
统计数据的描述性分析 一、实验目的 熟悉在matlab中实现数据的统计描述方法,掌握基本统计命令:样本均值、样本中位数、样本标准差、样本方差、概率密度函数pdf、概率分布函数df、随机数生成rnd。 二、实验内容 1 、频数表和直方图 数据输入,将你班的任意科目考试成绩输入 >> data=[91 78 90 88 76 81 77 74]; >> [N,X]=hist(data,5) N = 3 1 1 0 3 X = 75.7000 79.1000 82.5000 85.9000 89.3000 >> hist(data,5)
2、基本统计量 1) 样本均值 语法: m=mean(x) 若x 为向量,返回结果m是x 中元素的均值; 若x 为矩阵,返回结果m是行向量,它包含x 每列数据的均值。 2) 样本中位数 语法: m=median(x) 若x 为向量,返回结果m是x 中元素的中位数; 若x 为矩阵,返回结果m是行向量,它包含x 每列数据的中位数3) 样本标准差 语法:y=std(x) 若x 为向量,返回结果y 是x 中元素的标准差; 若x 为矩阵,返回结果y 是行向量,它包含x 每列数据的标准差
std(x)运用n-1 进行标准化处理,n是样本的个数。 4) 样本方差 语法:y=var(x); y=var(x,1) 若x 为向量,返回结果y 是x 中元素的方差; 若x 为矩阵,返回结果y 是行向量,它包含x 每列数据的方差 var(x)运用n-1 进行标准化处理(满足无偏估计的要求),n 是样本的个数。var(x,1)运用n 进行标准化处理,生成关于样本均值的二阶矩。 5) 样本的极差(最大之和最小值之差) 语法:z= range(x) 返回结果z是数组x 的极差。 6) 样本的偏度 语法:s=skewness(x) 说明:偏度反映分布的对称性,s>0 称为右偏态,此时数据位于均值右边的比左边的多;s<0,情况相反;s 接近0 则可认为分布是对称的。 7) 样本的峰度 语法:k= kurtosis(x) 说明:正态分布峰度是3,若k 比3 大得多,表示分布有沉重的尾巴,即样本中含有较多远离均值的数据,峰度可以作衡量偏离正态分布的尺度之一。 >> mean(data) ,
第7章 MATLAB数据分析与多项式计算 6.1 数据统计处理 6.2 数据插值 6.3 曲线拟合 6.4 离散傅立叶变换 6.5 多项式计算 6.1 数据统计处理 6.1.1 最大值和最小值 MATLAB提供的求数据序列的最大值和最小值的函数分别为max 和min,两个函数的调用格式和操作过程类似。 1.求向量的最大值和最小值 求一个向量X的最大值的函数有两种调用格式,分别是: (1) y=max(X):返回向量X的最大值存入y,如果X中包含复数元素,则按模取最大值。 (2) [y,I]=max(X):返回向量X的最大值存入y,最大值的序号存入I,如果X中包含复数元素,则按模取最大值。 求向量X的最小值的函数是min(X),用法和max(X)完全相同。 例6-1 求向量x的最大值。 命令如下: x=[-43,72,9,16,23,47]; y=max(x) %求向量x中的最大值 [y,l]=max(x) %求向量x中的最大值及其该元素的位置 2.求矩阵的最大值和最小值 求矩阵A的最大值的函数有3种调用格式,分别是: (1) max(A):返回一个行向量,向量的第i个元素是矩阵A的第i 列上的最大值。 (2) [Y,U]=max(A):返回行向量Y和U,Y向量记录A的每列的最大值,U向量记录每列最大值的行号。 (3) max(A,[],dim):dim取1或2。dim取1时,该函数和max(A)完全相同;dim取2时,该函数返回一个列向量,其第i个元素是A矩阵的第i行上的最大值。 求最小值的函数是min,其用法和max完全相同。
例6-2 分别求3×4矩阵x中各列和各行元素中的最大值,并求整个矩阵的最大值和最小值。 3.两个向量或矩阵对应元素的比较 函数max和min还能对两个同型的向量或矩阵进行比较,调用格式为: (1) U=max(A,B):A,B是两个同型的向量或矩阵,结果U是与A,B 同型的向量或矩阵,U的每个元素等于A,B对应元素的较大者。 (2) U=max(A,n):n是一个标量,结果U是与A同型的向量或矩阵,U的每个元素等于A对应元素和n中的较大者。 min函数的用法和max完全相同。 例6-3 求两个2×3矩阵x, y所有同一位置上的较大元素构成的新矩阵p。 6.1.2 求和与求积 数据序列求和与求积的函数是sum和prod,其使用方法类似。设X是一个向量,A是一个矩阵,函数的调用格式为: sum(X):返回向量X各元素的和。 prod(X):返回向量X各元素的乘积。 sum(A):返回一个行向量,其第i个元素是A的第i列的元素和。 prod(A):返回一个行向量,其第i个元素是A的第i列的元素乘积。 sum(A,dim):当dim为1时,该函数等同于sum(A);当dim为2时,返回一个列向量,其第i个元素是A的第i行的各元素之和。 prod(A,dim):当dim为1时,该函数等同于prod(A);当dim为2时,返回一个列向量,其第i个元素是A的第i行的各元素乘积。 例6-4 求矩阵A的每行元素的乘积和全部元素的乘积。 6.1.3 平均值和中值 求数据序列平均值的函数是mean,求数据序列中值的函数是median。两个函数的调用格式为: mean(X):返回向量X的算术平均值。 median(X):返回向量X的中值。
