukrishnan R.
C ali xarenes .4.the synt hesis ,character izati on ,and prope r -ti es o f t he ca li xarenes from p -tert -Bu t y lpheno l[J].J Am Che m Soc ,1981,103(13):3782-37921
[8] G utsche C D,L in L G.Cali xa renes 12:T he synthesis of
f unc ti ona li zed ca li xarenes T etrahedron [J].T etrahedron ,1986,42(6):1633-16401
[9] G utsche C D,Iqba lM.P-tert -butylca li x [4]arene [J].
O rg Synth ,1990,68(8):234-2361
(上接第249页)参考文献:
[1] N E MA.D ig ital I m ag i ng and Co mmun icati ons i n M ed i c i ne
(D ICOM )[Z ].U S A:ACR-NE M A standa rd publica ti on ,2007.ps3.1-ps3.71
[2] 王晓楠.D ICOM 通信的设计与实现[J].计算机工程与
应用,2004,40(13):131-1321
[3] 张晓琼.D ICOM 标准查询/找回功能模块的设计与实
现[D ].西安:西安电子科技大学,20061
[4] 王 敏.基于D IC OM 标准的医学图像通信过程的实
现[D ].西安:西安电子科技大学,20071
(上接第256页)参考文献:
[1] 游战清,刘克胜,张义强,等.无线射频识别技术
(RF I D )规划与实施[M ].北京:电子工业出版社,20061
[2] 吴京蓬,刘 娜,王爽心.RF I D 中用于解决信道争用问题
的防碰撞算法[J].仪器仪表学报,2006,27(6):694-6951[3] 魏 欣.RF ID 标签及阅读器防冲突算法研究[D ].西
安:西安电子科技大学,2009.
[4] 陆 端,王 刚,闫 述.改进ALOHA 算法在R F I D 多
目标识别中的应用[J].微计算机信息,2006,22(11-2):231-2331
[5] 杨 健,詹宜巨,王永华,等.一种基于分组动态帧与
二叉树递归识别的射频识别防冲突算法[J].信息与控制,2009,38(3):257-2631
[6] 徐圆圆,曾隽芳,刘 禹.基于A loha 算法的帧长及分
组数改进研究[J].计算机应用,2008,28(3):588-5901
259
C语言中产生随机数的方法 引例:产生10个[100-200]区间内的随机整数。 #include
随机数生成算法的研究 [日期:2006-05-23] 来源:作者:[字体:大中小] 张敬新 摘要:本文通过流程图和实际例程,较详细地阐述了随机数生成的算法和具体的程序设计,分析了其符合算法特征的特性。 关键词:随机数;算法;算法特征;程序设计 1 引言 在数据结构、算法分析与设计、科学模拟等方面都需要用到随机数。由于在数学上,整数是离散型的,实数是连续型的,而在某一具体的工程技术应用中,可能还有数据值的范围性和是否可重复性的要求。因此,我们就整数随机数和实数随机数,以及它们的数据值的范围性和是否可重复性,分别对其算法加以分析和设计。以下以Visual Basic 语言为工具,对整数随机数生成问题加以阐述,而对于实数随机数生成问题,只要稍加修改就可转化为整数随机数生成问题。 根据整数随机数范围性和是否可重复性,可分为: (1)某范围内可重复。 (2)某范围内不可重复。 (3)枚举可重复。 (4)枚举不可重复。 