
HBASE-B+树索引-谭波波
记录:谭波波
1.索引结构
1.1 B+树索引结构
从物理上说,索引通常可以分为:分区和非分区索引、常规B树索引、位图(bitmap)索引、翻转(reverse)索引等。其中,B树索引属于最常见的索引
B树索引是一个典型的树结构,其包含的组件主要是:
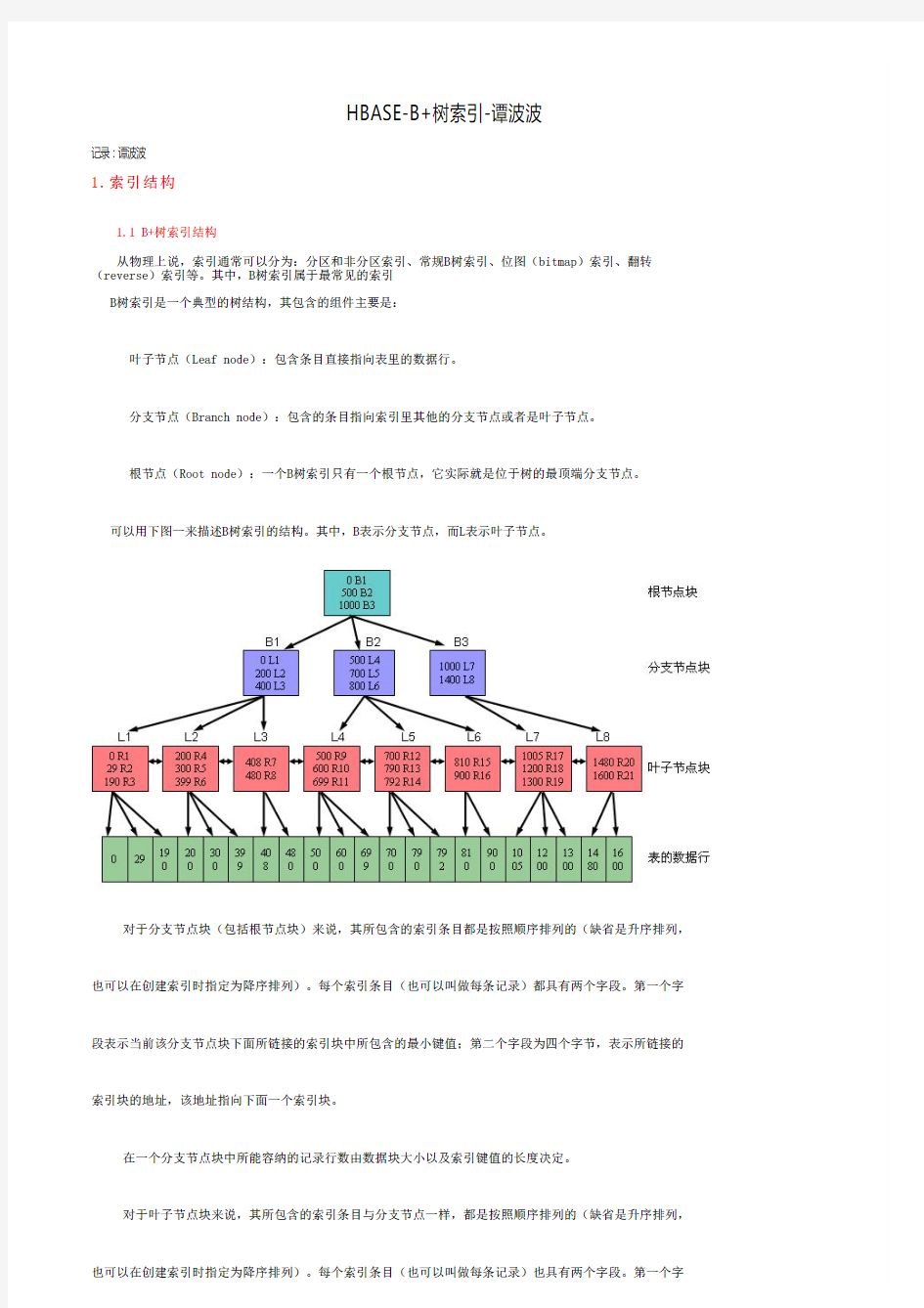
叶子节点(Leaf node):包含条目直接指向表里的数据行。
分支节点(Branch node):包含的条目指向索引里其他的分支节点或者是叶子节点。
根节点(Root node):一个B树索引只有一个根节点,它实际就是位于树的最顶端分支节点。
可以用下图一来描述B树索引的结构。其中,B表示分支节点,而L表示叶子节点。
对于分支节点块(包括根节点块)来说,其所包含的索引条目都是按照顺序排列的(缺省是升序排列,也可以在创建索引时指定为降序排列)。每个索引条目(也可以叫做每条记录)都具有两个字段。第一个字段表示当前该分支节点块下面所链接的索引块中所包含的最小键值;第二个字段为四个字节,表示所链接的索引块的地址,该地址指向下面一个索引块。
在一个分支节点块中所能容纳的记录行数由数据块大小以及索引键值的长度决定。
对于叶子节点块来说,其所包含的索引条目与分支节点一样,都是按照顺序排列的(缺省是升序排列,也可以在创建索引时指定为降序排列)。每个索引条目(也可以叫做每条记录)也具有两个字段。第一个字
段表示索引的键值,对于单列索引来说是一个值;而对于多列索引来说则是多个值组合在一起的。第二个字段表示键值所对应的记录行的ROWID,该ROWID是记录行在表里的物理地址。如果索引是创建在非分区表上或者索引是分区表上的本地索引的话,则该ROWID占用6个字节;如果索引是创建在分区表上的全局索引的话,则该ROWID占用10个字节。
1.2 估算索引条目
对于每个索引块来说,缺省的PCTFREE为10%,也就是说最多只能使用其中的90%。同时9i后,这90%
中也不可能用尽,只能使用其中的87%左右。也就是说,8KB的数据块中能够实际用来存放索引数据的
空间大约为6488(8192×90%×88%)个字节。
假设我们有一个非分区表,表名为warecountd,其数据行数为130万行。该表中有一个列,列名为goodid,其类型为char(8),那么也就是说该goodid的长度为固定值:8。同时在该列上创建了一个B树索引。
在叶子节点中,每个索引条目都会在数据块中占一行空间。每一行用2到3个字节作为行头,行头用来存放标记以及锁定类型等信息。同时,在第一个表示索引的键值的字段中,每一个索引列都有1个字节表示数据长度,后面则是该列具体的值。那么对于本例来说,在叶子节点中的一行所包含的数据大致如下图二所示:
从上图可以看到,在本例的叶子节点中,一个索引条目占18个字节。同时我们知道8KB的数据块中真正可以用来存放索引条目的空间为6488字节,那么在本例中,一个数据块中大约可以放360(6488/18)个索引条目。而对于我们表中的130万条记录来说,则需要大约3611(1300000/360)个叶子节点块。
而对于分支节点里的一个条目(一行)来说,由于它只需保存所链接的其他索引块的地址即可,而不需要保存具体的数据行在哪里,因此它所占用的空间要比叶子节点要少。分支节点的一行中所存放的所链接的最小键值所需空间与上面所描述的叶子节点相同;而存放的索引块的地址只需要4个字节,比叶子节点中所存放的ROWID少了2个字节,少的这2个字节也就是ROWID中用来描述在数据块中的行号所需的空间。因此,本例中
在分支节点中的一行所包含的数据大致如下图三所示:
从上图可以看到,在本例的分支节点中,一个索引条目占16个字节。根据上面叶子节点相同的方式,我们可以知道一个分支索引块可以存放大约405(6488/16)个索引条目。而对于我们所需要的3611个叶子节点来说,则总共需要大约9个分支索引块。
这样,我们就知道了我们的这个索引有2层,第一层为1个根节点,第二层为9个分支节点,而叶子节点数
为3611个,所指向的表的行数为1300000行。但是要注意,在oracle的索引中,层级号是倒过来的,也就是说假设某个索引有N层,则根节点的层级号为N,而根节点下一层的分支节点的层级号为N-1,依此类推。对本例来说,9个分支节点所在的层级号为1,而根节点所在的层级号为2。
2. B+树索引的管理机制
2.1 B+树索引对于插入的管理
对于B树索引的插入情况的描述,可以分为两种情况:
一种是在一个已经充满了数据的表上创建索引时,索引是怎么管理的;
另一种则是当一行接着一行向表里插入或更新或删除数据时,索引是怎么管理的。
对于第一种情况来说,比较简单。当在一个充满了数据的表上创建索引(create index命令)时,oracle会先扫描表里的数据并对其进行排序,然后生成叶子节点。生成所有的叶子节点以后,根据叶子节点的数量生成若干层级的分支节点,最后生成根节点。这个过程是很清晰的。
当一开始在一个空的表上创建索引的时候,该索引没有根节点,只有一个叶子节点。
随着数据不断被插入表里,该叶子节点中的索引条目也不断增加,当该叶子节点充满了索引条目而不能再放下新的索引条目时,该索引就必须扩张,必须再获取一个可用的叶子节点。这时,索引就包含了两个叶子节点,但是两个叶子节点不可能单独存在的,这时它们两必须有一个上级的分支节点,其实这也就是根节点
了。于是,现在,我们的索引应该具有3个索引块,一个根节点,两个叶子节点。
叶子节点的拆分过程。这个过程需要分成两种情况,一种是插入的键值不是最大值;另一种是插入的键值是最大值。
对于第一种情况来说,当一个非最大键值要进入索引,但是发现所应进入的索引块不足以容纳当前键值时:
1)从索引可用列表上获得一个新的索引数据块。
2)将当前充满了的索引中的索引条目分成两部分,一部分是具有较小键值的,另一部分是具有较大键值的。
Oracle会将具有较大键值的部分移入新的索引数据块,而较小键值的部分保持不动。
3)将当前键值插入合适的索引块中,可能是原来空间不足的索引块,也可能是新的索引块。
4)更新原来空间不足的索引块的kdxlenxt信息,使其指向新的索引块。
5)更新位于原来空间不足的索引块右边的索引块里的kdxleprv,使其指向新的索引块。