数据包络分析法 在高新技术产业技术创新教育财务绩效评价中的应用 姓名:李雪 专业:会计学 学号:201410750244
数据包络分析法 在高新技术产业创新教育财务绩效评价中的应用 摘要:高新技术产业是个技术密集型产业,对知识和技术具有很强的依赖性,进行技术创新活动是其经济高质量增长的源泉。高新技术产业创新教育财务管理内外环境的变化让财务绩效评价不仅成为可能,而且成为了高新技术产业财务管理必需推进的工作。财务绩效评价是运用科学、规范的绩效评价方法,对照一定的评价标准,参照绩效的内在原则,来对高新技术产业创新教育财务行为过程及结果进行客观、公正、科学的综合评价和衡量比较。高新技术产业财务绩效评价已成为高新技术产业财务管理的主要内容之一,对财务管理工作的促进和完善起着重要作用。数据包络分析法通过客观地反映高新技术产业创新教育活动的输入、输出,兼具考虑所选择指标的可采集性等约束条件,并且采用相对最优的权重确定方法反映财务绩效大小,蕴含着经济学的生产力观点,满足了财务绩效评价的科学性。 关键词:高新技术产业创新教育;财务绩效评价;数据包络分析法 技术创新对企业来讲可以优化产品结构,提高产品的价值,快速适应市场的需求,从而增强企业的市场竞争力;对于一个产业来说,技术创新可以催发新兴产业群的成长,推进产业结构优化,提高技术产业的经济效益。技术创新已经成为高质量经济增长的源泉。高新技术产业技术创新是指在市场的导向作用下,以提高产业效益为目标,经过技术的研发、引进、吸收等一系列的技术活动,生产出新产品、研发出新技术的过程。高新技术产业技术创新绩效,是对高新技术产业应用投入的财力和物力研发出新产品、新工艺,从而产生经济效益的能力的考核,是评判经济技术活动有效性的一个有效手段。因此,正确认识和把握技术创新水平、系统总结技术创新经验是很有必要的。科学评价高技术产业的技术创新绩效,对把握高新技术产业的技术创新活动规律、提升技术创新成功率、推动高新技术产业技术创新活动有序发展具有重要的现实意义。
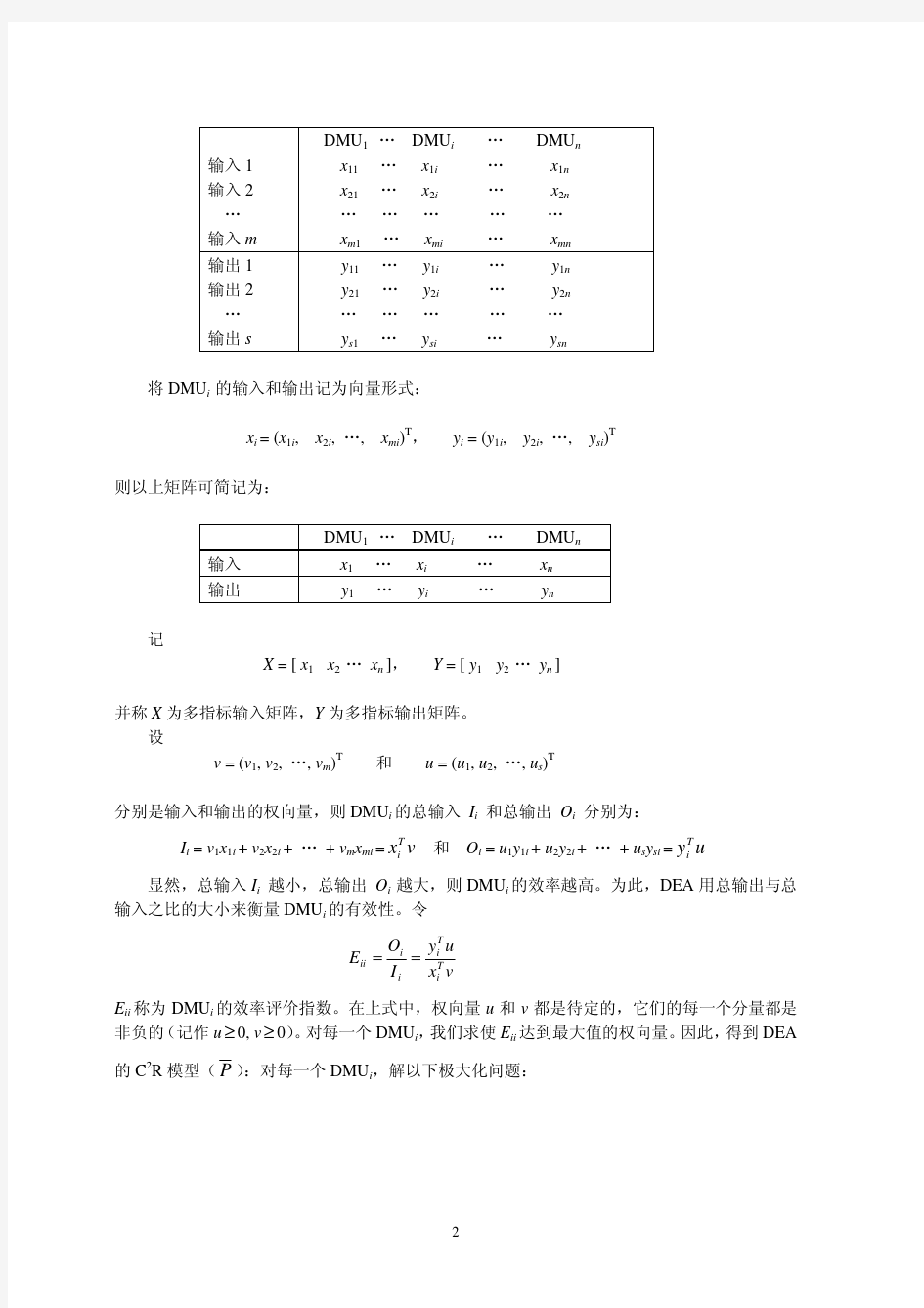
二、 数据包络分析(DEA)方法 数据包络分析(data envelopment analysis, DEA)是由著名运筹学家Charnes, Cooper 和Rhodes 于1978年提出的,它以相对效率概念为基础,以凸分析和线性规划为工具,计算比较具有相同类型的决策单元(Decision making unit ,DMU)之间的相对效率,依此对评价对象做出评价[1]。DEA 方法一出现,就以其独特的优势而受到众多学者的青睐,现已被应用于各个领域的绩效评价中[2],[3]。在介绍DEA 方法的原理之前,先介绍几个基本概念: 1. 决策单元 一个经济系统或一个生产过程都可以看成是一个单位(或一个部门)在一定可能围,通过投入一定数量的生产要素并产出一定数量的“产品”的活动。虽然这种活动的具体容各不相同,但其目的都是尽可能地使这一活动取得最大的“效益”。由于从“投入”到“产出”需要经过一系列决策才能实现,或者说,由于“产出”是决策的结果,所以这样的单位(或部门)被称为决策单元(DMU)。因此,可以认为,每个DMU(第i 个DMU 常记作DMU i )都表现出一定的经济意义,它的基本特点是具有一定的投入和产出,并且将投入转化成产出的过程中,努力实现自身的决策目标。 在许多情况下,我们对多个同类型的DMU 更感兴趣。所谓同类型的DMU ,是指具有以下三个特征的DMU 集合:具有相同的目标和任务;具有相同的外部环境;具有相同的投入和产出指标。 2. 生产可能集 设某个DMU 在一项经济(生产)活动中有m 项投入,写成向量形式为1(,,)T m x x x =L ;产出有s 项,写成向量形式为1(,,)T s y y y =L 。于是我们可以用(,)x y 来表示这个DMU 的整个生产活动。 定义1. 称集合{(,)|T x y y x =产出能用投入生产出来}为所有可能的生产活动构成的生产可能集。 在使用DEA 方法时,一般假设生产可能集T 满足下面四条公理: 公理1(平凡公理): (,),1,2,,j j x y T j n ∈=L 。 公理2(凸性公理): 集合T 为凸集。 如果 (,),1,2,,j j x y T j n ∈=L , 且存在 0j λ≥ 满足 1 1n j j λ==∑ 则 11(,)n n j j j j j j x y T λλ==∈∑∑。 公理3(无效性公理):若()??,,,x y T x x y y ∈≥≤,则??(,)x y T ∈。 , 公理4 (锥性公理): 集合T 为锥。如果(),x y T ∈那么 (,)kx ky T ∈对任意的0k >。 若生产可能集T是所有满足公理1 , 2 , 3和4的最小者,则T 有如下的唯一表示形式 ()11 ,|, ,0,1,2,,n n j j j j j j j T x y x x y y j n λλ λ==? ? =≤≥≥=??? ? ∑∑L 。 3. 技术有效与规模收益