所谓范围,是指在两个数n1和n2之间。例如,在100和200之间这个范围,那么,只要产生的整数随机数n满足100≤n≤200,都符合要求。所谓枚举,是指有限的、已知的、若干个不连续的整数。例如,34、20、123、5、800这5个整数就是一种枚举数,也就是单独可以一个个确定下来。 2 某范围内可重复 在Visual Basic 语言中,有一个随机数函数Rnd。 语法:Rnd[(number)]。 参数number 可选,number 的值决定了Rnd 生成随机数的方式。Rnd 函数返回小于1 但大于或等于0 的值。
在调用Rnd 之前,先使用无参数的Randomize 语句初始化随机数生成器,该生成器具有一个基于系统计时器的种子。 若要生成某给定范围内的随机整数,可使用以下公式: Int((upperbound - lowerbound + 1) * Rnd + lowerbound) 这里,upperbound 是此范围的上限,而lowerbound 是范围的下限。 程序流程图: 程序例程:下面是一个生成10个10~20之间随机数的例子。 运行结果:12 10 20 20 17 17 18 14 12 20 3 某范围内不可重复
3.3.2 均匀随机数的产生 教材分析 本节内容是数学必修三第三章 概率 3.3.2均匀随机数的产生, 本节课在学生已经掌握几何概型的基础上,来学习解决几何概型问题的又一方法,本节课的教学对全面系统地理解掌握概率知识,对于培养学生自觉动手、动脑的习惯,对于学生辩证思想的进一步形成,具有良好的作用. 通过对本节课例题的模拟试验,认识用计算机模拟试验解决概率问题的方法,体会到用计算机产生随机数,可以产生大量的随机数,又可以自动统计试验的结果,同时可以在短时间内多次重复试验,可以对试验结果的随机性和规律性有更深刻的认识。 课时分配 本节内容用1课时的时间完成,主要讲解利用计算器(计算机)产生均匀随机数的方法;利用均匀随机数解决具体的有关概率的问题。 教学目标 重 点: 掌握[0,1]上均匀随机数的产生及[a,b ]上均匀随机数的产生。学会采用适当的随机模拟法去估算几何概率。 难 点:利用计算器或计算机产生均匀随机数并运用到概率的实际应用中。 知识点:通过模拟试验,感知应用数字解决问题的方法,了解均匀随机数的概念;掌握利用计算器(计算机)产生均匀随机数的方法。 能力点:利用均匀随机数解决具体的有关概率的问题,理解随机模拟的基本思想是用频率估计概率。 教育点:通过随机模拟试验,感知应用数字解决问题的方法,自觉养成动手、动脑的良好习惯,培养逻辑 思维能力和探索创新能力。 自主探究点:在信息技术环境下,通过算法解决大量重复模拟试验中的数据统计问题,得出问题的解的估计值,并由此进一步体会随机模拟方法、算法思想以及从特殊到一般的数学研究过程。 易错易混点:在计算器上用rand()产生(0,1)之间的随机数不是什么难事,但产生任意区间(a,b )上的 随机数涉及线性变换,这是学生不易处理的问题,容易出错。 教具准备 多媒体课件 一、引入新课 复习提问: (1)什么是几何概型?(2)几何概型的概率公式是怎样的?(3)几何概型的特点是什么?(4)列举几个简单的几何概型例子? 【师生活动】 (1)几何概率模型:如果每个事件发生的概率只与构成该事件区域的长度(面积或体积)成比例,则称这样的概率模型为几何概率模型; (2)几何概型的特点:1)试验中所有可能出现的结果(基本事件)有无限多个;2)每个基本事件出现的可能性相等. (3)几何概型的概率公式: P (A )=积) 的区域长度(面积或体试验的全部结果所构成积)的区域长度(面积或体构成事件A (4)几何概型例子:长3米的绳子被剪刀随机剪一次,问两段长度都不小于1米的概率?在这个几何概型中,随机剪绳子可以抽象成数学模型:从区间(0,3)中随机取一个数,由此引出今天的学习的内容,均匀随机数。