6)向原来空间不足的索引块的上一级的分支索引块中添加一个索引条目,该索引条目中保存新的索引块里的最小键值,以及新的索引块的地址。
从上面有关叶子节点分裂的过程可以看出,其过程是非常复杂的。因此如果发生的是第二种情况,则为了简
化该分裂过程,oracle省略了上面的第二步,而是直接进入第三步,将新的键值插入新的索引块中。
在上例中,当叶子节点越来越多,导致原来的根节点不足以存放新的索引条目(这些索引条目指向叶子节
点)时,则该根节点必须进行分裂。当根节点进行分裂时:
1)从索引可用列表上获得两个新的索引数据块。
2)将根节点中的索引条目分成两部分,这两部分分别放入两个新的索引块,从而形成两个新的分支节点。
3)更新原来的根节点的索引条目,使其分别指向这两个新的索引块。
因此,这时的索引层次就变成了2层。同时可以看出,根节点索引块在物理上始终都是同一个索引块。而随着
数据量的不断增加,导致分支节点又要进行分裂。分支节点的分裂过程与根节点类似(实际上根节点分裂其
实是分支节点分裂的一个特例而已):
1)从索引可用列表上获得一个新的索引数据块。
3)如果索引的clustering_factor很高,则需要重建索引来降低该值。
4)定期重建索引能够提高性能。
对于第一点来说,我们在前面已经知道,B树索引是一棵在高度上平衡的树,所以重建索引基本不可能降低其级别,除非是极特殊的情况导致该索引有非常大量的碎片,导致B树索引“虚高”,那么这实际又来到第二点上(因为碎片通常都是由于删除引起的)。实际上,对于第一和第二点,我们应该通过运行ALTER INDEX …REBUILD命令以后检查indest_stats.pct_used字段来判断是否有必要重建索引。
clustering_factor是通过oracle的索引得到表数据块的一个因子,实际上表示index列的排列顺序和表中
index这个列的排列顺序的关系。索引的重建并不能减少clustering_factor,因为重建index不能改变表中数据存放的顺序。同样,删除后再创建index也不能降低clustering_factor。降低clustering_factor的关键在于重建表里的数据。只有将表里的数据按照索引列排序以后,才能切实有效的降低clustering_factor。但是如果某个表存在多个索引的时候,需要仔细决定应该选择哪一个索引列来重建表(因为这样的索引一个表只有一个)。
需要注意的是,clustering_factor主要影响index range scan。比如当一个表有1000条数据,200个数据块时,当通过索引去读取这个表时,需要读取1000个数据块。你也许觉得奇怪这个表一共才200个数据块,怎么会需要读1000个块呢? 这是因为由于数据的存放顺序是按object_name来存放的,通过index通过
object_id的顺序来读取表必然导致oracle多次重复读取一个块。
当然,在oracle 920 开始,对于cluster_factor 比较接近表块数量的根据索引的大范围查询做了特别的处理,不再是读一个索引记录去搜索一个表记录了,而是成批处理(通过索引块一批rowid一次去表块中获得一批记录),这样就大大节约了读的成本。
关于第四点,建议是不要定期重建索引,可以是定期检查索引,只在需要时重建索引。
3.3 重建索引对性能的影响
最后我们来看一下重建索引对于性能的提高到底会有什么作用。假设我们有一个表,该表具有1百万条记录,占用了100000个数据块。而在该表上存在一个索引,在重建之前的pct_used为50%,高度为3,分支节点块数为40个,再加一个根节点块,叶子节点数为10000个;重建该索引以后,pct_used为90%,高度为3,分支节点块数下降到20个,再加一个根节点块,而叶子节点数下降到5000个。那么从理论上说:
1)如果通过索引获取单独1条记录来说:
重建之前的成本:1个根+1个分支+1个叶子+1个表块=4个逻辑读
重建之后的成本:1个根+1个分支+1个叶子+1个表块=4个逻辑读
性能提高百分比:0
2)如果通过索引获取100条记录(占总记录数的0.01%)来说,分两种情况:
最差的clustering_factor(即该值等于表的数据行数):
重建之前的成本:1个根+1个分支+0.0001*10000(1个叶子)+100个表块=103个逻辑读
重建之后的成本:1个根+1个分支+0.0001*5000(1个叶子)+100个表块=102.5个逻辑读
性能提高百分比:0.5%(也就是减少了0.5个逻辑读)
最好clustering_factor(即该值等于表的数据块):
重建之前的成本:1个根+1个分支+0.0001*10000(1个叶子)+0.0001*100000(10个表块)=13个逻辑读
重建之后的成本:1个根+1个分支+0.0001*5000(1个叶子)+0.0001*100000(10个表块)=12.5个逻辑读
性能提高百分比:3.8%(也就是减少了0.5个逻辑读)
3)如果通过索引获取10000条记录(占总记录数的1%)来说,分两种情况:
最差的clustering_factor(即该值等于表的数据行数):
二叉排序树的基本操作的实现
————————————————————————————————作者: ————————————————————————————————日期:
二叉排序树的基本操作的实现
一设计要求 1.问题描述 从磁盘读入一组数据,建立二叉排序树并对其进行查找、、遍历、插入、删除等基本操作。 2.需求分析 建立二叉排序树并对其进行查找,包括成功和不成功两种情况。 二概要设计 为了实现需求分析中的功能,可以从以下3方面着手设计。 1.主界面设计 为了方便对二叉排序树的基本操作,设计一个包含多个菜单选项的主控制子程序以实现二叉排序树的各项功能。本系统的主控制菜单运行界面如图1所示。 图1二叉排序树的基本操作的主菜单 2.存储结构的设计 本程序主要采二叉树结构类型来表示二叉排序树。其中二叉树节点由1个表示关键字的分量组成,还有指向该左孩子和右孩子的指针。 3.系统功能设计 本程序设置了5个子功能菜单,其设计如下。 1)建立二叉排序树。根据系统提示,输入节点的关键字,并以0作为结束的标识符。 该功能由Bstree Create()函数实现。 2)插入二叉排序新的节点信息。每次只能够插入一个节点信息,如果该节点已 经存在,则不插入。该功能由Bstree Insert(y)函数实现。 3)查询二叉排序树的信息。每次进行查询,成功则显示“查询到该节点”,不成功 则“显示查询不到该节点“该功能由Bstree Search()函数实现。 4)删除二叉排序树的节点信息。可以对二叉排序树中不需要的节点进行删除, 删除的方式是输入关键字,查询到该节点后删除。该功能由BstreeDelete() 函数实现。 5)遍历二叉排序树。遍历二叉排序树可以显示该二叉排序树的全部节点信息。 该功能由void Traverse()实现。 三模块设计 1.模块设计 本程序包含两个模块:主程序模块和二叉排序树操作模块。其调用关系如图2