数据包络分析方法介绍和应用综述 【摘要】数据包络分析(Data Envelopment Analysis,DEA)是一种基于线性规划理论的模型,它将多输入指标和多输出指标综合成为单个评价指标,是运筹学、管理科学和数理经济学交叉研究的一个新的领域。数据包络分析使用数学规划评价具有多个输入与输出的决策单元(简记为DMU)间的相对有效性(DEA 有效), 使用DEA对DMU进行效率评价时, 可以得到很多在经济学中具有深刻经济含义和背景的管理信息。本综述的目的是介绍DEA研究的历史、现状, 特别是它的发展过程及某些新的模型扩展,同时综合阐述了DEA在生产、管理、商务中的广泛应用和它的发展趋势。 关键词:数据包络分析模型结构决策单元发展以及应用趋势 一、数据包络分析(DEA)概念及模型简介 1、概念 数据包络分析(Data Envelopment Analysis,DEA)是运筹学、管理科学和数理经济学交叉研究的一个新的领域。1978年由著名的运筹学家A.Charnes,W.W.Cooper和E.Rhodes首先提出了一个被称为数据包络分析(Data Envelopment Analysis,简称DEA)的方法,主要用来评价生产中各个部门间的相对有效性(因此被称为DEA有效)。我国自1988 年由魏权龄①系统地介绍DEA 方法之后, 先后也有不少关于DEA 方法理论研究及应用推广的论文问世。 其中,比较全面的一篇论文是《系统工程理论和方法应用》1994年3卷第4期,东南大学经济管理学院的朱乔的《数据包络分析方法综述与展望》,指出“据国外统计已经有400余篇关于DEA的研究论文、工作报告或者学术论文可查,例如:Annals of Operational Research(1985)、European Journal of Operational Research(1992)、Journal of Productivity Analysis(1992)等等,还有近期为了悼念A.Charnes,W.W.Cooper教授,Annals of Operational Research还专门出版了“从有效性计算到组织和分析数据的新方法---DEA方法15年”的专刊。” 中国人民大学教授魏全龄,在《评价相对有效性的DEA 方法———运筹学的新领域》一文中系统地介绍了DEA的方法,指出数据包络分析(Data Envelopment Analysis,DEA)是一种基于线性规划理论的模型,它将多输入指标和多输出指标综合成为单个评价指标。 在此基础上,李美娟, 陈国宏2003年在《数据包络分析法(DEA) 的研究与应用》中指出DEA 方法以相对效率概念为基础, 用于评价具有相同类型的多投入、多产出的决策单元是否技术有效的一种非参数统计方法,并且对DEA的基本思路进行了详细阐述。 经过各方面的努力,可见数据包络分析(Data Envelopment Analysis,DEA)是一种基于线性规划理论的模型,它将多输入指标和多输出指标综合成为单个评价指标,其基本思路是把每一个被评价单位作为一个决策单元(DMU ,decision making unit s) , 再由众多DMU 构成被评价群体, 通过对投入和产出比率的综合分析, 以DMU 的各个投入和产出指标的权重为变量进行评价运算, 确定有效生产前沿面, 并根据各DMU 与有效生产前沿面的距离状况, 确定各DMU 是否DEA 有效, 同时还可用投影方法指出非DEA 有效或弱DEA 有效DMU 的原因及应改进的方向和程度。 2、模型简介 A.Charnes,W.W.Cooper和E.Rhodes在1978年提出的第一个模型被命名为CCR模型,从生产函数角度看,这一模型是用来研究具有多个输入、特别是具有多个输出的“生产部门” ①魏全龄:中国人民大学信息系教授,先后出版了数十篇关于DEA的发展及应用方面的文章,科研成果显著。
使用Matlab对采样数据进行频谱分析 1、采样数据导入Matlab 采样数据的导入至少有三种方法。 第一就是手动将数据整理成Matlab支持的格式,这种方法仅适用于数据量比较小的采样。 第二种方法是使用Matlab的可视化交互操作,具体操作步骤为:File --> Import Data,然后在弹出的对话框中找到保存采样数据的文件,根据提示一步一步即可将数据导入。这种方法适合于数据量较大,但又不是太大的数据。据本人经验,当数据大于15万对之后,读入速度就会显著变慢,出现假死而失败。 第三种方法,使用文件读入命令。数据文件读入命令有textread、fscanf、load 等,如果采样数据保存在txt文件中,则推荐使用 textread命令。如 [a,b]=textread('data.txt','%f%*f%f'); 这条命令将data.txt中保存的数据三个三个分组,将每组的第一个数据送给列向量a,第三个数送给列向量b,第二个数据丢弃。命令类似于C语言,详细可查看其帮助文件。文件读入命令录入采样数据可以处理任意大小的数据量,且录入速度相当快,一百多万的数据不到20秒即可录入。强烈推荐! 2、对采样数据进行频谱分析 频谱分析自然要使用快速傅里叶变换FFT了,对应的命令即 fft ,简单使用方法为:Y=fft(b,N),其中b即是采样数据,N为fft数据采样个数。一般不指定N,即简化为Y=fft(b)。Y即为FFT变换后得到的结果,与b的元素数相等,为复数。以频率为横坐标,Y数组每个元素的幅值为纵坐标,画图即得数据b的幅频特性;以频率为横坐标,Y数组每个元素的角度为纵坐标,画图即得数据b的相频特性。典型频谱分析M程序举例如下: clc fs=100; t=[0:1/fs:100]; N=length(t)-1;%减1使N为偶数 %频率分辨率F=1/t=fs/N p=1.3*sin(0.48*2*pi*t)+2.1*sin(0.52*2*pi*t)+1.1*sin(0.53*2*pi*t)... +0.5*sin(1.8*2*pi*t)+0.9*sin(2.2*2*pi*t); %上面模拟对信号进行采样,得到采样数据p,下面对p进行频谱分析 figure(1) plot(t,p); grid on title('信号 p(t)'); xlabel('t') ylabel('p')