各型分布随机数的产生算法 随机序列主要用概率密度函数(PDF〃Probability Density Function)来描述。 一、均匀分布U(a,b) ?1x∈[a,b]? PDF为f(x)=?b?a?0〃其他? 生成算法:x=a+(b?a)u〃式中u为[0,1]区间均匀分布的随机数(下同)。 二、指数分布e(β) x?1?exp(?x∈[0,∞)βPDF为f(x)=?β ?0〃其他? 生成算法:x=?βln(1?u)或x=?βln(u)。由于(1?u)与u同为[0,1]均匀分布〃所以可用u 替换(1?u)。下面凡涉及到(1?u)的地方均可用u替换。 三、瑞利分布R(μ) ?xx2 exp[?x≥0?回波振幅的PDF为f(x)=?μ2 2μ2 ?0〃其他? 生成算法:x=?2μ2ln(1?u)。 四、韦布尔分布Weibull(α,β) xα??αα?1?αβxexp[?(]x∈(0,∞)βPDF为f(x)=? ?0〃其他? 生成算法:x=β[?ln(1?u)]1/α 五、高斯(正态)分布N(μ,σ2) ?1(x?μ)2 exp[?]x∈?2PDF为f(x)=?2πσ 2σ ?0〃其他? 生成算法: 1?y=?2lnu1sin(2πu2)生成标准正态分布N(0,1)〃式中u1和u2是相互独立的[0,1]区间
均匀分布的随机序列。 2?x=μ+σy产生N(μ,σ2)分布随机序列。 六、对数正态分布Ln(μ,σ2) ?1(lnx?μ)2 exp[?x>0PDF为f(x)=?2πσx 2σ2 ?0〃其他? 生成算法: 1?产生高斯随机序列y=N(μ,σ2)。 2?由于y=g(x)=lnx〃所以x=g?1(y)=exp(y)。 七、斯威林(Swerling)分布 7.1 SwerlingⅠ、Ⅱ型 7.1.1 截面积起伏 σ?1?exp[σ≥0?σ0截面积的PDF为f(σ)=?σ0〃【指数分布e(σ0)】 ?0〃其他? 生成算法:σ=?σ0ln(1?u)。 7.1.2 回波振幅起伏 ?AA2 ?exp[?2]A≥0〃式中A2=σ〃2A02=σ0。回波振幅的PDF为f(A)=?A02【瑞利分布R(A0)】2A0?0〃其他? 生成算法:A=?2A02ln(1?u)=σ0ln(1?u)。也可由A2=σ得A==?0ln(1?u) 7.2 SwerlingⅢ、Ⅳ型 7.2.1 截面积起伏 2σ?4σ]σ≥0?2exp[?σσ截面积的PDF为f(σ)=?0〃 0?0〃其他? 生成算法:σ=?式中u1和u2是相互独立的[0,1]区间均匀分布随机序列。 [ln(1?u1)+ln(1?u2)]〃2
ATmega1 28单片机的真随机数发生矗时间:2009-12-16 15:39:00 来源:单片机与嵌入式系统作者:刘晓旭,曹林,董秀成西华大学 ATmega1 28单片机的真随机数发生矗时间:2009-12-16 15:39:00 来源:单片机与嵌入式系统作者:刘晓旭,曹林,董秀成西华大学 引言 随机数已广泛地应用于仿真、抽样、数值分析、计算机程序设计、决策、美学和娱乐之中。常见的随机数发生器有两种:使用数学算法的伪随机数发生器和以物理随机量作为发生源的真随机数发生器。要获取真正随机的真随机数,常使用硬件随机数发生器的方法来获取。这些真随机数都是使基于特定的真随机数发生源(如热噪声、电流噪声等),每次获取的真随机数都是不可测的,具有很好的随机性。 真随机数因其随机性强,在数据加密、信息辅助、智能决策和初始化向量方面有着广泛应用,构建一种基于硬件真随机数发生源,具有广泛的应用价值。但目前硬件真随机数发生源均较复杂,而且很少有基于单片机的真随机数发生器。本文利用RC充放电的低稳定度,根据AVR单片机的特点设计了一种性价比极高的真随机数发生器。该随机数发生器使用元件很少,稳定性高,对一些价格敏感的特殊场合,如金融、通信、娱乐设备等有较大的应用意义。 