课程设计任务书 题目: 二叉排序树的建立及遍历的实现 初始条件: 理论:学习了《数据结构》课程,掌握了基本的数据结构和常用的算法; 实践:计算机技术系实验室提供计算机及软件开发环境。 要求完成的主要任务:(包括课程设计工作量及其技术要求,以及说明书撰写等具体要求)1、系统应具备的功能: (1)建立二叉排序树; (2)中序遍历二叉排序树并输出排序结果; 2、数据结构设计; 3、主要算法设计; 4、编程及上机实现; 5、撰写课程设计报告,包括: (1)设计题目; (2)摘要和关键字; (3)正文,包括引言、需求分析、数据结构设计、算法设计、程序实现及测试、设计体会等; (4)结束语; (5)参考文献。 时间安排:2007年7月2日-7日(第18周) 7月2日查阅资料 7月3日系统设计,数据结构设计,算法设计 7月4日-5日编程并上机调试7月6日撰写报告 7月7日验收程序,提交设计报告书。 指导教师签名: 2007年7月2日 系主任(或责任教师)签名: 2007年7月2日 排序二叉树的建立及其遍历的实现
摘要:我所设计的课题为排序二叉树的建立及其遍历的实现,它的主要功能是将输入的数据 组合成排序二叉树,并进行,先序,中序和后序遍历。设计该课题采用了C语言程序设计,简洁而方便,它主要运用了建立函数,调用函数,建立递归函数等等方面来进行设计。 关键字:排序二叉树,先序遍历,中序遍历,后序遍历 0.引言 我所设计的题目为排序二叉树的建立及其遍历的实现。排序二叉树或是一棵空树;或是具有以下性质的二叉树:(1)若它的左子树不空,则作子树上所有的结点的值均小于它的根结点的值;(2)若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;(3)它的左,右子树也分别为二叉排序树。对排序二叉树的建立需知道其定义及其通过插入结点来建立排序二叉树,遍历及其输出结果。 该设计根据输入的数据进行建立排序二叉树。对排序二叉树的遍历,其关键是运用递归 调用,这将极大的方便算法设计。 1.需求分析 建立排序二叉树,主要是需要建立节点用来存储输入的数据,需要建立函数用来创造排序二叉树,在函数内,需要进行数据比较决定数据放在左子树还是右子树。在遍历二叉树中,需要建立递归函数进行遍历。 该题目包含两方面的内容,一为排序二叉树的建立;二为排序二叉树的遍历,包括先序遍历,中序遍历和后序遍历。排序二叉树的建立主要运用了循环语句和递归语句进行,对遍历算法运用了递归语句来进行。 2.数据结构设计 本题目主要会用到建立结点,构造指针变量,插入结点函数和建立排序二叉树函数,求深度函数,以及先序遍历函数,中序遍历函数和后序遍历函数,还有一些常用的输入输出语句。对建立的函明确其作用,先理清函数内部的程序以及算法在将其应用到整个程序中,在建立排序二叉树时,主要用到建立节点函数,建立树函数,深度函数,在遍历树是,用到先序遍历函数,中序遍历函数和后序遍历函数。
浙江大学城市学院实验报告 课程名称数据结构 实验项目名称实验十二叉树的基本操作 学生姓名专业班级学号 实验成绩指导老师(签名)日期 一.实验目的和要求 1、掌握二叉树的链式存储结构。 2、掌握在二叉链表上的二叉树操作的实现原理与方法。 3、进一步掌握递归算法的设计方法。 二.实验内容 1、按照下面二叉树二叉链表的存储表示,编写头文件binary_tree.h,实现二叉链表的定义与基本操作实现函数;编写主函数文件test10.cpp,验证头文件中各个操作。 二叉树二叉链表存储表示如下: typedef struct BiTNode { TElemType data ; struct BiTNode *lchild , *rchild ; }BiTNode,*BiTree ; 基本操作如下: ①void InitBiTree(BiTree &T ) //初始化二叉树T ②void CreateBiTree(BiTree &T) //按先序遍历序列建立二叉链表T ③bool BiTreeEmpty (BiTree T); //检查二叉树T是否为空,空返回1,否则返回0 ④int BiTreeDepth(BiTree T); //求二叉树T的深度并返回该值 ⑤void PreOrderTraverse (BiTree T); //先序遍历二叉树T ⑥void InOrderTraverse (BiTree T); //中序遍历二叉树T ⑦void PostOrderTraverse (BiTree T); //后序遍历二叉树T ⑧void DestroyBiTree(BiTree &T) //销毁二叉树T
合肥学院 计算机科学与技术系 课程设计报告 2009 ~2010 学年第二学期 课程 数据结构与算法 课程设计 名称 二叉排序树运算学生姓名顾成方 学号0704011033 专业班级08计科(2) 指导教师王昆仑张贯虹 2010 年 5 月
题目:(二叉排序树运算问题)设计程序完成如下要求:对一组数据构造二叉排序树,并在二叉排序树中实现多种方式的查找。基本任务:⑴选择合适的储存结构构造二叉排序树;⑵对二叉排序树T作中序遍历,输出结果;⑶在二叉排序树中实现多种方式的查找,并给出二叉排序树中插入和删除的操作。 ⑷尽量给出“顺序和链式”两种不同结构下的操作,并比较。 一、问题分析和任务定义 本次程序需要完成如下要求:首先输入任一组数据,使之构造成二叉排序树,并对其作中序遍历,然后输出遍历后的数据序列;其次,该二叉排序树能实现对数据(即二叉排序树的结点)的查找、插入和删除等基本操作。 实现本程序需要解决以下几个问题: 1、如何构造二叉排序树。 2、如何通过中序遍历输出二叉排序树。 3、如何实现多种查找。 4、如何实现插入删除等操作。 二叉排序树的定义:
⑴其左子树非空,则左子树上所有结点的值均小于根结点的值。 ⑵若其右子树非空,则右子树上所有结点的值大于根结点的值。 ⑶其左右子树也分别为二叉排序树。 本问题的关键在于对于二叉排序树的构造。根据上述二叉排序树二叉排序树的生成需要通过插入算法来实现:输入(插入)的第一个数据即为根结点;继续插入,当插入的新结点的关键值小于根结点的值时就作为左孩子,当插入的新结点的关键值大于根结点的值时就作为右孩子;在左右子树中插入方法与整个二叉排序树相同。当二叉排序树建立完成后,要插入新的数据时,要先判断已建立的二叉排序树序列中是否已有当前插入数据。因此,插入算法还要包括对数据的查找判断过程。 本问题的难点在于二叉排序树的删除算法的实现。删除前,首先要进行查找,判断给出的结点是否已存在于二叉排序树之中;在删除时,为了保证删除结点后的二叉树仍为二叉排序树,要考虑各种情况,选择正确
wyf 实现二叉排序树的各种算法 一.需求分析 (1)系统概述: 本系统是针对排序二叉树设计的各种算法,提供的功能包括有:(1)插入新结点(2)前序、中序、后序遍历二叉树(3)中序遍历的非递归算法(4)层次遍历二叉树(5)在二叉树中查找给定关键字(函数返回值为成功1,失败0) 二.总体设计 (1)系统模块结构图
(2)数据结构设计 typedef struct BiTNode{ ElemType data; struct BiTNode *lchild,*rchild;//左右孩子指针} BiTNode,*BiTree; typedef BiTree SElemType; typedef BiTree QElemType; typedef struct {
QElemType *base; // 初始化的动态分配存储空间 int front; // 头指针,若队列不空,指向队列头元素 int rear; // 尾指针,若队列不空,指向队列尾元素的下一个位置 }SqQueue; typedef struct { SElemType *base; // 在栈构造之前和销毁之后,base的值为NULL SElemType *top; // 栈顶指针 int stacksize; // 当前已分配的存储空间,以元素为单位 }SqStack; // 顺序栈 Status InitStack(SqStack &S) { // 构造一个空栈S,该栈预定义大小为STACK_INIT_SIZE // 请补全代码 S.base = (SElemType * )malloc(STACK_INIT_SIZE * sizeof(SElemType)); if(!S.base) return (ERROR); S.top = S.base ;
数据库的存储结构(文件、记录的组织和索引技术) by 沈燕然0124141 利用课余时间自学了第6章《数据库存储结构》,对于数据 库不同层次的存储结构,文件记录组织和索引技术有了一定的 了解,在这篇札记中将会结合一些具体应用中涉及到的数据存 储和索引知识,以及通过与过去学习过的一些数据结构比较来 记录自己学习的心得体会。这些实例涉及不同的数据库系统, 如Oracle, DB2和Mysql等等,它们之间会有一些差异。不过 本文旨在探讨数据存储方面的问题,因而兼容并包地将其一并收入,凡是可能需要说明之处都会加上相应的注解。:) 1、数据库(DBS)由什么组成?——逻辑、物理和性能特征 1、什么是数据库系统(DBS)——DBS用文件系统实现 在关系模型中,我们把DBS看成关系的汇集。DBS存在的目的就是为了使用户能够简单、方便、容易地存取数据库中的数据。因此在用户的眼中,数据库也就是以某种方式相关的表的集合。用户并不需要去关心表之间关系,更不需要了解这些表是怎样存储的。但是我们现在从DBA(数据库管理员)的角度来看,情况就比那稍稍复杂一点。 实际的数据库包含许多下面列出的物理和逻辑对象: ?表、视图、索引和模式(确定数据如何组织) ?锁、触发器、存储过程和包(引用数据库的物理实现) ?缓冲池、日志文件和表空间(仅处理如何管理数据库性能) 2、什么是表空间?——表空间相当于文件系统中的文件夹。 表空间被用作数据库和包含实际表数据的容器对象之间的一层,表空间可以包含多个不同的表。用户处理的实际数据位于表中,他们并不知道数据的物理表示,这种情况有时被称为数据的物理无关性。
上图描述了一个ORACLE数据库大致的表空间组织,USER中存放主要的数据表,TEMP存放临时数据表,INDX存放索引,TOOLS存放回退段(RBS). 表空间在DB2数据库系统中是比较典型的说法,在Mysql等系统中也直接使用文件系统中文件夹的概念。新建一个表的时候可以指定它所在的表空间,至于用文件具体存储数据时如何存储这可能就是各个数据库系统的商业机密了,至少DB2是这样。另外值得关注的一点是不同于oracles对表空间的严格要求,Mysql的数据库形式相对比较简单,以文件夹的形式存放在安装目录的/data/下面,该数据库的每一个表对应两个文件,一个存放表中数据,另一个存放元数据信息,也就是建表时指明的列属性等等信息。 3、文件中的记录在物理上如何实现?——文件组织形式 在外存中,DB以文件形式组织,而文件由记录组成。文件结构由OS的文件系统提供和管理。文件组织有两种方式——定长记录格式和变长记录格式。 那种格式更好? 定长记录格式——优点是插入操作较简单。 缺点是对记录长度有硬性要求,而且有的记录可能横跨多个快,降低读写效率。 变长记录格式——优点是记录长度自由方便 缺点是记录长度差异导致删除后产生大量“碎片”,记录很难伸长,尤其“被拴记录”移动代价相当大。 中庸之道——预留空间和指针方式 记录长度大多相近——采用预留空间方法,取最大记录长为统一标准,在短记录多于空间处填特定空值或记录尾标志符。 记录长度相差很大——采用指针形式(每纪录后的指针字段把相同属性值记录链接起来)。文件中使用两种块——固定块(存放每条链中第一条记录)和溢出块(存放其 余纪录)。 3、记录在文件中怎样组织?