Enhance the initiative and predictability of work safety, take precautions, and comprehensively solve the problems of work safety. (安全管理) 单位:___________________ 姓名:___________________ 日期:___________________ 基于数据包络分析的城市燃气供 需预警研究(2021)
基于数据包络分析的城市燃气供需预警研究 (2021) 导语:根据时代发展的要求,转变观念,开拓创新,统筹规划,增强对安全生产工作的主动性和预见性,做到未雨绸缪,综合解决安全生产问题。文档可用作电子存档或实体印刷,使用时请详细阅读条款。 摘要:建立天然气供需预警协调机制是保证经济可持续发展的根本保障。利用数据包络分析(DEA)方法处理多输入和多输出这种问题的优势,将数据包络分析(DEA)方法引入城市天然气供需预警协调系统中。以重庆市为例,分析了指标选取的依据,用FrontierAnalyst3软件对重庆市近几年每个季度天然气供需的安全性做了实证分析,并对建立的供需预警协调系统进行评价。通过分析可知,DEA模型不但能正确并且准确预报天然气供给的情况,还能对非有效的决策单元中的指标进行协调,可对未来天然气规划做出科学指导。 主题词:城市;天然气;供需关系;安全;预测;效率;评价;线性规划 重庆市每逢冬季用气高峰,天然气供应非常紧张,等待加气的各种车辆排成长龙。出现这些情况除了供应方面存在问题外,还与重庆市政府没有系统地建立对天然气市场供应预警协调的长效机制有关。
(1)数据包络分析法(DEA)概述 数据包络分析(Data Envelopment Ana lysis,简称D EA)方法是运用数学工具评价经济系统生产前沿面有效性的非参数方法,它适应用于多投入多产出的多目标决策单元的绩效评价。这种方法以相对效率为基础,根据多指标投入与多指标产出对相同类型的决策单元进行相对有效性评价。应用该方法进行绩效评价的另一个特点是,它不需要以参数形式规定生产前沿函数,并且允许生产前沿函数可以因为单位的不同而不同,不需要弄清楚各个评价决策单元的输入与输出之间的关联方式,只需要最终用极值的方法,以相对效益这个变量作为总体上的衡量标准,以决策单元(DM U)各输入输出的权重向量为变量,从最有利于决策的角度进行评价,从而避免了人为因素确定各指标的权重而使得研究结果的客观性收到影响。这种方法采用数学规划模型,对所有决策单元的输出都“一视同仁”。这些输入输出的价值设定与虚拟系数有关,有利于找出那些决策单元相对效益偏低的原因。该方法以经验数据为基础,逻辑上合理,故能够衡量个决策单元由一定量大投入产生预期的输出的能力,并且能够计算在非DEA有效的决策单元中,投入没有发挥作用的程度。最为重要的是应用该方法还有可能进一步估计某个决策单元达到相对有效时,其产出应该增加多少,输入可以减少多少等。 1978年由著名的运筹学家查恩斯(A.Charnes),库伯(W.W.Cooper)和罗兹(E.Rhodes)首先提出数据包络分析(Data Envelopment Analysis,简称DEA)的方法,DEA有效性的评价是对已
有决策单元绩效的比较评价,属于相对评价,它常常被用来评价部门间的相对有效性(又称之为DEA有效)。他们的第一个数学模型被命名为CCR模型,又称为模型。从生产函数角度看,这一模型是用来研究具有多项输入、特别是具有多项输出的“生产部门”时衡量其“规模有效”和“技术有效”较为方便而且是卓有成效的一种方法和手段。自从该方法提出以来,就广泛应用于各个行业的有效性评价上。此后,得到不断的完善,并且在实践中的应用也越来越广泛。例如1984年R.D.Banker, A.Charnes和W.W.Cooper给出了一个被称为BCC的模型,又称之为BC2模型。另外,于1985年Charnes,Cooper 和 B.Golany, L.Seiford, J.Stutz给出了另一个模型,称为CCGSS模型,又称之为C2GS2模型,这两个模型是用来研究生产部门之间的“技术有效”相对效率。下面将介绍这两个优化模型。 ( 2 ) 数据包络模型(又称为DEA模型)描述 数据包络分析(DEA)由美国著名运筹学家A. Charnes等人在1978年以相对效率概念为基础发展起来的一种新的绩效评价方法。这种方法是以决策单元(Decision Making Unit,简称DMU)的投入、产出指标的权重系数为变量,借助于数学规划模型将决策单元投影到DEA 生产前沿面上,通过比较决策单元偏离DEA生产前沿面的程度来对被评价决策单元的相对有效性进行综合绩效评价。其基本思路是:通过对投入产出数据的综合分析,得出每个DMU综合相对效率的数量指标,确定各DMU是否为DEA有效。下面我们先描述DEA模型。