1 基本原理和方法 1.1 基本原理 串联的RC充放电电路由于受到漏电流、电阻热噪声、电阻过剩噪声、电容极化噪声等诸多不确定性因素的影响,其充放电稳定度一般只能达到10-3。利用这种RC充放电的低稳定度特性实现廉价的真随机数发生源。 Atmel公司AVR单片机ATmega 128以其速度快、功能强、性价比高等优点广泛应用于各种嵌入式计算场合。利用AVR单片机引脚配置灵活多样的特点,使用Amnega128 两个I/O口作为真随机数的电气接口。 其原理如图1所示。主要原理是利用串联RC电路的不确定性产生真随机数源,收集数据,通过AVR单片机ATmega128和主时钟电路量化RC电路的充放电时问,获得不确定的2位二进制数据,再利用程序将每4次采集的数据综合,最后产生1个8位的真随机数。
求教:我的电子表格中rand()函数的取值范围是-1到1,如何改回1到0 回答:有两种修改办法: 是[1-rand()]/2, 或[1+rand()]/2。 效果是一样的,都可生成0到1之间的随机数 电子表格中RAND()函数的取值范围是0到1,公式如下: =RAND() 如果取值范围是1到2,公式如下: =RAND()*(2-1)+1 RAND( ) 注解: 若要生成a 与b 之间的随机实数: =RAND()*(b-a)+a 如果要使用函数RAND 生成一随机数,并且使之不随单元格计算而改变,可以在编辑栏中输入“=RAND()”,保持编辑状态,然后按F9,将公式永久性地改为随机数。 示例 RAND() 介于0 到1 之间的一个随机数(变量) =RAND()*100 大于等于0 但小于100 的一个随机数(变量) excel产生60-70随机数公式 =RAND()*10+60 要取整可以用=int(RAND()*10+60) 我想用excel在B1单元个里创建一个50-80的随机数且这个随机数要大于A1单元个里的数值,请教大家如何编写公式! 整数:=ROUND(RAND()*(80-MAX(50,A1+1))+MAX(50,A1+1),0) 无需取整数:=RAND()*(80-MAX(50,A1))+MAX(50,A1)
要求: 1,小数保留0.1 2,1000-1100范围 3,不要出现重复 =LEFT(RAND()*100+1000,6) 至于不许重复 你可以设置数据有效性 在数据-有效性设 =countif(a:a,a1)=1 选中a列设有效性就好了 其他列耶可以 急求excel随机生成数字的公式,取值要在38.90-44.03之间,不允许重复出现,保留两位小数,不允许变藏 =round(RAND()*5+38.9,2) 公式下拉 Excel随机数 Excel具有强大的函数功能,使用Excel函数,可以轻松在Excel表格产生一系列随机数。 1、产生一个小于100的两位数的整数,输入公式=ROUNDUP(RAND()*100,0)。 RAND()这是一个随机函数,它的返回值是一个大于0且小于1的随机小数。ROUNDUP 函数是向上舍入数字,公式的意义就是将小数向上舍入到最接近的整数,再扩大100倍。 2、产生一个四位数N到M的随机数,输入公式=INT(RAND()*(M-N+1))+N。 这个公式中,INT函数是将数值向下取整为最接近的整数;因为四位数的随机数就是指从1000到9999之间的任一随机数,所以M为9999,N为1000。RAND()的值是一个大于0且小于1的随机小数,M-N+1是9000,乘以这个数就是将RAND()的值对其放大,用INT 函数取整后,再加上1000就可以得到这个范围内的随机数。[公式=INT(RAND()*(9999-1000+1))+1000] 3、Excel函数RANDBETWEEN是返回位于两个指定数之间的一个随机数。使用这一个函数来完成上面的问题就更为简单了。要使用这个函数,可能出现函数不可用,并返回错误值#NAME?。 选择"工具"菜单,单击"加载宏",在"可用加载宏"列表中,勾选"分析工具库",再单击"确定"。接下来系统将会安装并加载,可能会弹出提示需要安装源,也就是office安装盘。放入光盘,点击"确定",完成安装。 现在可以在单元格输入公式=RANDBETWEEN(1000,9999)。 最后,你可以将公式复制到所有需要产生随机数的单元格,每一次打开工作表,数据都会自动随机更新。在打开的工作表,也可以执行功能键F9,每按下一次,数据就会自动随机更新了。