课程设计 课程名称数据结构课程设计 题目名称二叉排序树的实现 学院应用数学学院 专业班级 学号 学生 指导教师 2013 年 12 月 26 日
1.设计任务 1)实现二叉排序树,包括生成、插入,删除; 2)对二叉排序树进行先根、中根、和后根非递归遍历; 3)每次对树的修改操作和遍历操作的显示结果都需要在屏幕上 用树的形状表示出来。 4)分别用二叉排序树和数组去存储一个班(50人以上)的成员信 息(至少包括学号、、成绩3项),对比查找效率,并说明 为什么二叉排序树效率高(或者低)。 2. 函数模块: 2.1.主函数main模块功能 1.通过bstree CreatTree()操作建立二叉排序树。 2.在二叉排序树t过操作bstree InsertBST(bstree t,int key,nametype name,double grade)插入一个节点。 3. 从二叉排序树t过操作void Delete(bstree &p)删除任意节点。 4. 在二叉排序树t过操作bstnode *SearchBST(bstree t,keytype key)查 找节点。 5. 在二叉排序树t过操作p=SearchBST(t,key)查询,并修改节点信息 6. 非递归遍历二叉排序树。 7. 定义函数void compare()对数组和二叉排序树的查找效率进行比较比 较。 2.2创建二叉排序树CreatTree模块 从键盘中输入关键字及记录,并同时调用插入函数并不断进行插入。最后,返回根节点T。 2.3删除模块: 二叉排序树上删除一个阶段相当于删去有序系列中的一个记录,只要在删除某个节点之后依旧保持二叉排序树的性质即可。假设二叉排序树上删除节点为*p(指向节点的指针为p),其双亲节点为*f(节点指针为f)。若*p节点为叶子节点,则即左右均为空树,由于删去叶子节点不破坏整棵树的结构,则只需修改其双亲节点的指针即可;若*p节点只有左子树或只有右子树,此时只要令左子树或右子树直接成为其双亲节点*f的左子树即可;若*p节点的左子树和右子树均不为空,其一可以令*p的左子树为*f的左子树,而*p的右子树为*s的右子树,其二可以令*p的直接前驱(或直接后继)替代*p,然后再从二叉排序树中删去它的直接前驱(或直接后继)。在二叉排序树中删除一个节点的算法为 void DeleteData(bstree &t,keytype key) 若二叉排序树t中存在关键字等于key的数据元素,则删除该数据元素节点,并返回TRUE,否则返回FALSE。 2.4插入模块 二叉排序树是一种动态树表,其特点是树的结构通常不是一次生成的,而是在查找的过程中,当树中不存在关键字等于给定值得节点时在进行插入。
内蒙古科技大学 本科生课程设计论文《数据结构与算法》 题目:二叉排序树的操作 学生姓名:贺英杰 学号:1367159108 专业:软件工程 班级:13-1班 指导教师:周李涌 日期:2015年1月6日
内蒙古科技大学课程设计任务书课程名称数据结构与算法课程设计 设计题目二叉排序树的操作 指导教师周李涌时间2015.1.5——2015.1.9 一、教学要求 1. 掌握数据结构与算法的设计方法,具备初步的独立分析和设计能力 2. 初步掌握软件开发过程的问题分析、系统设计、程序编码、测试等基本方法和技能 3. 提高综合运用所学的理论知识和方法独立分析和解决问题的能力 4. 训练用系统的观点和软件开发一般规范进行软件开发,培养软件工作者所应具备的科学的工作方法和作风 二、设计资料及参数 每个学生在教师提供的课程设计题目中任意选择一题,独立完成,题目选定后不可更换。 二叉排序树的操作 以二叉链表表示二叉排序树,在此基础上实现二叉排序树的操作。 要求设计类(或类模板)来描述二叉排序树,包含必要的构造函数和析构函数,以及其他能够完成如下功能的成员函数: 创建二叉排序树 输出二叉排序树 在二叉排序树中查找给定值 在二叉排序树中插入新结点 在二叉排序树中删除给定值 并设计主函数测试该类(或类模板)。 三、设计要求及成果 1. 分析课程设计题目的要求 2. 写出详细设计说明 3. 编写程序代码,调试程序使其能正确运行 4. 设计完成的软件要便于操作和使用 5. 设计完成后提交课程设计报告 四、进度安排 资料查阅与讨论(1天) 系统分析(2天) 系统的开发与测试(5天) 编写课程设计说明书和验收(2天) 五、评分标准 1. 根据平时上机考勤、表现和进度,教师将每天点名和检查 2. 根据课程设计完成情况,必须有可运行的软件。 3. 根据课程设计报告的质量,如有雷同,则所有雷同的所有人均判为不及格。 4. 根据答辩的情况,应能够以清晰的思路和准确、简练的语言叙述自己的设计和回答教师的提问 六、建议参考资料 1.《数据结构(C语言版)》严蔚敏、吴伟民主编清华大学出版社2004.11 2.《数据结构课程设计案例精编(用C/C++描述)》,李建学等编著,清华大学出版社 2007.2 3.《数据结构:用面向对象方法与C++语言描述》,殷人昆主编,清华大学出版社 2007.6
数据结构课程设计---二叉排序树和平衡二叉树的判别
二叉排序树和平衡二叉树的判别 1引言 数据结构是软件工程的一门核心专业基础课程,在我们专业的课程体系中起着承上启下的作用,学好数据结构对于提高理论认知水平和实践能力有着极为重要的作用。学习数据结构的最终目的是为了获得求解问题的能力。对于现实世界中的问题,应该能从中抽象出一个适当的数据模型,该数学模型在计算机内部用相应的数据结构来表示,然后设计一个解此数学模型的算法,在进行编程调试,最后获得问题的解答。 本次课程设计的题目是对二叉排序树和平衡二叉树的扩展延伸应用。首先我们得建立一个二叉树,二叉树有顺序存储结构和链式存储结构两种存储结构,此次我选用的是二叉链表的存储结构。对于判断平衡二叉树,需要求出其每个叶子结点所在的层数,这里我采用的边遍历边求的方式,遍历采用的是先序遍历。二叉树的建立以及二叉排序树和平衡二叉树的判别中都用到了递归思想。 2需求分析 2.1在日常生活中,人们几乎每天都要进行“查找”工作。所谓“查找”即为 在一个含有众多的数据元素(或记录)的查找表中找出某个“特定的”数据元素(或记录),即关键字。 2.2本程序意为对一个已经建立的动态查找表——二叉树——判断其是否是二 叉排序树和平衡二叉树。 3数据结构设计 3.1抽象数据类型二叉树的定义如下: ADT BinaryTree{ 3.1.1数据对象D:D是具有相同特性的数据元素的集合。 3.1.2数据关系R: 若D=NULL,则R=NULL,称BinaryTree为空的二叉树; 若D!=NULL,则R={H},H是如下的二元关系: 3.1.2.1在D中存在唯一的称为根的数据元素root,它在关系H下无前驱; 3.1.2.2若D-{root}!=NULL,则存在D-{root}={Dl,Dr},且Dl与Dr相交为空; 3.1.2.3若Dl!=NULL,则Dl中存在唯一的元素xl,