Matlab大数据处理2:硬盘访问.mat文件 分类:Matlab Hack2013-09-08 20:16 146人阅读评论(0) 收藏举报Matlab程序中经常要访问.mat文件,通常在作法是用load函数直接加载.mat文件。如果.mat文件非常大,超过了系统可用内存的时候该怎么办呢?Matlab2013b为提供了matfile函数,matfile函数可以通过索引直接访问.mat文件中的Matlab变量,而无需将.mat文件加载入内存。 matfile有两种用法: m = matfile(filename),用文件名创建matfile对象,通过这个对象可以直接访问mat文件中的matlab变量。 m = matfile(filename,'Writable',isWritable),isWritable开启或关闭文件写操作。 使用示例: 1. 向mat文件中写入变量 x = magic(20); m = matfile('myFile.mat'); % 创建一个指向myFile.mat的matfile对象 m.x = x; % 写入x m.y(81:100,81:100) = magic(20); % 使用坐标索引
2. 加载变量 filename = 'topography.mat'; m = matfile(filename); topo = m.topo; %读取变量topo [nrows,ncols] = size(m,'stocks'); %读取stocks变量的size avgs = zeros(1,ncols); for idx = 1:ncols avgs(idx) = mean(m.stocks(:,idx)); end 3. 开启写权限 filename = 'myFile.mat'; m = matfile(filename,'Writable',true); 或者 m.Properties.Writable = true;
第6章 MATLAB数据分析与多项式计算 习题6 一、选择题 1.设A=[1,2,3,4,5;3,4,5,6,7],则min(max(A))的值是()。B A.1 B.3 C.5 D.7 2.已知a为3×3矩阵,则运行mean(a)命令是()。B A.计算a每行的平均值 B.计算a每列的平均值 C.a增加一行平均值 D.a增加一列平均值 3.在MATLAB命令行窗口输入下列命令: >> x=[1,2,3,4]; >> y=polyval(x,1); 则y的值为()。 D A.5 B.8 C.24 D.10 4.设P是多项式系数向量,A为方阵,则函数polyval(P,A)与函数polyvalm(P,A)的值()。D A.一个是标量,一个是方阵 B.都是标量 C.值相等 D.值不相等 5.在MATLAB命令行窗口输入下列命令: >> A=[1,0,-2]; >> x=roots(A); 则x(1)的值为()。 C A.1 B.-2 C. D. 6.关于数据插值与曲线拟合,下列说法不正确的是()。A A.3次样条方法的插值结果肯定比线性插值方法精度高。 B.插值函数是必须满足原始数据点坐标,而拟合函数则是整体最接近原始数据点,而不一定要必须经过原始数据点。 C.曲线拟合常常采用最小二乘原理,即要求拟合函数与原始数据的均方误差达到极小。 D.插值和拟合都是通过已知数据集来求取未知点的函数值。 二、填空题 1.设A=[1,2,3;10 20 30;4 5 6],则sum(A)= ,median(A)= 。 [15 27 39],[4 5 6[ 2.向量[2,0,-1]所代表的多项式是。2x2-1 3.为了求ax2+bx+c=0的根,相应的命令是(假定a、b、c已经赋值)。为了
DEA 一、同类可比 同类可比在很多情况下是社科研究的基础和前提,比如研究地区效率,西藏、新疆、青海等地与上海、北京、广东、江苏等经济发达地区情况完全不一样,在很多情况下是不可比的,如果将这些地区放在一个模型中分析,是值得商榷的。 二、DEA对异常值相当敏感 DEA对异常值相当敏感,在实际生活中,由于统计数据质量、测量误差等问题,构成数据包络曲线的那些点是非常敏感的,或者说,其它效率不是最优的点都是和数据包络曲线上最好的点相比,而这些点其实是不稳定的,在此基础上得出的处理结果也是不稳定的。 三、DEA也许只有宏观意义 即使是同一套数据,如果同时满足固定前沿和随机前沿的适用条件。采用固定前沿和随机前言,其分析结果往往是不一致的,也就是说,对于决策单元A,采用固定前沿它可能是有效的,但采用随机前 沿它可能就是无效的。那么能否说明DEA在做文字游戏也不能这么说,通常情况下,对于同一套数据采用两种不同方法处理的结果,其相关性往往很高,因此适合做宏观分析,但微观上说A有效B无效之类的要慎重。 四、DEA往往难以给出具体的政策建议 即使得出了研究结果,对于一些效率相对低下的决策单元,如何进行改进通过技术进步还是通过改善管理再进一步的建议往往难以给出。 五、效率低下的决策单元也许问题不严重 任何DEA分析,都是建立在投入产出的基础之上的,但是投入产出数据有很多是无法定量计量的。实际上,DEA分析有个隐含的假设:我们做效率分析,只能基于定量数据,那些不能定量计量的投入产出,干脆假设所有的决策单位没有差异,但这种假设一定存在吗 纯技术效率反映的是DMU 在一定( 最优规模时) 投入要素的生产效率。 规模效率反映的是实际规模与最优生产规模的差距。 一般认为:综合技术效率=纯技术效率×规模效率。