最近做了一些Tencent及几家公司的面试题,发现有一种关于产生随机数的类型的题目。看到多有大牛们做出来,而且效率很高,也有不知道怎么做的,最近根据几个产生随机数的题目整理一下,发现所有的类似题目可以用一种万能钥匙解决。故分享,欢迎发表不同看法,欢迎吐槽。 题目一:给定能随机生成整数1到5的函数,写出能随机生成整数1到7的函数。 利用随机函数rand()函数生成一个等概率随机生成整数1到5的函数Rand5(),然后根据Rand5()生成Rand7(),代码如下: [cpp]view plaincopy 1.#include 均匀随机数的产生 教学目标: 1.通过模拟试验,感知应用数字解决问题的方法,了解均匀随机数的概念;掌握利用计算器(计算机)产生均匀随机数的方法;自觉养成动手、动脑的良好习惯. 2.会利用均匀随机数解决具体的有关概率的问题,理解随机模拟的基本思想是用频率估计概率.学习时养成勤学严谨的学习习惯,培养逻辑思维能力和探索创新能力. 教学重点: 掌握[0,1]上均匀随机数的产生及[a,b]上均匀随机数的产生.学会采用适当的随机模拟法去估算几何概率. 教学难点: 利用计算器或计算机产生均匀随机数并运用到概率的实际应用中. 教学方法: 讲授法 课时安排 1课时 教学过程: 一、导入新课 1、复习提问:(1)什么是几何概型?(2)几何概型的概率公式是怎样的?(3)几何概型的特点是什么? 2、在古典概型中我们可以利用(整数值)随机数来模拟古典概型的问题,那么在几何概型中我们能不能通过随机数来模拟试验呢?如果能够我们如何产生随机数?又如何利用随机数来模拟几何概型的试验呢?引出本节课题:均匀随机数的产生. 二、新课讲授: 提出问题 (1)请说出古典概型的概念、特点和概率的计算公式? (2)请说出几何概型的概念、特点和概率的计算公式? (3)给出一个古典概型的问题,我们除了用概率的计算公式计算概率外,还可用什么方法得到概率?对于几何概型我们是否也能有同样的处理方法呢? (4)请你根据整数值随机数的产生,用计算器模拟产生[0,1]上的均匀随机数. (5)请你根据整数值随机数的产生,用计算机模拟产生[0,1]上的均匀随机数. (6)[a,b]上均匀随机数的产生. 活动:学生回顾所学知识,相互交流,在教师的指导下,类比前面的试验,一一作出回答,教师及时提示引导. 讨论结果: (1)在一个试验中如果 a.试验中所有可能出现的基本事件只有有限个;(有限性) b.每个基本事件出现的可能性相等.(等可能性) 我们将具有这两个特点的概率模型称为古典概率模型(classical models of probability),简称古典概型. 古典概型计算任何事件的概率计算公式为:P(A)= 基本事件的总数数 所包含的基本事件的个 A . (2)对于一个随机试验,我们将每个基本事件理解为从某个特定的几何区域内随机地取一点, 一维正态分布随机数序列的产生方法 一、文献综述 1.随机数的定义及产生方法 1).随机数的定义及性质 在连续型随机变量的分布中,最简单而且最基本的分布是单位均匀分布。由该分布抽取的简单子样称,随机数序列,其中每一个体称为随机数。 单位均匀分布也称为[0,1]上的均匀分布。 由于随机数在蒙特卡罗方法中占有极其重要的位置,我们用专门的符号ξ表示。由随机数序列的定义可知,ξ1,ξ2,…是相互独立且具有相同单位均匀分布的随机数序列。