数据结构练习(三)参考 一、选择题 1.顺序查找法适合于存储结构为的线性表 A)哈希存储 B)顺序存储或链式存储 C)压缩存储 D)索引存储 2.一个长度为100的已排好序的表,用二分查找法进行查找,若查找不成功, 至少比较________次。 A)9 B)8 C)7 D)6 3.采用顺序查找方法查找长度为n的线性表时,平均比较次数为。A)n B)n/2 C)(n+1)/2 D)(n-1)/2 4.对线性表进行折半查找时,要求线性表必须。 A)以顺序方式存储B)以顺序方式存储,且结点按关键字有序排列 C)以链表方式存储D)以链表方式存储,且结点按关键字有序排列 5.采用二分查找法查找长度为n的线性表时,每个元素的平均查找长度为。 A)O(n2)B)O(nlog2n)C)O(n)D)O(log2n) 6.有一个长度为12的有序表R[0…11],按折半查找法对该表进行查找,在表内各元素等概率查找情况下查找成功所需的平均比较次数为。 A)35/12 B)37/12 C)39/12 D)43/12 7.有一个有序表为{1,3,9,12,32,41,45,62,75,77,82,95,99},当采用折半查找法查找关键字为82的元素时,次比较后查找成功。A)1 B.2 C)4 D)8 8.当采用分块查找时,数据的组织方式为。 A)数据分成若干块,每块内存数据有序 B)数据分成若干块,每块内数据不必有序,但块间必须有序,每块内最大(或最小)的数据组成索引块 C)数据分成若干块,每块内数据有序,每块内最大(或最小)的数据组成索引块 D)数据分成若干块,每块(出最后一块外)中的数据个数需相同 9.采用分块查找时,若线性表中共有625个元素,查找每个元素的概率相同,
二叉树的各种算法.txt男人的承诺就像80岁老太太的牙齿,很少有真的。你嗜烟成性的时候,只有三种人会高兴,医生你的仇人和卖香烟的。 /*用函数实现如下二叉排序树算法: (1)插入新结点 (2)前序、中序、后序遍历二叉树 (3)中序遍历的非递归算法 (4)层次遍历二叉树 (5)在二叉树中查找给定关键字(函数返回值为成功1,失败0) (6)交换各结点的左右子树 (7)求二叉树的深度 (8)叶子结点数 Input 第一行:准备建树的结点个数n 第二行:输入n个整数,用空格分隔 第三行:输入待查找的关键字 第四行:输入待查找的关键字 第五行:输入待插入的关键字 Output 第一行:二叉树的先序遍历序列 第二行:二叉树的中序遍历序列 第三行:二叉树的后序遍历序列 第四行:查找结果 第五行:查找结果 第六行~第八行:插入新结点后的二叉树的先、中、序遍历序列 第九行:插入新结点后的二叉树的中序遍历序列(非递归算法) 第十行:插入新结点后的二叉树的层次遍历序列 第十一行~第十三行:第一次交换各结点的左右子树后的先、中、后序遍历序列 第十四行~第十六行:第二次交换各结点的左右子树后的先、中、后序遍历序列 第十七行:二叉树的深度 第十八行:叶子结点数 */ #include "stdio.h" #include "malloc.h" #define TRUE 1 #define FALSE 0 #define OK 1 #define ERROR 0
#define INFEASIBLE -1 #define OVERFLOW -2 typedef int Status; typedef int KeyType; #define STACK_INIT_SIZE 100 // 存储空间初始分配量 #define STACKINCREMENT 10 // 存储空间分配增量 #define MAXQSIZE 100 typedef int ElemType; typedef struct BiTNode{ ElemType data; struct BiTNode *lchild,*rchild;//左右孩子指针 } BiTNode,*BiTree; Status SearchBST(BiTree T,KeyType key,BiTree f,BiTree &p) { if(!T){p=f;return FALSE;} else if(key==T->data){p=T;return TRUE;} else if(key
《数据结构与数据库》 实验报告 实验题目 二叉树的基本操作及运算 一、需要分析 问题描述: 实现二叉树(包括二叉排序树)的建立,并实现先序、中序、后序和按层次遍历,计算叶子结点数、树的深度、树的宽度,求树的非空子孙结点个数、度为2的结点数目、度为2的结点数目,以及二叉树常用运算。 问题分析: 二叉树树型结构是一类重要的非线性数据结构,对它的熟练掌握是学习数据结构的基本要求。由于二叉树的定义本身就是一种递归定义,所以二叉树的一些基本操作也可采用递归调用的方法。处理本问题,我觉得应该:
1、建立二叉树; 2、通过递归方法来遍历(先序、中序和后序)二叉树; 3、通过队列应用来实现对二叉树的层次遍历; 4、借用递归方法对二叉树进行一些基本操作,如:求叶子数、树的深度宽度等; 5、运用广义表对二叉树进行广义表形式的打印。 算法规定: 输入形式:为了方便操作,规定二叉树的元素类型都为字符型,允许各种字符类型的输入,没有元素的结点以空格输入表示,并且本实验是以先序顺序输入的。 输出形式:通过先序、中序和后序遍历的方法对树的各字符型元素进行遍历打印,再以广义表形式进行打印。对二叉树的一些运算结果以整型输出。 程序功能:实现对二叉树的先序、中序和后序遍历,层次遍历。计算叶子结点数、树的深度、树的宽度,求树的非空子孙结点个数、度为2的结点数目、度为2的结点数目。对二叉树的某个元素进行查找,对二叉树的某个结点进行删除。 测试数据:输入一:ABC□□DE□G□□F□□□(以□表示空格),查找5,删除E 预测结果:先序遍历ABCDEGF 中序遍历CBEGDFA 后序遍历CGEFDBA 层次遍历ABCDEFG 广义表打印A(B(C,D(E(,G),F))) 叶子数3 深度5 宽度2 非空子孙数6 度为2的数目2 度为1的数目2 查找5,成功,查找的元素为E 删除E后,以广义表形式打印A(B(C,D(,F))) 输入二:ABD□□EH□□□CF□G□□□(以□表示空格),查找10,删除B 预测结果:先序遍历ABDEHCFG 中序遍历DBHEAGFC 后序遍历DHEBGFCA 层次遍历ABCDEFHG 广义表打印A(B(D,E(H)),C(F(,G))) 叶子数3 深度4 宽度3 非空子孙数7 度为2的数目2 度为1的数目3 查找10,失败。
数据库系统实现 实验报告 实验名称: B -树索引的建立 一、实验内容 使用B-树对数据库进行索引。按照学生ID建立起B树索引。实验需要建立两个文本文件:数据文件datafile.txt和命令文件command.txt。数据文件包含了所有需要建立检索的学生信息,文本中的每一行包含一个学生的信息。每一行将由6个空格分隔的字符段组成:ID (9位),姓(最多15个字符),名(最多