DEA(Data Envelopment Analysis)数据包络分析 目录 一、DEA的起源与发展(参考网络等相关文献) 二、基本概念 1.决策单元(Decision Making Unit,DMU).......................................................... 2.生产可能集(Production Possibility Set,PPS) ................................................ 3.生产前沿面(Production Frontier)........................................................................ 4.效率(Efficiency) ........................................................................................................ 三、模型 模型....................................................................................................................................... 模型....................................................................................................................................... 模型....................................................................................................................................... 模型....................................................................................................................................... 5.加性模型(additive model,简称ADD).................................................................... 6.基于松弛变量的模型(Slacks-based.................................. M easure,简称SBM) 7.其他模型........................................................................................................................... 四、指标选取 五、DEA的步骤(参考于网络) 六、优缺点(参考一篇博客) 七、非期望产出 1.非期望产出的处理方法:.............................................................................................. 2.非期望产出的性质: ......................................................................................................
实验一数据处理方法的MATLAB实现 一、实验目的 学会在MATLAB环境下对已知的数据进行处理。 二、实验方法 1. 求取数据的最大值或最小值。 2. 求取向量的均值、标准方差和中间值。 3.在MATLAB环境下,对已知的数据分别进行曲线拟合和插值。 三、实验设备 1.586以上微机,16M以上内存,400M硬盘空间,2X CD-ROM 2.MATLAB5.3以上含CONTROL SYSTEM TOOLBOX。 四、实验内容 1.在MATLAB环境下,利用MATLAB控制系统工具箱中的函数直接求取数据的最大值或最小值,以及向量的均值、标准方差和中间值。 2.在MATLAB环境下,选择合适的曲线拟合和插值方法,编写程序,对已知的数据分别进行曲线拟合和插值。 五、实验步骤 1. 在MATLAB环境下,将已知的数据存到数据文件mydat.mat中。 双击打开Matlab,在命令窗口(command window)中,输入一组数据:实验一数据处理方法的MATLAB实现 一、实验目的 学会在MATLAB环境下对已知的数据进行处理。 二、实验方法 1. 求取数据的最大值或最小值。 2. 求取向量的均值、标准方差和中间值。 3.在MATLAB环境下,对已知的数据分别进行曲线拟合和插值。 三、实验设备 1.586以上微机,16M以上内存,400M硬盘空间,2X CD-ROM 2.MATLAB5.3以上含CONTROL SYSTEM TOOLBOX。 四、实验内容