也就是说,独立性、均匀性是随机数必备的两个特点。 随机数具有非常重要的性质:对于任意自然数s,由s个随机数组成的 s维空间上的点(ξn+1,ξn+2,…ξn+s)在s维空间的单位立方体Gs上 均匀分布,即对任意的ai,如下等式成立: 其中P(·)表示事件·发生的概率。反之,如果随机变量序列ξ1, ξ2…对于任意自然数s,由s个元素所组成的s维空间上的点(ξn+1,…ξn+s)在Gs上均匀分布,则它们是随机数序列。 由于随机数在蒙特卡罗方法中所处的特殊地位,它们虽然也属于由具有已知分布的总体中产生简单子样的问题,但就产生方法而言,却有着本质上的差别。 2).随机数表 为了产生随机数,可以使用随机数表。随机数表是由0,1,…,9十个数字组成,每个数字以0.1的等概率出现,数字之间相互独立。这些数字序列叫作随机数字序列。如果要得到n位有效数字的随机数,只需将表中每n 个相邻的随机数字合并在一起,且在最高位的前边加上小数点即可。例如,某随机数表的第一行数字为7634258910…,要想得到三位有效数字的随机数依次为0.763,0.425,0.891。因为随机数表需在计算机中占有很大内存, 而且也难以满足蒙特卡罗方法对随机数需要量非常大的要求,因此,该方法不适于在计算机上使用。 3).物理方法 伪随机数的产生,现在用得较多的是“线性同余法" 就是下面这个式子 R(n+1) = [R(n) * a + b] mod c 为使随机数分布尽量均匀,a、b 均为质数, c 一般取值域内的最大值(mod 是求余数) 从这个式了可以看出,每次产生的随机数都跟上一次产生的数有关系,那么,第一个数是怎么来的呢?这就是线性同余法中必须用的的”种子",也就是说,给定某个种子后,所产生的随机数序列是固定的,在计算机编程中,一般使用系统时间来初始化种子,就是前面代码中的 srand((unsigned)time(NULL)); 这一句了。因为每次运行程序的时间肯定不一样,所以产生散列肯定也不一样,从而达到“随机”的目的。 a,b,c 的取值我用的是 a=3373, b=1, c=32768 下面的两个子程序是我在我的项目(S7-200 226)中产生随机的系统编号用的,因为我的编号中只有4位数采用了随机数,所以下面的程序中用的是整型,最大范围为32767。如果需要更宽范围的随机数,可以采用双字类型,并适当修改程序,代码很简单,就是将上面那个表达式用 S7-200 的指令表示出来就行了。 这两个子程序是从 MicroWIN V4.0 中导出来的,可以将它们用文本编辑器保存为 AW L 文件后直接导入 MicroWIN。 使用时在第一个扫描周期调用 Srand 初始种子,需要随机数的地方调用 Random Random 有了个最大范围参数,可以限制生成的随机数的最大范围,比如我只需要4位随机数,所以一般这样调用 CALL Random, 10000, vw0,生成的数就在 0-9999 范围内 下面是代码: SUBROUTINE_BLOCK Srand:SBR17 TITLE=初始化随机数种子 // // 直接使用系统时钟的分秒来作为种子 VAR_OUTPUT seed:WORD; END_VAR [核心必知] 1.预习教材,问题导入 根据以下提纲,预习教材P135~P136,回答下列问题. (1)教材问题中甲获胜的概率与什么因素有关? 提示:与两图中标注B的扇形区域的圆弧的长度有关. (2)教材问题中试验的结果有多少个?其发生的概率相等吗? 提示:试验结果有无穷个,但每个试验结果发生的概率相等. 2.归纳总结,核心必记 (1)几何概型的定义与特点 ①定义:如果每个事件发生的概率只与构成该事件区域的长度(面积或体积)成比例,则称这样的概率模型为几何概率模型,简称为几何概型. ②特点:(ⅰ)可能出现的结果有无限多个;(ⅱ)每个结果发生的可能性相等. (2)几何概型中事件A的概率的计算公式 P(A)= 构成事件A的区域长度(面积或体积) 试验的全部结果所构成的区域长度(面积或体积) . [问题思考] (1)几何概型有何特点? 