15个字符),年级(1位),专业(最多4个字符),以及邮箱地址(最多20个字符)。 二、实验分析: 三、步骤分析及流程图 步骤分析:一个具有10,000,000个记录的文本文件共计10,000,000*100B=1000MB,而内存只有50MB,50MB/4KB=50*1024 KB/4KB=12800块,每块可以存放4*1024B/100B=40个记录,每块剩余96KB,内存一共可以存放12800*40=512000个记录,一共有10,000,000个记录。 所以要进行10,000,000/512000=19.53次,即20次排序,每次排序的记录数为10,000,000/20=500,000个记录。 因此此次实验需要将文本文件分成20个子文件。分别对子文件分别进行内部排序。最后对20个排好序的子文件进行归并排序,完成排序。 故将其分为三个阶段 1.生成一个具有10,000,000个记录的文本文件data.txt,其中每个记 录由100个字节组成,其中只有一个整数类型属性A,剩余字节用0 填充。程序生成一个4个字节之内随机整数作为每条记录的属性, 剩余字节用0填充。记录写入data.txt文件中。 2.根据实验分析,将data.txt文件分为20个子文件,并且按照文件 中每个记录的属性对各个子文件进行内部排序,最终形成20个有序 的子文件data1.txt,data2,txt,…data20.txt。 3.对20个有序的子文件进行归并排序,最终形成一个有序的结果文件 result.txt。 流程图: 阶段一流程图见图1.1
中北大学 数据结构 课程设计说明书 2011年12月20日
1.设计任务概述:
功能描述: (1)以回车('\n')为输入结束标志,输入数列L,生成一棵二叉排序树T; (2)对二叉排序树T作中序遍历,输出结果; (3)输入元素x,查找二叉排序树T,若存在含x的结点,则删除该结点,并作中序遍历(执行操作2);否则输出信息“无x”。 2.本设计所采用的数据结构 二叉树及二叉链表 3.功能模块详细设计 详细设计思想 建立二叉排序树采用边查找边插入的方式。查找函数采用递归的方式进行查找。如果查找到相等的则插入其左子树。然后利用插入函数将该元素插入原树。 对二叉树进行中序遍历采用递归函数的方式。在根结点不为空的情况下,先访问左子树,再访问根结点,最后访问右子树。 删除结点函数,采用边查找边删除的方式。如果没有查找到,进行提示;如果查找到结点则将其左子树最右边的节点的数据传给它,然后删除其左子树最右边的节点。 核心代码 (1)主菜单模块 int main(){ LNode root=NULL; int Num,a,x; printf("\n\n *******************************\n"); printf(" ************主菜单*************\n"); printf(" *1:进行中序排列*\n"); printf(" *2:进行删除操作
*\n"); printf(" *3:退出*\n"); printf(" *******************************\n"); printf("请输入要进行操作的数字以0结束:\n"); 运行结果 (3)中序遍历模块 void view(LNode p){
编号:B04900083 学号:8 Array课程设计 教学院计算机学院 课程名称数据结构与算法 题目二叉排序树与平衡二叉排序树基本操 作的实现 专业计算机科学与技术 班级二班 姓名 同组人员 指导教师成俊 2015 年12 月27 日
课程设计任务书 2015 ~2016 学年第 1 学期 学生:专业班级:计科二 指导教师:成俊工作部门:计算机学院 一、课程设计题目:二叉排序树与平衡二叉排序树基本操作 二、课程设计容 用二叉链表作存储结构,编写程序实现二叉排序树上的基本操作:以回车('\n')为输入结束标志,输入数列L,生成二叉排序树T;对二叉排序树T作中序遍历;计算二叉排序树T的平均,输出结果;输入元素x,查找二叉排序树T,若存在含x的结点,则删除该结点,并作中序遍历;否则输出信息“无结点x”; 判断二叉排序树T是否为平衡二叉树;再用数列L,生成平衡二叉排序树BT:当插入新元素之后,发现当前的二叉排序树BT不是平衡二叉排序树,则立即将它转换成新的平衡二叉排序树BT;计算平衡的二叉排序树BT的平均查找长度,输出结果。 三、进度安排 1.分析问题,给出数学模型,选择数据结构. 2.设计算法,给出算法描述 3.给出源程序清单 4. 编辑、编译、调试源程序 5. 撰写课程设计报告 四、基本要求 编写AVL树判别程序,并判别一个二叉排序树是否为AVL树。二叉排序树用其先序遍历结果表示,如:5,2,1,3,7,8。 实现AVL树的ADT,包括其上的基本操作:结点的加入和删除;另外包括将一般二叉排序树转变为AVL树的操作。 实现提示主要考虑树的旋转操作。
目录 一、课程设计题目: 二叉排序树与平衡二叉排序树基本操作 (1) 二、课程设计容 (1) 三、进度安排 (1) 四、基本要求 (1) 一、概述 (3) 1.课程设计的目的 (3) 2.课程设计的要求 (3) 二、总体方案设计 (4) 三、详细设计 (6) 1.课程设计总体思想 (6) 2.模块划分 (7) 3.流程图 (8) 四、程序的调试与运行结果说明 (9) 五、课程设计总结 (14) 参考文献 (14)
5.1树的概念 树的递归定义如下:(1)至少有一个结点(称为根)(2)其它是互不相交的子树 1.树的度——也即是宽度,简单地说,就是结点的分支数。以组成该树各结点中最大的度作为该树的度,如上图的树,其度为3;树中度为零的结点称为叶结点或终端结点。树中度不为零的结点称为分枝结点或非终端结点。除根结点外的分枝结点统称为内部结点。 2.树的深度——组成该树各结点的最大层次,如上图,其深度为4; 3.森林——指若干棵互不相交的树的集合,如上图,去掉根结点A,其原来的二棵子树T1、T2、T3的集合{T1,T2,T3}就为森林; 4.有序树——指树中同层结点从左到右有次序排列,它们之间的次序不能互换,这样的树称为有序树,否则称为无序树。 5.树的表示 树的表示方法有许多,常用的方法是用括号:先将根结点放入一对圆括号中,然后把它的子树由左至右的顺序放入括号中,而对子树也采用同样的方法处理;同层子树与它的根结点用圆括号括起来,同层子树之间用逗号隔开,最后用闭括号括起来。如上图可写成如下形式: (A(B(E(K,L),F),C(G),D(H(M),I,J))) 5. 2 二叉树 1.二叉树的基本形态: 二叉树也是递归定义的,其结点有左右子树之分,逻辑上二叉树有五种基本形态: (1)空二叉树——(a); (2)只有一个根结点的二叉树——(b); (3)右子树为空的二叉树——(c); (4)左子树为空的二叉树——(d); (5)完全二叉树——(e) 注意:尽管二叉树与树有许多相似之处,但二叉树不是树的特殊情形。 2.两个重要的概念: (1)完全二叉树——只有最下面的两层结点度小于2,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树; (2)满二叉树——除了叶结点外每一个结点都有左右子女且叶结点都处在最底层的二叉树,。 如下图: 完全二叉树 1页