1.在MATLAB环境下,利用MATLAB控制系统工具箱中的函数直接求取数据的最大值或最小值,以及向量的均值、标准方差和中间值。 2.在MATLAB环境下,选择合适的曲线拟合和插值方法,编写程序,对已知的数据分别进行曲线拟合和插值。 五、实验步骤 1. 在MATLAB环境下,将已知的数据存到数据文件mydat.mat中。 双击打开Matlab,在命令窗口(command window)中,输入一组数据: x=[1,4,2,81,23,45] x = 1 4 2 81 2 3 45 单击保存按钮,保存在Matlab指定目录(C:\Program Files\MATLAB71)下,文件名为“mydat.mat”。 2. 在MATLAB环境下,利用MATLAB控制系统工具箱中的函数直接求取数据的最大值或最小值,以及向量的均值、标准方差和中间值。 继续在命令窗口中输入命令: (1)求取最大值“max(a)”; >> max(x) ans = 81 (2)求取最小值“min(a)”; >> min(x) ans = 1 (3)求取均值“mean(a)”; >> mean(x) ans =
一、数据包络分析法 数据包络分析是一种基于线性规划的用于评价同类型组织(或项目)工作绩效相对有效性的特殊工具手段。这类组织例如学校、医院、银行的分支机构、超市的各个营业部等,各自具有相同(或相近)的投入和相同的产出。衡量这类组织之间的绩效高低,通常采用投入产出比这个指标,当各自的投入产出均可折算成同一单位计量时,容易计算出各自的投入产出比并按其大小进行绩效排序。但当被衡量的同类型组织有多项投入和多项产出,且不能折算成统一单位时,就无法算出投入产出比的数值。例如,大部分机构的运营单位有多种投入要素,如员工规模、工资数目、运作时间和广告投入,同时也有多种产出要素,如利润、市场份额和成长率。在这些情况下,很难让经理或董事会知道,当输入量转换为输出量时,哪个运营单位效率高,哪个单位效率低。 1.1 数据包络分析法的主要思想一个经济系统或者一个生产过程可以看成一个单元在一定可能范围内,通过投入一定数量的生产要素并产出一定数量的“产品” 的活动。虽然这些活动的具体内容各不相同,但其目的都是尽可能地使这一活动取得最大的“效益” 。由于从“投入”到“产出”需要经过一系列决策才能实现,或者说,由于“产出”是决策的结果,所以这样的单元被称为“决策单 元”(Decision Maki ng Un its , DM)可以认为每个DMl都代表一定的经济含义,它的基本特点是具有一定的输入和输出,并且在将输入转换成输出的过程中,努力实现自身的决策目标。 1.2 数据包络分析法的基本模型 我们主要介绍DEA中最基本的一个模型一一C2R模型。 设有n 个决策单元((j = 1 , 2,…,n ),每个决策单元有相同的m 项投入(输入), 输入向量为 x j x 1 j, x 2 j,L T , x mj 0, j 1, 2, L , n 每个决策单元有相同的s 项产出(输出),输出向量为 y j y 1 j, y 2 j,L T , y sj0, j 1, 2, L , n sj 即每个决策单兀有m种类型的输入及s 种类型的“输出” 。 x ij 表示第j 个决策单元对第i 种类型输入的投入量; y ij 表示第j 个决策单元对第i 种类型输出的产出量;为了将所有的投入和所有的产出进行综合统一,即将这个生产过程看作是一个只有一个投入量和一个产出量的简单生产过程,我们需要对每一个输入和输出进 行赋权,设输入和输出的权向量分别为: v v1, v2 ,L , v m ,u u1 ,u2 ,L , u s 。v i 为第 i 类 型输入的权重,u r 为第r 类型输出的权重。 ms 这时,则第j 个决策单元投入的综合值为v i x ij,产出的综合值为u r y rj,我 i 1 r 1 们定义每个决策单元DMU j 的效率评价指数:
第38卷第2期1998年3月 大连理工大学学报 Journal of Dalian University of Technology Vol.38,No.2 Mar.1998数据包络分析方法综述X 郭京福, 杨德礼 (大连理工大学管理学院,大连 116024) 摘要 阐述了数据包络分析的基本原理和方法,给出这一非参数方法的几 个数学模型以及在多个领域的研究应用状况,并就该方法的发展作一展望. 关键词 线性规划/数据包络分析;决策单元;有效性 分类号 O221.1 0 概 论 数据包络分析(DEA)是美国著名运筹学家A.Charnes等人以相对效率概念为基础发展起来的一种效率评价方法〔1〕.具有单输入单输出的过程或决策单元其效率可简单的定义为:输出/输入,A.Charnes等人将这种思想推广到具有多输入多输出生产有效性分析上.对具有多输入多输出的生产过程或决策单元,其效率可类似定义为:输出项加权和/输入项加权和,形成了仅仅依靠分析生产决策单元(DM U)的投入与产出数据,来评价多输入与多输出决策单元之间相对有效性的评价体系.这种评价体系以数学规划为工具,利用观测样本点构成的“悬浮”在整个样本上的分段超平面,来评价决策单元的相对有效性. DEA是运筹学的一个新研究领域,是研究同类型生产决策单元相对有效性的有力工具. DM U确定的主导原则是,在某一视角下,各DM U具有相同的输入和输出.综合分析输入输出数据,得出每个DM U效率的相对指标,据此将所有DM U定级排队,确定相对有效的DM U,并指出其他DMU非有效的原因和程度,给主管部门提供管理决策信息. DEA在处理多输入多输出问题上具有特别的优势,主要是由于以下两个方面: 1)DEA以决策单元的输入输出权数为变量,从最有利于决策单元的角度进行评价,从而避免了确定各指标在优先意义下的权数. 2)DEA不必确定输入和输出之间可能存在的某种显式关系,这就排除了许多主观因素,因此具有很强的客观性. DEA可看作一种新的统计方法.传统的统计方法是从大量样本数据中分析出样本集合整体的一般情况,其本质是平均性;DEA则是从样本数据中分析出样本集合中处于相对有效的样本个体,其本质是最优性.DEA是致力于将有效样本与非有效样本分离的“边界”方法, X国家自然科学基金资助项目(7957009) 收稿日期:1997-01-30;修订日期:1997-10-20 郭京福:男,1965年生,博士生