提示:几何概型的特点有: ①试验中所有可能出现的结果(基本事件)有无限多个; ②每个基本事件出现的可能性相等. (2)古典概型与几何概型有何区别? 提示:几何概型也是一种概率模型,它与古典概型的区别是:古典概型的试验结果是有限的,而几何概型的试验结果是无限的. [课前反思] 通过以上预习,必须掌握的几个知识点: (1)几何概型的定义:; (2)几何概型的特点: ; (3)几何概型的计算公式: . 某班公交车到终点站的时间可能是11∶30-12∶00之间的任何一个时刻. 往方格中投一粒芝麻,芝麻可能落在方格中的任何一点上. [思考1] 这两个试验可能出现的结果是有限个,还是无限个? 提示:无限多个. [思考2] 古典概型和几何概型的异同是什么? 名师指津:古典概型和几何概型的异同 如表所示: 名称 古典概型 几何概型 相同点 基本事件发生的可能性相等 不同点 ①基本事件有限个 ①基本事件无限个 ②P (A )=0?A 为不可能事件 ②P (A )=0A 为不可能事件 ③P (B )=1?B 为必然事件 ③P (B )=1 B 为必然事件 讲一讲 1.取一根长为5 m 的绳子,拉直后在任意位置剪断,那么剪得两段的长都不小于2 m 的概率有多大? [尝试解答] 如图所示. 记“剪得两段绳长都不小于2 m ”为事件A .把绳子五等分,当剪断位置处在中间一段上 时,事件A 发生.由于中间一段的长度等于绳长的15 , 所以事件A 发生的概率P (A )=15 . 求解与长度有关的几何概型的关键点 在求解与长度有关的几何概型时,首先找到试验的全部结果构成的区域D ,这时区域D 电子信息与通信工程学院 实验报告 实验名称随机数的产生 课程名称随机信号分析 姓名顾康学号U201413323 日期6月6日地点南一楼东204 成绩教师董燕 以上为6种分布的实验结果 1.均匀分布 随机变量X~U(0,1)的一组样本值的模拟值一般采用某种数值计算方法产生随机数序列,在计算机上运算来得到,通常是利用递推公式: Xn=f(Xn-1,.....,Xn-k) 1.1 同余法 Xn+1 = λXn(mod M) Rn=Xn/M R1 R2...Rn即为(0,1)上均匀分布的随机数列。而上述方法是伪随机的,{Rn}本质上是递推公式给定的周期序列,周期T可看做logλ(M)。 解决方法是:选择模拟参数并对序列进行统计检验。 1.2选择模拟参数 1)周期长度取决于Xo,λ, M的选择 2)通过选取适当的参数可以改善随机数的性质 几组参考的取值 Xo =1 , λ=7 , M=10^10 Xo =1 , λ=5^13 , M=2 *10^10 Xo =1 , λ=5^17 , M=10^12 1.3对数列进行统计检验 对应序列能否看作X的独立同分布样本,须检验其独立性和均匀性 for i=2:1:size %同余法均匀分布 x(i)= mod ( v*x(i-1), M); y(i)=x(i)/M; end subplot(2,3,1); hist(y,100) [ahat,bhat,ACI,BCI]=unifit(y)% 以0.95的置信度估计样本的参数 首先我们的标准是U ~(0,1),而实验值,ACI表示ahat的范围[-0.0030,0], BCI表示bhat的范围[1.0000,1.0030]。同时样本的均值和方差分别为0.4932 和0.0830,结论与理论值很接近。该样本以0.95的可信度服从(0,1)均匀分布。 2.伯努利分布 2.1算法原理均匀随机数的产生 说课稿 教案 教学设计
一维正态分布随机数序列的产生方法
随机数产生方法
高中数学:均匀随机数的产生 (28)
随机数产生原理及实现
人教版高中数学必修三练习 均匀随机数的产生