一、一、单选题(每题 2 分,共20分) 1. 1.对一个算法的评价,不包括如下()方面的内容。 A.健壮性和可读性B.并行性C.正确性D.时空复杂度 2. 2.在带有头结点的单链表HL中,要向表头插入一个由指针p指向的结点,则执 行( )。 A. p->next=HL->next; HL->next=p; B. p->next=HL; HL=p; C. p->next=HL; p=HL; D. HL=p; p->next=HL; 3. 3.对线性表,在下列哪种情况下应当采用链表表示?( ) A.经常需要随机地存取元素 B.经常需要进行插入和删除操作 C.表中元素需要占据一片连续的存储空间 D.表中元素的个数不变 4. 4.一个栈的输入序列为1 2 3,则下列序列中不可能是栈的输出序列的是( ) A. 2 3 1 B. 3 2 1 C. 3 1 2 D. 1 2 3 5.5.AOV网是一种()。 A.有向图B.无向图C.无向无环图D.有向无环图 6. 6.采用开放定址法处理散列表的冲突时,其平均查找长度()。 A.低于链接法处理冲突 B. 高于链接法处理冲突 C.与链接法处理冲突相同D.高于二分查找 7.7.若需要利用形参直接访问实参时,应将形参变量说明为()参数。 A.值B.函数C.指针D.引用 8.8.在稀疏矩阵的带行指针向量的链接存储中,每个单链表中的结点都具有相同的 ()。 A.行号B.列号C.元素值D.非零元素个数 9.9.快速排序在最坏情况下的时间复杂度为()。 A.O(log2n) B.O(nlog2n) C.0(n) D.0(n2) 10.10.从二叉搜索树中查找一个元素时,其时间复杂度大致为( )。 A. O(n) B. O(1) C. O(log2n) D. O(n2) 二、二、运算题(每题 6 分,共24分) 1. 1.数据结构是指数据及其相互之间的______________。当结点之间存在M对N(M:N)的联系时,称这种结构为_____________________。 2. 2.队列的插入操作是在队列的_________进行,删除操作是在队列的__________进行。 3. 3.当用长度为N的数组顺序存储一个栈时,假定用top==N表示栈空,则表示栈满
数据结构课程设计 一、引言 数据结构是一门理论性强、思维抽象、难度较大的课程,是基础课和专业课之间的桥梁。该课程的先行课程是计算机基础、程序设计语言、离散数学等,后续课程有操作系统、编译原理、数据库原理、软件工程等。通过本门课程的学习,我们应该能透彻地理解各种数据对象的特点,学会数据的组织方法和实现方法,并进一步培养良好的程序设计能力和解决实际问题的能力。 数据结构是计算机科学与技术专业的一门核心专业基础课程,在该专业的课程体系中起着承上启下的作用,学好数据结构对于提高理论认知水平和实践能力有着极为重要的作用。学习数据结构的最终目的是为了获得求解问题的能力。对于现实世界中的问题,应该能从中抽象出一个适当的数学模型,该数学模型在计算机内部用相应的数据结构来表示,然后设计一个解此数学模型的算法,再进行编程调试,最后获得问题的解答。 实习课程是为了加强编程能力的培养,鼓励学生使用新兴的编程语言。相信通过数据结构课程实践,无论是理论知识,还是实践动手能力,我们都会有不同程度上的提高。 二、课程设计目的 本课程是数据结构课程的实践环节。主要目的在于加强学生在课程中学习的相关算法和这些方法的具体应用,使学生进一步掌握在C++或其他语言中应用这些算法的能力。通过课程设计题目的练习,强化学生对所学知识的掌握及对问题分析和任务定义的理解。
三、内容设计要求 二叉排序树的实现: 用顺序和二叉链表作存储结构 1)以回车(…\n?)为输入结束标志,输入数列L,生成一棵二叉排序树T; 2)对二叉排序树T作中序遍历,输出结果; 3)输入元素x,查找二叉排序树T,若存在含x的结点,则删除该结点,并作中序遍历(执行操作2);否则输出信息“无x”。 (一)问题分析和任务定义 对问题的描述应避开具体的算法和涉及的数据结构,它是对要完成的任务作出明确的回答,强调的是做什么,而不是怎么做。 (二)详细的设计和编码 算法的具体描述和代码的书写。 (三)上机调试 源程序的输入和代码的调试。 要求:设计中要求综合运用所学知识,上机解决一些与实际应用结合紧密的、规模较大的问题,通过分析、设计、编码、调试等各环节的训练,深刻理解、牢固的掌握数据结构和算法设计技术,掌握分析、解决实际问题的能力。 四、源代码 1、用二叉链表存储结构实现 #include
6.5 二叉排序树★3◎4 1.二叉排序树定义 二叉排序树(Binary Sort Tree)或者是一棵空树;或者是具有下列性质的二叉树:(1)若左子树不空,则左子树上所有结点的值均小于根结点的值;若右子树不空,则右子树上所有结点的值均大于根结点的值。 (2)左右子树也都是二叉排序树,如图6-2所示。 2.二叉排序树的查找过程 由其定义可见,二叉排序树的查找过程为: (1)若查找树为空,查找失败。 (2)查找树非空,将给定值key与查找树的根结点关键码比较。 (3)若相等,查找成功,结束查找过程,否则: ①当给值key小于根结点关键码,查找将在以左孩子为根的子树上继续进行,转(1)。 ②当给值key大于根结点关键码,查找将在以右孩子为根的子树上继续进行,转(1)。 3.二叉排序树插入操作和构造一棵二叉排序树 向二叉排序树中插入一个结点的过程:设待插入结点的关键码为key,为将其插入,先要在二叉排序树中进行查找,若查找成功,按二叉排序树定义,该插入结点已存在,不用插入;查找不成功时,则插入之。因此,新插入结点一定是作为叶子结点添加上去的。构造一棵二叉排序树则是逐个插入结点的过程。对于关键码序列为:{63,90,70,55,67,42,98,83,10,45,58},则构造一棵二叉排序树的过程如图6-3所示。 4.二叉排序树删除操作 从二叉排序树中删除一个结点之后,要求其仍能保持二叉排序树的特性。 设待删结点为*p(p为指向待删结点的指针),其双亲结点为*f,删除可以分三种情况,如图6-4所示。
(1)*p结点为叶结点,由于删去叶结点后不影响整棵树的特性,所以,只需将被删结点的双亲结点相应指针域改为空指针,如图6-4(a)所示。 (2)*p结点只有右子树或只有左子树,此时,只需将或替换*f结点的*p子树即可,如图6-4(b)、(c)所示。 (3)*p结点既有左子树又有右子树,可按中序遍历保持有序地进行调整,如图6-4(d)、(e)所示。 设删除*p结点前,中序遍历序列为: ① P为F的左子女时有:…,Pi子树,P,Pj,S子树,Pk,Sk子树,…,P2,S2子树,P1,S1子树,F,…。 ②P为F的右子女时有:…,F,Pi子树,P,Pj,S子树,Pk,Sk子树,…,P2,S2子树,P1,S1子树,…。 则删除*p结点后,中序遍历序列应为: ①P为F的左子女时有:…,Pi子树,Pj,S子树,Pk,Sk子树,…,P2,S2子树,P1,S1子树,F,…。 ② P为F的右子女时有:…,F,Pi子树,Pj,S子树,Pk,Sk子树,…,P2,S2子树,