决策理论与方法课程报告 数据包络分析法在管理决策运用中的实际案例分析
目录 第一章数据包络分析简介 (1) 第二章数据包络分析法模型 (1) 基础知识 (1) C2R模型 (2) 模型求解方法 (4) 第三章数据包络分析法案例 (6) 工程建设项目评标方法 (6) 环保项目评价 (7) 科研评价 (8) 第四章总结 (11) DEA方法的优点 (11) DEA方法的缺陷 (12) 参考文献 (12)
第一章数据包络分析简介 数据包络分析(Data Envelopment Analysis),简称DEA,是由美国著名运筹学家A.Charnes等人于1978年首先提出的。是使用数学规划模型评价具有多个输入、多个输出的。部门”或“单位”(称为决策单元,简记DMU)间的相对有效性(称为DEA有效)的一种非参数的统计估计方法。数学、经济学和管理科学是这一学科形成的柱石,优化是其研究的主要方法,而DEA的广泛应用是它能得以迅速发展的动力。 数据包络分析是一种基于线性规划的用于评价同类型组织(或项目)工作绩效相对有效性的特殊工具方法,常被用来衡量拥有相同目标的运营单位的相对效率。这类组织例如学校、医院、银行的分支机构、超市的各个营业部等,各自具有相同(或相近)的投入和相同的产出。衡量这类组织之间的绩效高低,通常采用投入产出比这个指标,当各自的投入产出均可折算成同一单位计量时,容易计算出各自的投入产出比并按其大小进行绩效排序。 但当被衡量的同类型组织有多项投入和多项产出,且不能折算成统一单位时,就无法算出投入产出比的数值。如运营单位有多种投入要素(员工规模、工资数目、运作时间和广告投入),同时也有多种产出要素(利润、市场份额和成长率)。在这些情况下,很难让管理者知道,当输入量转换为输出量时,哪个运营单位效率高,哪个单位效率低。 DEA方法在处理多输入,特别是多输出问题能力上具有绝对优势。 第二章数据包络分析法模型 基础知识 (1)决策单元(DMU):我们把具有相同类型的部门、企业或者同一企业不同时期的相对效率进行评价,这些部门、企业或时期称为。评价的依据是决策单元的一组投入指标数据和一组产出指标数据。 (2)投入指标:指决策单元在经济和管理活动中需要耗费的经济量,例如固定资产原值、流动资金平均余额、自筹技术开发资金、职工人数、占用土地等。
目录 摘要: (2) 关键词: (2) 1.引言 (2) 1.1研究目的 (2) 1.2研究方法和创新点 (3) 2.DEA理论的介绍以及相关模型 (3) 2.1DEA理论的基本思路 (3) 2.2DEA方法的优缺点 (5) 2.3CCR模型简介 (6) 2.4BCC模型简介 (8) 3.MALMQUIST指数介绍 (9) 4.DEA在我国农药行业公司企业效率的分析中的应用 (11) 4.1农药行业公司企业效率评价分析 (11) 4.2农药行业公司企业效率整体分析 (12) 4.3农药行业公司M ALMQUIST指数分析 (16) 5.研究结论及不足 (17) 5.1研究结论 (17) 5.2文章不足 (17) 致谢 (17) 参考文献 (18) 英文摘要 (18) 附录 (20)
数据包络分析 (DEA)的应用与研究 作者::李佳珍指导教师:王凯 (安徽农业大学理学院05级信息与计算科学学号:05119027) 摘要:随着社会经济的发展,社会资源与自然资源的利用一直是人们关注的问题,而在能源紧缺的时代,效率更是越来越受到人们的重视。在研究效率问题的现代分析方法中,数据包络分析(DEA)与Malmquist指数是比较先进和应用广泛的两种方法。本文首先对数据包络分析(DEA)的基本原理进行了简单叙述,并分析了其相对于传统的效率分析方法的优缺点,同时介绍了DEA方法中常用的两个基本模型——CCR模型和BCC模型;然后引入了Malmquist指数及其分解,详细说明了该指数与其分解指数的计算公式和含义;最后根据对部分农药行业上市公司2003—2008年度的财务数据的调查,使用DEA方法中的两个基本模型详细分析了部分农药行业上市公司的技术效率、纯技术效率和规模效率,并且利用Malmquist指数测量企业效率的动态变化,分析了部分农药行业上市公司近年来的技术进步、技术效率等指标的变化。本文不仅给出了部分农药行业上市公司的静态效率分析,同时做出了对各公司效率的动态分析和变化趋势分析。 关键词:数据包络分析; Malmquist指数;效率分析 1.引言 1.1研究目的 在管理学范围内“企业效率”不仅仅关注企业整体资源的投入产出效率,而且也关注与导致这种投入产出的各种资源的配置比率;然而在经济学中“企业效率"的概念是进入企业的资源投入量、离开企业的产品产出量和上述两个量之间比例的关系。 ------------------------------------- 作者简介:李佳珍,女,(1987- ),陕西汉中市人,汉族,2005年9月至2009年7月在安徽农业大学信息与计算科学专业学习。毕业后上研:西北工业大学。 论文完成时间:2009年6月6日